해당 포스트는 책 “골빈해커의 3분 딥러닝 텐서플로맛”의 6장 “헬로 딥러닝 MNIST”을 학습하고 내용을 정리한 글입니다.
MNIST
- 손으로 쓴 숫자들의 이미지를 모아놓은 데이터셋
- 0 부터 9 까지의 숫자를 28x28 픽셀 크기의 이미지로 구성
- MNIST 다운로드 링크 : MNIST 데이터셋 다운로드
6.1 MNIST 학습하기
6.1.1 텐서플로 및 MNIST 데이터셋 Import
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("./mnist/data/", one_hot=True)
Extracting ./mnist/data/train-images-idx3-ubyte.gz
Extracting ./mnist/data/train-labels-idx1-ubyte.gz
Extracting ./mnist/data/t10k-images-idx3-ubyte.gz
Extracting ./mnist/data/t10k-labels-idx1-ubyte.gz
- MNIST 데이터를 내려받고 레이블을 원-핫 인코딩 방식으로 읽어 들임
6.1.2 신경망 모델 구성
1) X와 Y 정의
- MNIST의 손그리 이미지는 28x28 픽셀로 이루어져 있음 \(\rightarrow\) 784개의 특징으로 이루어짐
- 레이블은 0부터 9까지 = 10개
X = tf.placeholder(tf.float32, [None, 784])
Y = tf.placeholder(tf.float32, [None, 10])
2) 미니배치 (mini batch)
- 데이터를 적당한 크기로 잘라서 학습시키는 것
- X와 Y를 정의한 위의 코드에서 텐서의 첫 번째 차원을
None으로 지정 - 이 자리는 한번에 학습시킬 MNIST 이미지의 개수를 지정하는 값이 들어간다.
- 즉, 배치 크기를 정하는 자리
-
배치 크기를 확실하게 명시해도 되지만, 한 번에 학습할 개수를 계속 바꿔가면서 실험해보려는 경우에는
None으로 넣어주면 텐서플로가 알아서 계산한다. - 2개의 은닉층이 다음처럼 구성된 신경망을 만든다.
784 (입력, 특징 개수)
-> 256 (첫 번째 은닉층 뉴런 개수)
-> 256 (두 번째 은닉층 뉴런 개수)
-> 10 (결과값 0~9 분류 개수)
- 위 내용을 코드로 구성
W1 = tf.Variable(tf.random_normal([784, 256], stddev=0.01))
L1 = tf.nn.relu(tf.matmul(X, W1))
W2 = tf.Variable(tf.random_normal([256, 256], stddev=0.01))
L2 = tf.nn.relu(tf.matmul(L1, W2))
W3 = tf.Variable(tf.random_normal([256, 10], stddev=0.01))
model = tf.matmul(L2, W3)
- 편향은 사용하지 않고 가중치만으로 구성
tf.random_normal([784, 256], stddev=0.01) 함수
- 표준편차가 0.01인 정규분포를 가지는 임의의 값으로 뉴런(변수)을 초기화
tf.matmul 함수
- 각 계층으로 들어오는 입력값에 각각의 가중치를 곱함
tf.nn.relu 함수
-
활성화 함수로 ReLU를 사용하는 신경망 계층 만듬
- 마지막 계층인
model텐서에 W3 변수를 곱함으로써 요소 10개짜리 배열이 출력 - 10개의 요소는 0부터 9까지의 숫자를 나타냄
- 가장 큰 값을 가진 인덱스가 예측 결과에 가까운 숫자
- 출력층에는 보통 활성화 함수를 사용하지 않는다.
