해당 포스트는 책 “골빈해커의 3분 딥러닝 텐서플로맛”의 5장 “텐서보드와 모델 재사용”을 학습하고 내용을 정리한 글입니다.
5.1 학습 모델 저장하고 재사용하기
-
포유류와 조류를 구분하는 신경망 모델을 이용
- 데이터를 CSV 파일로 분리한 뒤 해당 파일을 읽어 들여 사용하는 방법 사용
- 다음 내용을 data.csv 파일로 저장
# 털, 날개, 기타, 포유류, 조류
0, 0, 1, 0, 0
1, 0, 0, 1, 0
1, 1, 0, 0, 1
0, 0, 1, 0, 0
0, 0, 1, 0, 0
0, 1, 0, 0, 1
- 1열 ~ 2열 : 털과 날개, 즉 특징값
- 3열 ~ 5열 : 개체의 종류 (원-핫 인코딩 이용)
import tensorflow as tf
import numpy as np
5.1.1 데이터 읽어 오기
data = np.loadtxt('ch05/data.csv', delimiter=',', unpack=True, dtype='float32')
x_data = np.transpose(data[0:2])
y_data = np.transpose(data[2:])
numpy라이브러리의loadtxt함수 이용 데이터 읽어옴- 특징 데이터는 x_data로 변환하고, 개체 종류 데이터는 y_data로 변환
NOTE
loadtxt의unpack매개변수와transpose함수는 다음처럼 데이터의 구조를 변환시켜준다.
![]()
unpack매개변수와transpose함수는 읽어 들어거나 잘라낸 데이터의 행과 열을 바꿔주는 옵션과 함수이다.
5.1.2 신경망 모델 구성 - (1) 학습 횟수 카운트 변수
- 모델을 저장할 때 쓸 변수 만들기 (
global_step) - 이 변수는 학습에 직접 사용되지 않고, 학습 횟수를 카운트하는 변수
- 변수 정의 시
trainable=False옵션 사용
global_step = tf.Variable(0, trainable=False, name='global_step')
5.1.3 신경망 모델 구성 - (2) 모델 생성
X = tf.placeholder(tf.float32)
Y = tf.placeholder(tf.float32)
W1 = tf.Variable(tf.random_uniform([2, 10], -1., 1.))
L1 = tf.nn.relu(tf.matmul(X, W1))
W2 = tf.Variable(tf.random_uniform([10, 20], -1., 1.))
L2 = tf.nn.relu(tf.matmul(L1, W2))
W3 = tf.Variable(tf.random_uniform([20, 3], -1., 1.))
model = tf.matmul(L2, W3)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(labels=Y, logits=model))
optimizer = tf.train.AdamOptimizer(learning_rate=0.01)
train_op = optimizer.minimize(cost, global_step=global_step)
- W2의 형태 = [10, 20] : 앞단 계층의 출력 크기가 10이고, 뒷단 입력 크기가 20이기 때문
NOTE
- 신경망의 계층 수와 은닉층의 뉴런 수를 늘리면 복잡도가 높은 문제 해결에 도움이 된다.
-
하지만 오히려 과적합 문제에 빠질 수 있다.
train_op를 minimize 할 때 global_step 변수를 넘겨줌- 이렇게 하면 최적화 함수가 학습용 변수들을 최적화할 때마다 global_step 변수의 값을 1씩 증가시키게 된다.
5.1.4 최적화 실행
sess = tf.Session()
saver = tf.train.Saver(tf.global_variables())
tf.global_variables
- 앞서 정의한 변수들을 가져오는 함수
- 이후 이 변수들을 파일에 저장하거나 이전에 학습한 결과를 불러와 담는 변수들로 사용
5.1.5 체크 포인트 파일 (checkpoint file)
./model디렉토리에 기존에 학습해둔 모델이 있는 지 확인- 모델이 있다면 \(\rightarrow\)
saver.restore함수를 사용해 학습된 값들을 불러옴 - 모델이 없다면 \(\rightarrow\) 변수를 새로 초기화
- 체크포인트 파일 : 학습된 모델을 저장한 파일
ckpt = tf.train.get_checkpoint_state('./ch05/model')
if ckpt and tf.train.checkpoint_exists(ckpt.model_checkpoint_path):
saver.restore(sess, ckpt.model_checkpoint_path)
else:
sess.run(tf.global_variables_initializer())
5.1.6 최적화 수행
global_step값을 이용해 학습을 몇 번째 진행하고 있는 지를 출력global_step은 텐서 타입 변수, 값을 가져올 때sess.run(global_step)을 이용해야 한다.