6.1.3 손실값 계산 및 최적화 수행
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=model, labels=Y))
optimizer = tf.train.AdamOptimizer(0.001).minimize(cost)
tf.nn.softmax_cross_entropy_with_logits_v2 함수
- 각 이미지에 대한 손실값(실제값과 예측값의 차이)을 계산
tf.reduce_mean 함수
- 미니배치의 평균 손실값 계산
tf.train.AdamOptimizer 함수
- 이 손실값을 최소화하는 최적화를 수행하도록 그래프를 구성
6.1.4 신경망 모델 초기화
- 앞에서 구성한 신경망 모델 초기화
- 학습을 진행할 세션 시작
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
cf) 테스트용 데이터를 따로 구분하는 이유
- 머신러닝을 위한 학습 데이터 \(\rightarrow\) 학습용과 테스트용으로 분리해서 사용
- 학습 데이터 : 모델을 학습 시킬 때 사용
- 테스트 데이터 : 학습이 잘 되어있는지를 확인하는 데 사용
과적합 (Overfitting)
- 학습 데이터는 예측을 매우 잘 하지만, 실제 데이터는 그렇지 못한 상태
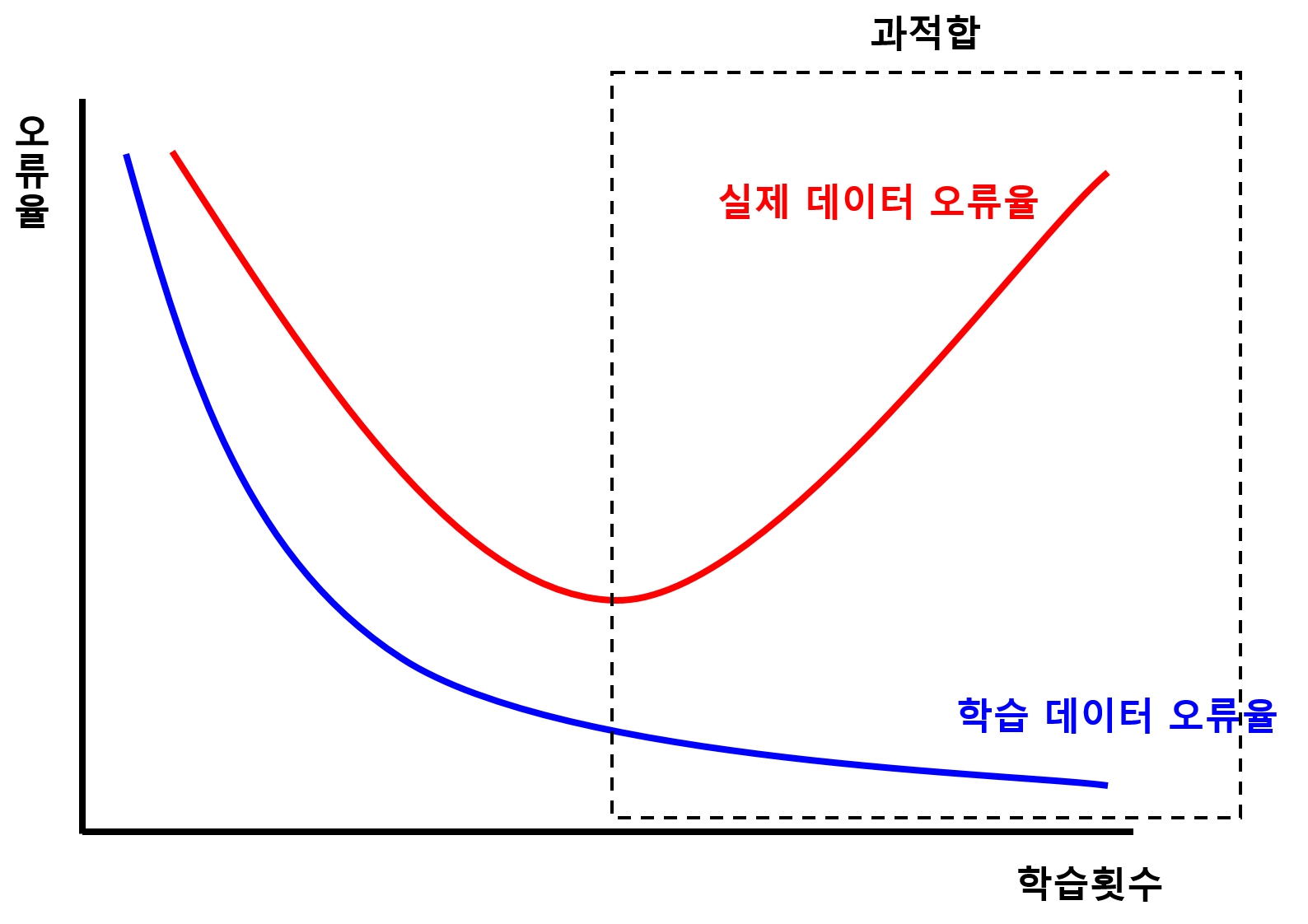
- 과적합 현상을 확인하고 방지하기 위해 학습 데이터와 테스트 데이터를 분리하고, 학습이 끝나면 테스트 데이터를 사용하여 학습 결과 검증
- MNIST 데이터셋은 학습 데이터 6만 개와 테스트 데이터 1만 개로 구성
- 텐서플로를 이용하여 MNIST 데이터셋 구분 가능
\(\rightarrow\) 학습 데이터 :mnist.train
\(\rightarrow\) 테스트 데이터 :mnist.test
6.1.5 학습 진행
batch_size = 100
total_batch = int(mnist.train.num_examples / batch_size)
- 미니배치 크기(
batch_size) 100개로 설정 - 학습 데이터의 총 개수(
mnist.train.num_examples)를 배치 크기(batch_size)로 나눠 미니 배치의 총 개수(total_batch)를 계산
에포크 (epoch)
- 학습 데이터 전체를 한 바퀴 도는 것
- 1 epoch = 학습 데이터 1번 학습 실시
-
3 epoch = 학습 데이터 13번 반복하여 학습 실시
- MNIST 데이터 전체를 학습하는 일을 총 15번 반복 (15 epoch)
for epoch in range(15):
total_cost = 0
# 1) 미니배치의 총 개수(total_batch)만큼 반복하여 학습
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
_, cost_val = sess.run([optimizer, cost], feed_dict={X: batch_xs, Y: batch_ys})
# 2) 손실값 저장
total_cost += cost_val
# 3) 평균 손실값 계산
print('Epoch:', '%04d' % (epoch+1),
'Avg. Cost = ', '{:.3f}'.format(total_cost / total_batch))
print('최적화 완료!')
Epoch: 0001 Avg. Cost = 0.403
Epoch: 0002 Avg. Cost = 0.147
Epoch: 0003 Avg. Cost = 0.095
Epoch: 0004 Avg. Cost = 0.069
Epoch: 0005 Avg. Cost = 0.053
Epoch: 0006 Avg. Cost = 0.040
Epoch: 0007 Avg. Cost = 0.032
Epoch: 0008 Avg. Cost = 0.027
Epoch: 0009 Avg. Cost = 0.021
Epoch: 0010 Avg. Cost = 0.017
Epoch: 0011 Avg. Cost = 0.017
Epoch: 0012 Avg. Cost = 0.014
Epoch: 0013 Avg. Cost = 0.016
Epoch: 0014 Avg. Cost = 0.012
Epoch: 0015 Avg. Cost = 0.009
최적화 완료!
1) 미니배치의 총 개수(total_batch) 만큼 반복 학습
mnist.train.next_batch(batch_size) 함수
- 학습할 데이터를 배치 크기(
batch_size)만큼 가져옴 - 이미지 데이터(입력값) :
batch_xs에 저장 - 레이블 데이터(출력값) :
batch_ys에 저장
sess.run()
optimizer를 실행하여 최적화cost를 실행하여 손실값 획득
2) 손실값 저장
- 미니배치의 총 개수(
total_batch)만큼 학습을 할 때마다 획득하는 손실값(cost_val)을total_cost변수에 누적
3) 평균 손실값 계산
- 학습 데이터 전체가 학습이 끝날때 마다 (1 epoch 마다)
total_cost를 학습 데이터 전체 갯수(total_batch)로 나눠 평균 손실값 계산하여 출력
6.1.6 학습 결과 확인
- 예측 결과인
model의 값과 실제 레이블인 Y의 값 비교
print(sess.run(model, feed_dict={X: mnist.test.images, Y: mnist.test.labels})[0])
[-11.691506 -4.8739653 -1.8754562 -2.2004135 -20.994165 -11.796983
-35.915874 16.188215 -6.3973737 -4.808543 ]
- 예측한 결과값은 원-핫 인코딩 형식
- 각 인덱스에 해당하는 값은 해당 숫자가 얼마나 해당 인덱스와 관련이 높은가를 나타냄
- index=7 에 해당하는 예측 결과값이 16.188215로 가장 크므로 index=7에 해당하는 레이블, 즉 숫자 8로 모델은 결과를 예측했다.
(단, 이것은 손실값을sfotmax_cross_entropy_entropy_with_logits_v2를 이용해서 구했기 때문이다. 초기값이나 예측 모델, 손실값을 구하는 방식 등에 따라 결과가 달라질 수 있음)
is_correct = tf.equal(tf.argmax(model, 1), tf.argmax(Y, 1))
tf.argmax(model, 1)
- 두 번째 차원(1번 인덱스의 차원)의 값 중 최댓값의 인덱스를 뽑아내는 함수
model로 출력한 결과는[None, 10]처럼 결괏값을 배치 크기만큼 가지고 있음- 따라서 두 번째 차원이 예측한 각각의 결과
tf.argmax 함수
- 앞의 원-핫 인코딩 형식으로 된 예측값에서 가장 큰 값의 인덱스를 뽑아냄 (그 값은 7)
- 그 값이 바로 예측 결과이다.