for step in range(2) :
sess.run(train_op, feed_dict={X: x_data, Y: y_data})
print('Step: %d' % sess.run(global_step),
'Cost: %.3f' % sess.run(cost, feed_dict={X: x_data, Y: y_data}))
Step: 1 Cost: 1.024
Step: 2 Cost: 0.977
- 학습시킨 모델을 저장한 뒤 불러들여서 재학습한 결과를 보기 우해 학습 횟수를 2번으로 설정
5.1.7 학습된 변수 저장
- 최적화가 끝난 뒤 학습된 변수들을 지정한 체크포인트 파일에 저장
saver.save(sess, './ch05/model/ddn.ckpt', global_step=global_step)
'./ch05/model/ddn.ckpt-2'
- 상위 디렉토리, 즉
./ch05/model디렉토리는 미리 생성되어 있어야 한다. global_step의 값은 저장할 파일의 이름에 추가로 붙음- 텐서 변수 또는 숫자값을 넣어줄 수 있다.
- 이를 이용해 여러 상태의 체크포인트를 만들 수 있고, 가장 효과적인 체크포인트를 선별해서 사용할 수 있다.
5.1.8 예측 결과와 정확도 확인
prediction = tf.argmax(model, 1)
target = tf.argmax(Y, 1)
print('예측값: ', sess.run(prediction, feed_dict={X: x_data}))
print('실제값: ', sess.run(target, feed_dict={Y: y_data}))
is_correct = tf.equal(prediction, target)
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
print('정확도: ', sess.run(accuracy*100, feed_dict={X: x_data, Y: y_data}))
예측값: [0 1 1 0 0 2]
실제값: [0 1 2 0 0 2]
정확도: 83.33333
- 총 2번 실행
- 정확도 : 83.33%
프로그램 다시 실행
ckpt = tf.train.get_checkpoint_state('./ch05/model')
if ckpt and tf.train.checkpoint_exists(ckpt.model_checkpoint_path):
saver.restore(sess, ckpt.model_checkpoint_path)
else:
sess.run(tf.global_variables_initializer())
for step in range(2) :
sess.run(train_op, feed_dict={X: x_data, Y: y_data})
print('Step: %d' % sess.run(global_step),
'Cost: %.3f' % sess.run(cost, feed_dict={X: x_data, Y: y_data}))
saver.save(sess, './ch05/model/ddn.ckpt', global_step=global_step)
prediction = tf.argmax(model, 1)
target = tf.argmax(Y, 1)
print('예측값: ', sess.run(prediction, feed_dict={X: x_data}))
print('실제값: ', sess.run(target, feed_dict={Y: y_data}))
is_correct = tf.equal(prediction, target)
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
print('정확도: ', sess.run(accuracy*100, feed_dict={X: x_data, Y: y_data}))
INFO:tensorflow:Restoring parameters from ./ch05/model\ddn.ckpt-2
Step: 3 Cost: 0.933
Step: 4 Cost: 0.893
예측값: [0 1 2 0 0 2]
실제값: [0 1 2 0 0 2]
정확도: 100.0
global_step으로 저장한 값을 불러와 Step을 증가시킴-
정확도도 상승됨
- 텐서플로를 이용하면 학습시킨 모델을 저장하고 불러와서 재사용할 수 있다.