tf.argmax(Y, 1)
- 실제 레이블에 해당하는 숫자를 가져옴
tf.equal 함수
- 예측한 숫자와 실제 숫자가 같은 지 확인
6.1.7 정확도 계산
tf.cast
is_correct를 0과 1로 변환- 변환한 값들을
tf.reduce_mean을 이용해 평균 값 계산 - 이 값이 바로 정확도(확률) 이 됨
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
mnist.test를 이용하여 테스트 이미지와 레이블 데이터를 넣어 정확도 계산
print('정확도: ', sess.run(accuracy, feed_dict={X: mnist.test.images, Y: mnist.test.labels}))
정확도: 0.9799
6.1.8 전체 코드
# 6.1.1
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("./mnist/data/", one_hot=True)
##########
# 신경망 모델 구성
##########
# 6.1.2
X = tf.placeholder(tf.float32, [None, 784])
Y = tf.placeholder(tf.float32, [None, 10])
W1 = tf.Variable(tf.random_normal([784, 256], stddev=0.01))
L1 = tf.nn.relu(tf.matmul(X, W1))
W2 = tf.Variable(tf.random_normal([256, 256], stddev=0.01))
L2 = tf.nn.relu(tf.matmul(L1, W2))
W3 = tf.Variable(tf.random_normal([256, 10], stddev=0.01))
model = tf.matmul(L2, W3)
# 6.1.3
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=model, labels=Y))
optimizer = tf.train.AdamOptimizer(0.001).minimize(cost)
##########
# 신경망 모델 학습
##########
# 6.1.4
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
# 6.1.5
batch_size = 100
total_batch = int(mnist.train.num_examples / batch_size)
for epoch in range(15):
total_cost = 0
# 1) 미니배치의 총 개수(total_batch)만큼 반복하여 학습
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
_, cost_val = sess.run([optimizer, cost], feed_dict={X: batch_xs, Y: batch_ys})
# 2) 손실값 저장
total_cost += cost_val
# 3) 평균 손실값 계산
print('Epoch:', '%04d' % (epoch+1),
'Avg. Cost = ', '{:.3f}'.format(total_cost / total_batch))
print('최적화 완료!')
##########
# 결과 확인
##########
# 6.1.6
is_correct = tf.equal(tf.argmax(model, 1), tf.argmax(Y, 1))
# 6.1.7
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
print('정확도: ', sess.run(accuracy, feed_dict={X: mnist.test.images, Y: mnist.test.labels}))
Extracting ./mnist/data/train-images-idx3-ubyte.gz
Extracting ./mnist/data/train-labels-idx1-ubyte.gz
Extracting ./mnist/data/t10k-images-idx3-ubyte.gz
Extracting ./mnist/data/t10k-labels-idx1-ubyte.gz
Epoch: 0001 Avg. Cost = 0.405
Epoch: 0002 Avg. Cost = 0.151
Epoch: 0003 Avg. Cost = 0.098
Epoch: 0004 Avg. Cost = 0.071
Epoch: 0005 Avg. Cost = 0.055
Epoch: 0006 Avg. Cost = 0.040
Epoch: 0007 Avg. Cost = 0.032
Epoch: 0008 Avg. Cost = 0.028
Epoch: 0009 Avg. Cost = 0.021
Epoch: 0010 Avg. Cost = 0.017
Epoch: 0011 Avg. Cost = 0.015
Epoch: 0012 Avg. Cost = 0.017
Epoch: 0013 Avg. Cost = 0.011
Epoch: 0014 Avg. Cost = 0.011
Epoch: 0015 Avg. Cost = 0.012
최적화 완료!
정확도: 0.9798
6.2 드롭아웃
과적합(Overfitting)
- 학습한 결과가 학습 데이터에는 매우 잘 맞지만, 학습 데이터에만 너무 꼭 맞춰져 있어서 그 외의 데이터에는 잘 맞지 않는 상황
드롭아웃(Dropout)
- 과적합 문제를 해결하기 위한 방법 중 가장 효과가 좋은 방법
- 학습 시 전체 신경망 중 일부만을 사용하도록 한다.