- 이 방식을 응용해 모델 구성, 학습, 예측 부분을 각각 분리하여 학습을 따로 한 뒤 예측만 단독하는 프로그램 작성 가능
5.1.9 전체 코드
import tensorflow as tf
import numpy as np
# 5.1.1
data = np.loadtxt('ch05/data.csv', delimiter=',', unpack=True, dtype='float32')
x_data = np.transpose(data[0:2])
y_data = np.transpose(data[2:])
##########
# 신경망 모델 구성
##########
# 5.1.2
global_step = tf.Variable(0, trainable=False, name='global_step')
# 5.1.3
X = tf.placeholder(tf.float32)
Y = tf.placeholder(tf.float32)
W1 = tf.Variable(tf.random_uniform([2, 10], -1., 1.))
L1 = tf.nn.relu(tf.matmul(X, W1))
W2 = tf.Variable(tf.random_uniform([10, 20], -1., 1.))
L2 = tf.nn.relu(tf.matmul(L1, W2))
W3 = tf.Variable(tf.random_uniform([20, 3], -1., 1.))
model = tf.matmul(L2, W3)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(labels=Y, logits=model))
optimizer = tf.train.AdamOptimizer(learning_rate=0.01)
train_op = optimizer.minimize(cost, global_step=global_step)
##########
# 신경망 모델 학습
##########
# 5.1.4
sess = tf.Session()
saver = tf.train.Saver(tf.global_variables())
# 5.1.5
ckpt = tf.train.get_checkpoint_state('./ch05/model2')
if ckpt and tf.train.checkpoint_exists(ckpt.model_checkpoint_path):
saver.restore(sess, ckpt.model_checkpoint_path)
else:
sess.run(tf.global_variables_initializer())
# 5.1.6
for step in range(2) :
sess.run(train_op, feed_dict={X: x_data, Y: y_data})
print('Step: %d' % sess.run(global_step),
'Cost: %.3f' % sess.run(cost, feed_dict={X: x_data, Y: y_data}))
# 5.1.7
saver.save(sess, './ch05/model2/ddn.ckpt', global_step=global_step)
##########
# 결과 확인
##########
# 5.1.8
prediction = tf.argmax(model, 1)
target = tf.argmax(Y, 1)
print('예측값: ', sess.run(prediction, feed_dict={X: x_data}))
print('실제값: ', sess.run(target, feed_dict={Y: y_data}))
is_correct = tf.equal(prediction, target)
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
print('정확도: ', sess.run(accuracy*100, feed_dict={X: x_data, Y: y_data}))
Step: 1 Cost: 1.293
Step: 2 Cost: 1.204
예측값: [0 2 2 0 0 1]
실제값: [0 1 2 0 0 2]
정확도: 66.66667
5.2 텐서보드 사용하기
- 딥러닝을 현업에서 활용하는 경우 학습 시간이 상당히 오래 걸린다.
- 모델을 효과적으로 실험하려면 학습 과정을 추적해야 한다.
-
텐서플로에서 제공하는 텐서보드 라는 도구는 학습하는 중간중간 손실값 이나 정확도 또는 결과물 을 다양한 방식으로 시각화해 보여준다.
- 5.1에서 학습한 코드에 텐서보드를 이용하기 위한 코드 추가
- 이를 통해 신경망 계층의 구성을 시각적으로 확인하고, 손실값 변화도 그래프를 이용해 직관적으로 확인 가능
5.2.1 데이터 불러오기 및 변수 설정
import tensorflow as tf
import numpy as np
data = np.loadtxt('./ch05/data.csv', delimiter=',', unpack=True, dtype='float32')
x_data = np.transpose(data[0:2])
y_data = np.transpose(data[2:])
global_step = tf.Variable(0, trainable=False, name='global_step')
X = tf.placeholder(tf.float32)
Y = tf.placeholder(tf.float32)
5.2.2 신경망 모델 생성
- 신경망의 각 계층에 다음 코드 추가
with tf.name_scope('layer1'):
W1 = tf.Variable(tf.random_uniform([2, 10], -1., 1.), name='W1')
L1 = tf.nn.relu(tf.matmul(X, W1))
with tf.name_scope
- 이 코드로 묶은 블록은 텐서보드에서 한 계층 내부를 표현한다.
- 변수 뒤에
name='W1'처럼 이름을 붙이면 텐서보드에서 해당 이름의 변수가 어디서 사용되는 지 확인 가능 -
이름은 변수 이외에도 플레이스홀더, 각각의 연산, 활성화 함수 등 모든 텐서에 붙일 수 있다.
- 다른 계층에도
tf.name_scope로 묶어주고 이름도 붙여준다.
with tf.name_scope('layer2'):
W2 = tf.Variable(tf.random_uniform([10, 20], -1., 1), name='W2')
L2 = tf.nn.relu(tf.matmul(L1, W2))
with tf.name_scope('layer3'):
W3 = tf.Variable(tf.random_uniform([20, 3], -1., 1), name='W3')
model = tf.nn.relu(tf.matmul(L2, W3))
5.2.3 손실값 추적 변수
- 손실값을 추적하기 위해 수집할 값을 지정하는 코드 작성
tf.summary.scalar('cost', cost)
cost텐서의 값을 손쉽게 지정tf.summary모듈의scalar함수 : 값이 하나인 텐서를 수집할 때 사용tf.summary모듈의 또 다른 함수들 :histogram,image,audio등- 자세한 내용은 텐서플로 문서의 tf.summary 부분 참조
with tf.name_scope('optimizer'):
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(labels=Y, logits=model))
optimizer = tf.train.AdamOptimizer(learning_rate=0.01)
train_op = optimizer.minimize(cost, global_step=global_step)
tf.summary.scalar('cost', cost)
5.2.4 모델 호출 및 초기화
sess = tf.Session()
saver = tf.train.Saver(tf.global_variables())
ckpt = tf.train.get_checkpoint_state('./ch05/model3')
if ckpt and tf.train_checkpoint_exists(ckpt.model_checkpoint_path):
saver.restore(sess,skpt.model_checkpoint_path)
else:
sess.run(tf.global_variables_initializer())
5.2.5 텐서 수집
tf.summary.merge_all함수로 앞서 지정한 텐서들을 수집tf.summary.FileWriter함수를 이용해 그래프와 텐서들의 값을 저장할 디렉토리 설정
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter('./ch05/logs', sess.graph)
5.2.6 최적화 실행 & 5.2.7 학습된 텐서 수집
sess.run을 이용해 앞서merged로 모아둔 텐서의 값들을 계산하여 수집writer.add_summary함수를 이용해 해당 값들을 앞서 지정한 디렉토리에 저장- 적절한 시점(여기선 매 단계)에 값들을 수집 및 저장