- 학습 단계마다 일부 뉴런을 제거(사용하지 않도록)함으로써 일부 특징이 특정 뉴런들에 고정되는 것을 막음
- 이렇게 해서 가중치의 균형을 잡도록 하여 과적합을 방지
- 다만, 학습 시 일부 뉴런을 학습시키지 않기 때문에 신경망이 충분히 학습되기까지의 시간은 조금 오래 걸림
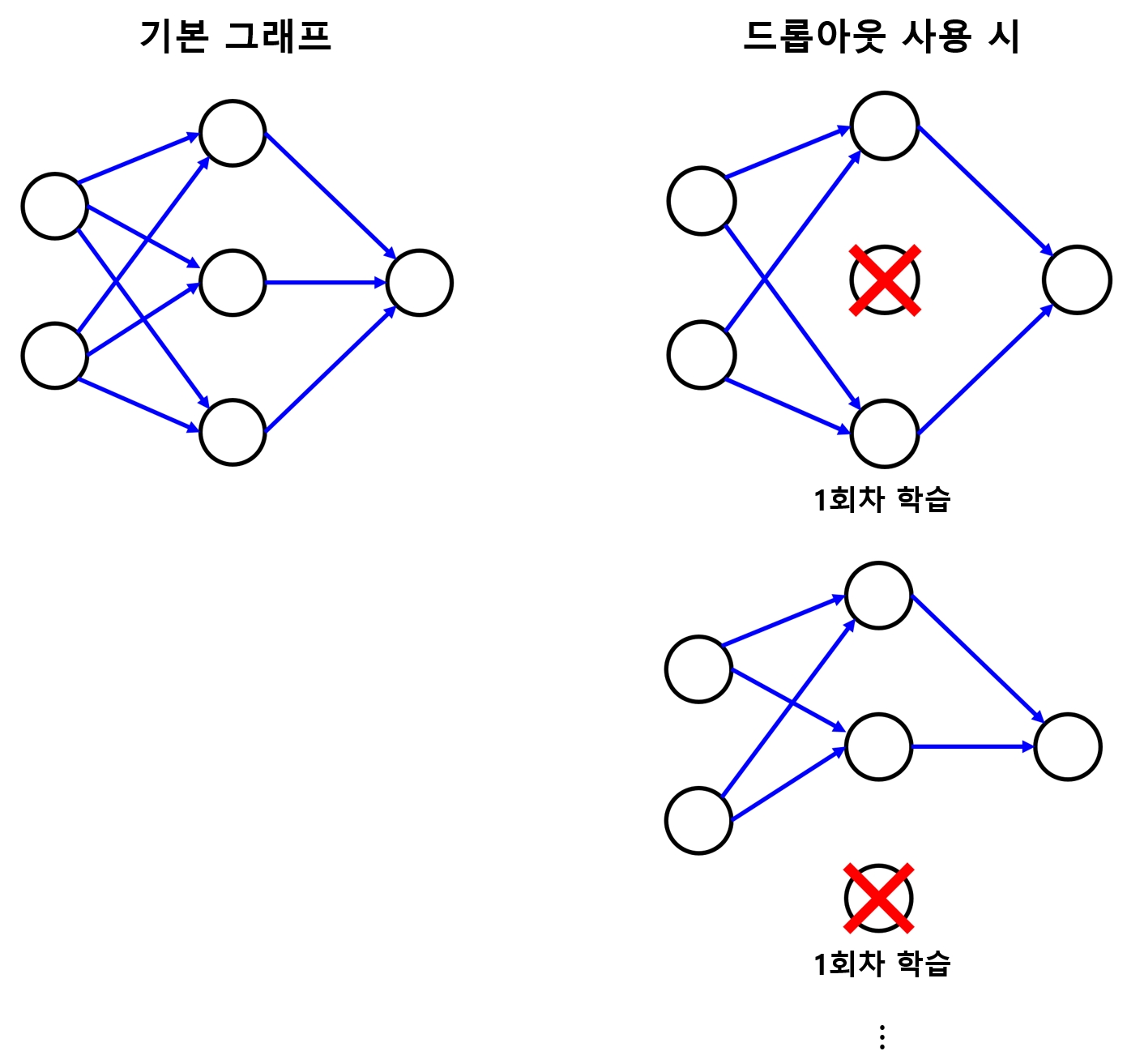
- 손슬씨 인식 모델에 드롭아웃 기법을 적용해본다.
- 드롭아웃 역시 텐서플로가 기본으로 지원한다.
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("./mnist/data/", one_hot=True)
Extracting ./mnist/data/train-images-idx3-ubyte.gz
Extracting ./mnist/data/train-labels-idx1-ubyte.gz
Extracting ./mnist/data/t10k-images-idx3-ubyte.gz
Extracting ./mnist/data/t10k-labels-idx1-ubyte.gz
X = tf.placeholder(tf.float32, [None, 784])
Y = tf.placeholder(tf.float32, [None, 10])
6.2.1 tf.nn.dropout
keep_prob = tf.placeholder(tf.float32)
W1 = tf.Variable(tf.random_normal([784, 256], stddev=0.01))
L1 = tf.nn.relu(tf.matmul(X, W1))
L1 = tf.nn.dropout(L1, keep_prob) # 6.2.1
W2 = tf.Variable(tf.random_normal([256, 256], stddev=0.01))
L2 = tf.nn.relu(tf.matmul(L1, W2))
L2 = tf.nn.dropout(L2, keep_prob) # 6.2.1
- 계층 구성 의 마지막에
tf.nn.dropout함수를 사용하기만 하면 된다. - 함수의 두번째 매개변수(
keep_prob)는 사용한 뉴런의 비율이다. - 이 값이 0.8이면 학습 시 해당 계층의 약 80% 뉴런만 사용하겠다는 의미이다.