- 나중에 확인할 수 있도록
global_step값을 이용해 수집한 시점을 기록
# 5.2.6
for step in range(100):
sess.run(train_op, feed_dict={X: x_data, Y: y_data})
print('Step: %d' % sess.run(global_step),
'Cost: %.3f' % sess.run(cost, feed_dict={X: x_data, Y: y_data}))
# 5.2.7
summary = sess.run(merged, feed_dict={X: x_data, Y: y_data})
writer.add_summary(summary, global_step=sess.run(global_step))
Step: 1 Cost: 1.132
Step: 2 Cost: 1.096
Step: 3 Cost: 1.064
Step: 4 Cost: 1.034
Step: 5 Cost: 1.009
Step: 6 Cost: 0.996
Step: 7 Cost: 0.979
Step: 8 Cost: 0.961
Step: 9 Cost: 0.943
Step: 10 Cost: 0.925
Step: 11 Cost: 0.908
Step: 12 Cost: 0.891
Step: 13 Cost: 0.874
Step: 14 Cost: 0.858
Step: 15 Cost: 0.843
Step: 16 Cost: 0.830
Step: 17 Cost: 0.817
Step: 18 Cost: 0.804
Step: 19 Cost: 0.794
Step: 20 Cost: 0.787
Step: 21 Cost: 0.781
Step: 22 Cost: 0.775
Step: 23 Cost: 0.770
Step: 24 Cost: 0.765
Step: 25 Cost: 0.761
Step: 26 Cost: 0.757
Step: 27 Cost: 0.754
Step: 28 Cost: 0.751
Step: 29 Cost: 0.749
Step: 30 Cost: 0.747
Step: 31 Cost: 0.745
Step: 32 Cost: 0.744
Step: 33 Cost: 0.742
Step: 34 Cost: 0.741
Step: 35 Cost: 0.740
Step: 36 Cost: 0.739
Step: 37 Cost: 0.739
Step: 38 Cost: 0.738
Step: 39 Cost: 0.738
Step: 40 Cost: 0.737
Step: 41 Cost: 0.737
Step: 42 Cost: 0.736
Step: 43 Cost: 0.736
Step: 44 Cost: 0.736
Step: 45 Cost: 0.736
Step: 46 Cost: 0.735
Step: 47 Cost: 0.735
Step: 48 Cost: 0.735
Step: 49 Cost: 0.735
Step: 50 Cost: 0.735
Step: 51 Cost: 0.735
Step: 52 Cost: 0.735
Step: 53 Cost: 0.734