6.2.2 keep_prob
- 드롭아웃 기법 사용 시 주의할 점은 학습이 끝난 뒤 예측을 할 때는 신경망 전체를 사용하도록 해줘야 한다는 점이다.
- 그렇기 때문에
keep_prob라는 플레이스홀더를 만들어, 학습 시에는 0.8을 넣어 드롭아웃을 사용하고, 예측 시에는 1을 넣어 신경망 전체를 사용하도록 만드는 것이다.
W3 = tf.Variable(tf.random_normal([256, 10], stddev=0.01))
model = tf.matmul(L2, W3)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=model, labels=Y))
optimizer = tf.train.AdamOptimizer(0.001).minimize(cost)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
6.2.3 epoch 크기 조정
- 드롭아웃 기법을 적용한 뒤 학습을 진행해보면, 적용하지 않았을 떄와 별 차이가 없다.
- 그 이유는 드롭아웃을 사용하면 학습이 느리게 진행되기 때문이다.
- 그렇기 때문에 학습 세대(
epoch)를 30번 으로 늘려 조금 더 많이 학습을 실시한다.
batch_size = 100
total_batch = int(mnist.train.num_examples / batch_size)
for epoch in range(30): # 6.2.3
total_cost = 0
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
# 6.2.2 -> 학습 코드 : keep_prob를 0.8로 넣어 준다.
_, cost_val = sess.run([optimizer, cost], feed_dict={X: batch_xs, Y: batch_ys, keep_prob: 0.8})
total_cost += cost_val
print('Epoch: ', '%04d' % (epoch+1),
'Avg. Cost = ', '{:.3f}'.format(total_cost/total_batch))
print("최적화 완료")
Epoch: 0001 Avg. Cost = 0.163
Epoch: 0002 Avg. Cost = 0.113
Epoch: 0003 Avg. Cost = 0.089
Epoch: 0004 Avg. Cost = 0.073
Epoch: 0005 Avg. Cost = 0.061
Epoch: 0006 Avg. Cost = 0.053
Epoch: 0007 Avg. Cost = 0.046
Epoch: 0008 Avg. Cost = 0.040
Epoch: 0009 Avg. Cost = 0.038
Epoch: 0010 Avg. Cost = 0.033
Epoch: 0011 Avg. Cost = 0.032
Epoch: 0012 Avg. Cost = 0.030
Epoch: 0013 Avg. Cost = 0.027
Epoch: 0014 Avg. Cost = 0.025
Epoch: 0015 Avg. Cost = 0.025
Epoch: 0016 Avg. Cost = 0.025
Epoch: 0017 Avg. Cost = 0.024
Epoch: 0018 Avg. Cost = 0.020
Epoch: 0019 Avg. Cost = 0.021
Epoch: 0020 Avg. Cost = 0.019
Epoch: 0021 Avg. Cost = 0.020
Epoch: 0022 Avg. Cost = 0.020
Epoch: 0023 Avg. Cost = 0.018
Epoch: 0024 Avg. Cost = 0.017
Epoch: 0025 Avg. Cost = 0.015
Epoch: 0026 Avg. Cost = 0.017
Epoch: 0027 Avg. Cost = 0.019
Epoch: 0028 Avg. Cost = 0.016
Epoch: 0029 Avg. Cost = 0.016
Epoch: 0030 Avg. Cost = 0.013
최적화 완료
is_correct = tf.equal(tf.argmax(model, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
# 6.2.2 -> 예측 코드 : keep_prob를 1로 넣어준다.
print('정확도: ', sess.run(accuracy, feed_dict={X: mnist.test.images, Y: mnist.test.labels, keep_prob: 1}))
정확도: 0.9825
- 드롭아웃을 사용하지 않은 모델의 정확도 = 0.9799
- 드롭아웃을 사용한 모델의 정확도 = 0.9825
- 드롭아웃을 사용하지 않은 모델의 학습세대를 30으로 늘리면(epoch=30), 과적합으로 인해 오히려 정확도가 낮아지게 된다.
배치 정규화 (Batch Normalization)
- 과적합을 막아주는 또 다른 기법
- 최근에 많이 사용되는 기법이다.
- 이 기법은 과적합을 막아줄 뿐만 아니라 학습 속도도 향상시켜 주는 장점이 있다.
-
원래 과적합 문제보단 학습 시 발산이나 소실 등을 방지하여 학습 속도를 높이기 위해 발명된 기법
- 텐서플로에서
tf.nn.batch_normalization과tf.layers.batch_normalization함수로 쉽게 적용 가능 - 특히, 텐서플로의 고수준 API인
tf.layers라이브러리를 이용하면 다음처럼 매우 간단하게 적용할 수 있다.
tf.layers.batch_normalization(L1, training=is_training)
- 모델에 따라 과적합 방지에 효과적인 기법의 종류가 다를 수 있다.
6.2.4 전체 코드
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("./mnist/data/", one_hot=True)
##########
# 신경망 모델 구성
##########
X = tf.placeholder(tf.float32, [None, 784])
Y = tf.placeholder(tf.float32, [None, 10])
# 6.2.2
keep_prob = tf.placeholder(tf.float32)
W1 = tf.Variable(tf.random_normal([784, 256], stddev=0.01))
L1 = tf.nn.relu(tf.matmul(X, W1))
# 6.2.1
L1 = tf.nn.dropout(L1, keep_prob)
W2 = tf.Variable(tf.random_normal([256, 256], stddev=0.01))
L2 = tf.nn.relu(tf.matmul(L1, W2))
# 6.2.1
L2 = tf.nn.dropout(L2, keep_prob)
W3 = tf.Variable(tf.random_normal([256, 10], stddev=0.01))
model = tf.matmul(L2, W3)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=model, labels=Y))
optimizer = tf.train.AdamOptimizer(0.001).minimize(cost)
##########
# 신경망 모델 학습
##########
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
batch_size = 100
total_batch = int(mnist.train.num_examples / batch_size)
# 6.2.3
for epoch in range(30):
total_cost = 0
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
# 6.2.2 -> 학습 코드 : keep_prob를 0.8로 넣어 준다.
_, cost_val = sess.run([optimizer, cost], feed_dict={X: batch_xs, Y: batch_ys, keep_prob: 0.8})
total_cost += cost_val
print('Epoch: ', '%04d' % (epoch+1),
'Avg. Cost = ', '{:.3f}'.format(total_cost/total_batch))
print("최적화 완료")
##########
# 결과 확인
##########
is_correct = tf.equal(tf.argmax(model, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
# 6.2.2 -> 예측 코드 : keep_prob를 1로 넣어준다.
print('정확도: ', sess.run(accuracy, feed_dict={X: mnist.test.images, Y: mnist.test.labels, keep_prob: 1}))
Extracting ./mnist/data/train-images-idx3-ubyte.gz
Extracting ./mnist/data/train-labels-idx1-ubyte.gz
Extracting ./mnist/data/t10k-images-idx3-ubyte.gz
Extracting ./mnist/data/t10k-labels-idx1-ubyte.gz
Epoch: 0001 Avg. Cost = 0.424
Epoch: 0002 Avg. Cost = 0.160
Epoch: 0003 Avg. Cost = 0.112
Epoch: 0004 Avg. Cost = 0.087
Epoch: 0005 Avg. Cost = 0.072
Epoch: 0006 Avg. Cost = 0.062
Epoch: 0007 Avg. Cost = 0.051
Epoch: 0008 Avg. Cost = 0.046
Epoch: 0009 Avg. Cost = 0.043
Epoch: 0010 Avg. Cost = 0.037
Epoch: 0011 Avg. Cost = 0.034
Epoch: 0012 Avg. Cost = 0.031
Epoch: 0013 Avg. Cost = 0.028
Epoch: 0014 Avg. Cost = 0.027
Epoch: 0015 Avg. Cost = 0.023
Epoch: 0016 Avg. Cost = 0.023
Epoch: 0017 Avg. Cost = 0.022
Epoch: 0018 Avg. Cost = 0.023
Epoch: 0019 Avg. Cost = 0.022
Epoch: 0020 Avg. Cost = 0.018
Epoch: 0021 Avg. Cost = 0.022
Epoch: 0022 Avg. Cost = 0.018
Epoch: 0023 Avg. Cost = 0.019
Epoch: 0024 Avg. Cost = 0.019
Epoch: 0025 Avg. Cost = 0.016
Epoch: 0026 Avg. Cost = 0.015
Epoch: 0027 Avg. Cost = 0.018
Epoch: 0028 Avg. Cost = 0.016
Epoch: 0029 Avg. Cost = 0.015
Epoch: 0030 Avg. Cost = 0.014
최적화 완료
정확도: 0.9826
6.3 matplotlib
matplotlib
- 시각화를 위해 그래프를 쉽게 그릴 수 있도록 해주는 파이썬 라이브러리
matplotlib를 이용하여 학습 결과를 손글씨 이미지로 확인하는 간단한 예제를 살펴본다.
import tensorflow as tf
import numpy as np
6.3.1 matplotlib의 pyplot 모듈 Import
import matplotlib.pyplot as plt
%matplotlib inline
%matplotlib inline은 그래프가 새 창으로 열리지 않고 노트북 안에 그려지도록 지정하는 코드이다.