Step: 54 Cost: 0.734
Step: 55 Cost: 0.734
Step: 56 Cost: 0.734
Step: 57 Cost: 0.734
Step: 58 Cost: 0.734
Step: 59 Cost: 0.734
Step: 60 Cost: 0.734
Step: 61 Cost: 0.734
Step: 62 Cost: 0.734
Step: 63 Cost: 0.734
Step: 64 Cost: 0.734
Step: 65 Cost: 0.734
Step: 66 Cost: 0.734
Step: 67 Cost: 0.734
Step: 68 Cost: 0.734
Step: 69 Cost: 0.734
Step: 70 Cost: 0.734
Step: 71 Cost: 0.734
Step: 72 Cost: 0.733
Step: 73 Cost: 0.733
Step: 74 Cost: 0.733
Step: 75 Cost: 0.733
Step: 76 Cost: 0.733
Step: 77 Cost: 0.733
Step: 78 Cost: 0.733
Step: 79 Cost: 0.733
Step: 80 Cost: 0.733
Step: 81 Cost: 0.733
Step: 82 Cost: 0.733
Step: 83 Cost: 0.733
Step: 84 Cost: 0.733
Step: 85 Cost: 0.733
Step: 86 Cost: 0.733
Step: 87 Cost: 0.733
Step: 88 Cost: 0.733
Step: 89 Cost: 0.733
Step: 90 Cost: 0.733
Step: 91 Cost: 0.733
Step: 92 Cost: 0.733
Step: 93 Cost: 0.733
Step: 94 Cost: 0.733
Step: 95 Cost: 0.733
Step: 96 Cost: 0.733
Step: 97 Cost: 0.733
Step: 98 Cost: 0.733
Step: 99 Cost: 0.733
Step: 100 Cost: 0.733
5.2.8 모델 저장 및 예측
saver.save(sess, './ch05/model3/dnn.ckpt', global_step=global_step)
prediction = tf.argmax(model, 1)
target = tf.argmax(Y, 1)
print('예측값: ', sess.run(prediction, feed_dict={X: x_data}))
print('실제값: ', sess.run(target, feed_dict={Y: y_data}))
is_correct = tf.equal(prediction, target)
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
print('정확도: %.2f' % sess.run(accuracy*100, feed_dict={X: x_data, Y: y_data}))
예측값: [0 0 2 0 0 2]
실제값: [0 1 2 0 0 2]
정확도: 83.33
-
logs디렉토리 생성 확인 -
터미널(명령 프롬프트)에서 다음 명령어 입력
tensorboard --logdir=./ch05/logs
- 명령을 실행하면 다음과 같은 메시지가 출력되면서 웹서버 실행
Starting TensorBoard b'41' on port 6006
- 웹 브라우저 이용 다음 주소로 들어가면 텐서보드 내용 확인 가능
- 주소 마지막의 6006은 앞의 출력 메시지의 맨 마지막 숫자
http://localhost:6006
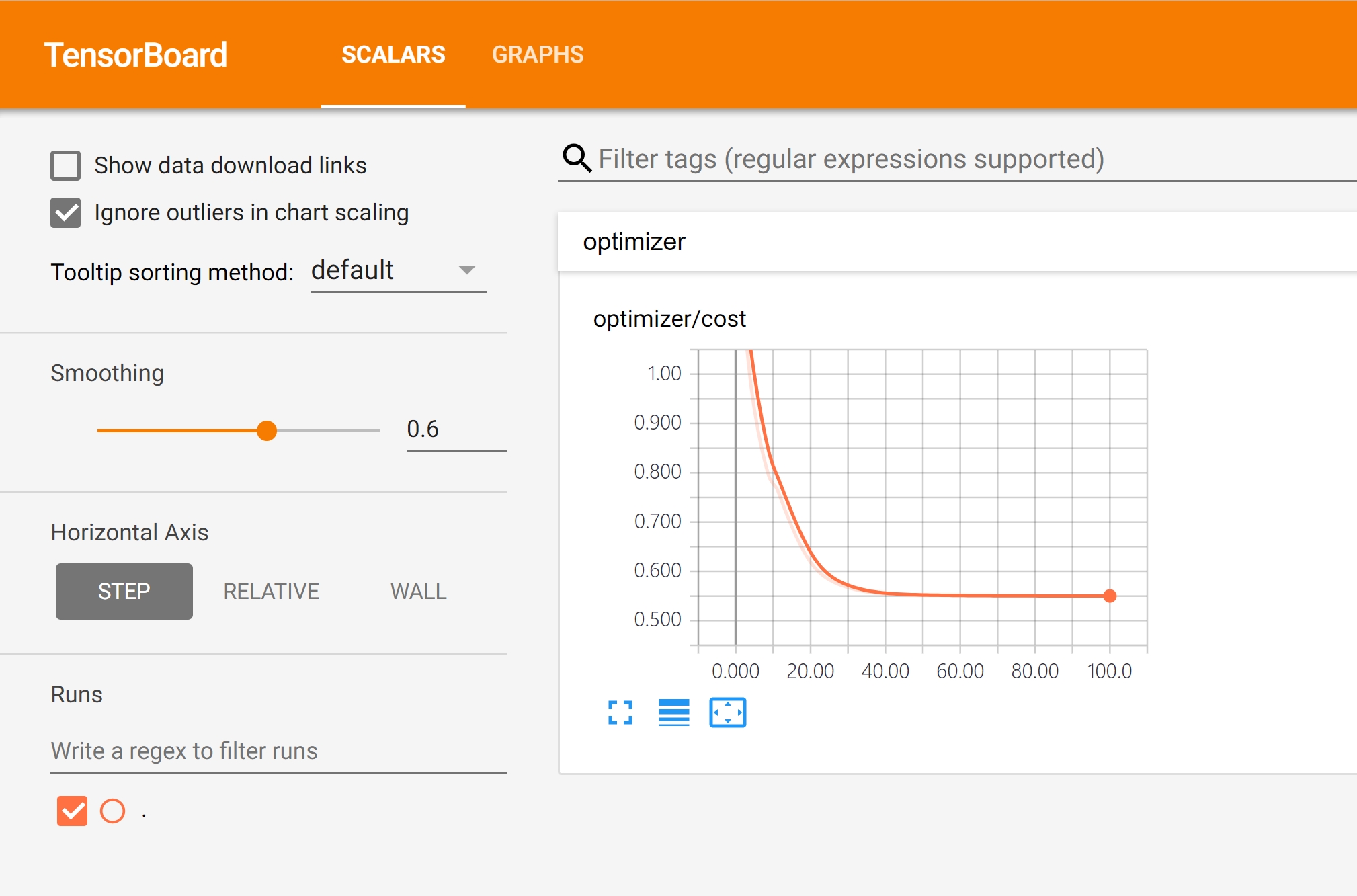
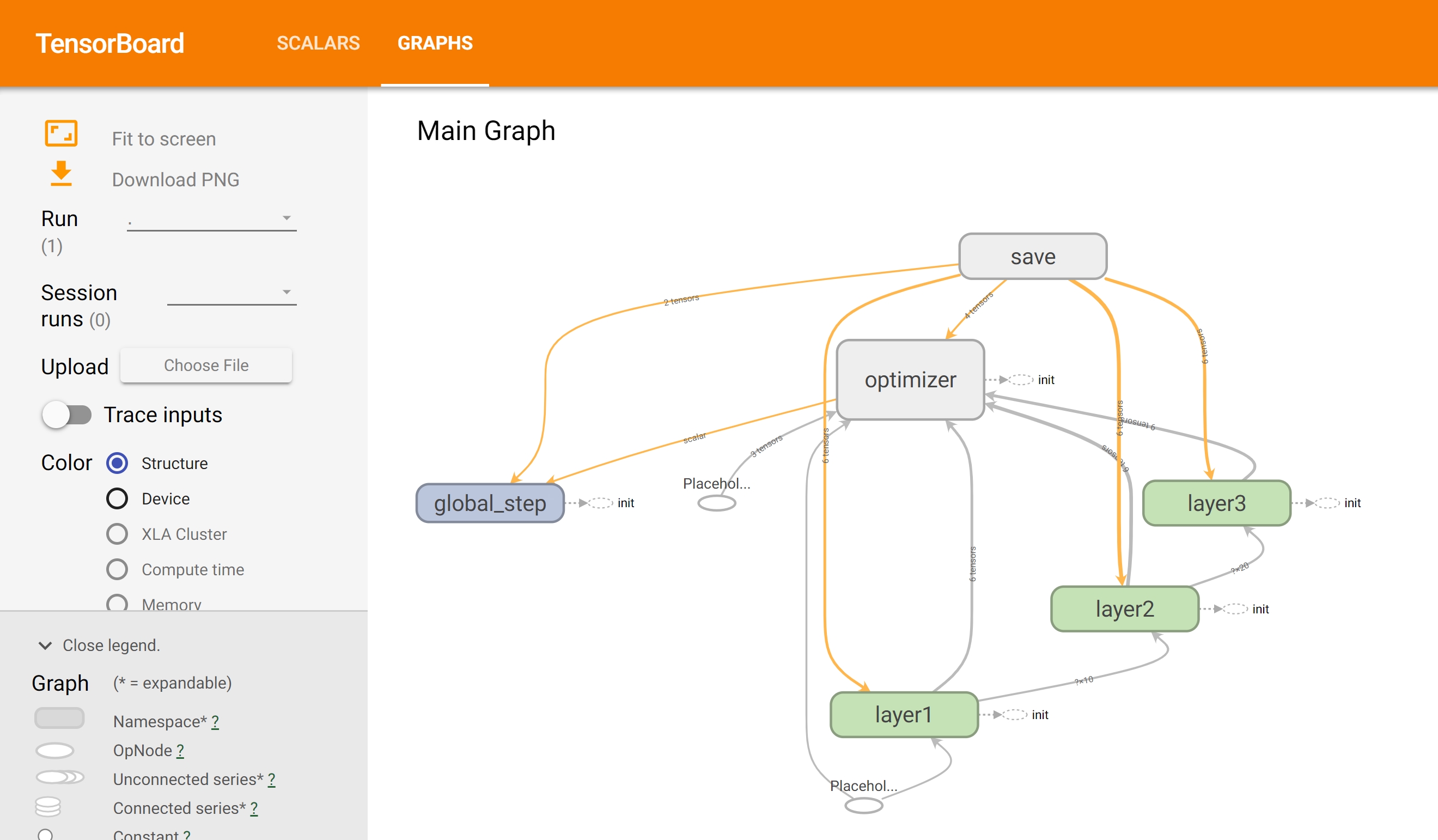
- 웹 브라우저에서 [SCALARS]와 [GRAPHS] 메뉴 들어가보기
[SCALAR] 메뉴
tf.summary.scalar('cost', cost)로 수집한 손실값의 변화를 그래프로 직관적으로 확인
[GRAPHS] 메뉴
with tf.name_scope로 그룹핑한 결과를 그림으로 확인
[DISRIBUTIONS], [HISTOGRAMS]
- 각 가중치와 편향 등의 변화를 그래프로 살펴보고 싶다면 다음 코드를 넣고 학습 진행
tf.summary.histogram("Weights", W1)
5.2.9 전체 코드
sess.close()
# 5.2.1
import tensorflow as tf
import numpy as np
data = np.loadtxt('./ch05/data.csv', delimiter=',', unpack=True, dtype='float32')
x_data = np.transpose(data[0:2])
y_data = np.transpose(data[2:])
global_step = tf.Variable(0, trainable=False, name='global_step')
X = tf.placeholder(tf.float32)
Y = tf.placeholder(tf.float32)
##########
# 신경망 모델 구성
##########
# 5.2.2
with tf.name_scope('layer1'):
W1 = tf.Variable(tf.random_uniform([2, 10], -1., 1.), name='W1')
L1 = tf.nn.relu(tf.matmul(X, W1))
with tf.name_scope('layer2'):
W2 = tf.Variable(tf.random_uniform([10, 20], -1., 1), name='W2')
L2 = tf.nn.relu(tf.matmul(L1, W2))
with tf.name_scope('layer3'):
W3 = tf.Variable(tf.random_uniform([20, 3], -1., 1), name='W3')
model = tf.nn.relu(tf.matmul(L2, W3))
with tf.name_scope('optimizer'):
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(labels=Y, logits=model))
optimizer = tf.train.AdamOptimizer(learning_rate=0.01)
train_op = optimizer.minimize(cost, global_step=global_step)
# 5.2.3
tf.summary.scalar('cost', cost)
##########
# 신경망 모델 학습
##########
# 5.2.4
sess = tf.Session()
saver = tf.train.Saver(tf.global_variables())
# 5.2.5
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter('./ch05/logs2', sess.graph)
ckpt = tf.train.get_checkpoint_state('./ch05/model4')
if ckpt and tf.train_checkpoint_exists(ckpt.model_checkpoint_path):
saver.restore(sess,skpt.model_checkpoint_path)
else:
sess.run(tf.global_variables_initializer())
# 5.2.6
for step in range(100):
sess.run(train_op, feed_dict={X: x_data, Y: y_data})
print('Step: %d' % sess.run(global_step),
'Cost: %.3f' % sess.run(cost, feed_dict={X: x_data, Y: y_data}))
# 5.2.7
summary = sess.run(merged, feed_dict={X: x_data, Y: y_data})
writer.add_summary(summary, global_step=sess.run(global_step))
# 5.2.8
saver.save(sess, './ch05/model4/dnn.ckpt', global_step=global_step)
##########
# 결과 확인
##########
prediction = tf.argmax(model, 1)
target = tf.argmax(Y, 1)
print('예측값: ', sess.run(prediction, feed_dict={X: x_data}))
print('실제값: ', sess.run(target, feed_dict={Y: y_data}))
is_correct = tf.equal(prediction, target)
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
print('정확도: %.2f' % sess.run(accuracy*100, feed_dict={X: x_data, Y: y_data}))
5.3 더 보기
- 구글에선 텐서플로로 만들고 학습시킨 모델을 실제 서비스에 적용하기 쉽게 만들어주는 서버 환경인 텐서플로 서빙(TensorFlow Serving) 을 제공
- 학습된 모델을 사용하는 프로그램을 텐서플로로 직접 만들 수도 있음
- 텐서플로 서빙은 모델을 변경하거나, 여러 모델을 한 서버에서 서비스하는 등의 편의 기능 제공
- 텐서플로 서빙 홈페이지 에서 자세한 내용 참조
댓글남기기