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("./mnist/data/", one_hot=True)
Extracting ./mnist/data/train-images-idx3-ubyte.gz
Extracting ./mnist/data/train-labels-idx1-ubyte.gz
Extracting ./mnist/data/t10k-images-idx3-ubyte.gz
Extracting ./mnist/data/t10k-labels-idx1-ubyte.gz
X = tf.placeholder(tf.float32, [None, 784])
Y = tf.placeholder(tf.float32, [None, 10])
keep_prob = tf.placeholder(tf.float32)
W1 = tf.Variable(tf.random_normal([784, 256], stddev=0.01))
L1 = tf.nn.relu(tf.matmul(X, W1))
L1 = tf.nn.dropout(L1, keep_prob)
W2 = tf.Variable(tf.random_normal([256, 256], stddev=0.01))
L2 = tf.nn.relu(tf.matmul(L1, W2))
L2 = tf.nn.dropout(L2, keep_prob)
W3 = tf.Variable(tf.random_normal([256, 10], stddev=0.01))
model = tf.matmul(L2, W3)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=model, labels=Y))
optimizer = tf.train.AdamOptimizer(0.001).minimize(cost)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
batch_size = 100
total_batch = int(mnist.train.num_examples / batch_size)
for epoch in range(30):
total_cost = 0
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
_, cost_val = sess.run([optimizer, cost], feed_dict={X: batch_xs, Y: batch_ys, keep_prob: 0.8})
total_cost += cost_val
print('Epoch: ', '%04d' % (epoch + 1),
'Avg. Cost = ', '{:.3f}'.format(total_cost / total_batch))
print('최적화 완료!')
Epoch: 0001 Avg. Cost = 0.426
Epoch: 0002 Avg. Cost = 0.164
Epoch: 0003 Avg. Cost = 0.113
Epoch: 0004 Avg. Cost = 0.088
Epoch: 0005 Avg. Cost = 0.071
Epoch: 0006 Avg. Cost = 0.060
Epoch: 0007 Avg. Cost = 0.053
Epoch: 0008 Avg. Cost = 0.045
Epoch: 0009 Avg. Cost = 0.041
Epoch: 0010 Avg. Cost = 0.038
Epoch: 0011 Avg. Cost = 0.034
Epoch: 0012 Avg. Cost = 0.031
Epoch: 0013 Avg. Cost = 0.030
Epoch: 0014 Avg. Cost = 0.027
Epoch: 0015 Avg. Cost = 0.025
Epoch: 0016 Avg. Cost = 0.026
Epoch: 0017 Avg. Cost = 0.022
Epoch: 0018 Avg. Cost = 0.020
Epoch: 0019 Avg. Cost = 0.023
Epoch: 0020 Avg. Cost = 0.019
Epoch: 0021 Avg. Cost = 0.020
Epoch: 0022 Avg. Cost = 0.019
Epoch: 0023 Avg. Cost = 0.017
Epoch: 0024 Avg. Cost = 0.017
Epoch: 0025 Avg. Cost = 0.019
Epoch: 0026 Avg. Cost = 0.015
Epoch: 0027 Avg. Cost = 0.017
Epoch: 0028 Avg. Cost = 0.016
Epoch: 0029 Avg. Cost = 0.016
Epoch: 0030 Avg. Cost = 0.015
최적화 완료!
is_correct = tf.equal(tf.argmax(model, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
print('정확도: ', sess.run(accuracy, feed_dict={X: mnist.test.images, Y: mnist.test.labels, keep_prob: 1}))
정확도: 0.9847
6.3.2 예측 모델 실행 및 결괏값 저장
- 테스트 데이터를 이용해 예측 모델을 실행
- 결과값을
labels에 저장
labels = sess.run(model, feed_dict={X: mnist.test.images, Y: mnist.test.labels, keep_prob: 1})
labels
array([[-13.151234 , -12.016206 , -5.8739185, ..., 17.770342 ,
-13.4524975, -2.1160414],
[-20.371695 , 1.9777021, 17.857597 , ..., -18.572105 ,
-17.603155 , -27.702919 ],
[-21.889305 , 15.491379 , -5.9568987, ..., -2.7099974,
-2.729644 , -19.049625 ],
...,
[-20.320854 , -16.977238 , -16.656517 , ..., -12.006784 ,
-5.534915 , -1.4176488],
[-19.643621 , -23.225227 , -23.540749 , ..., -27.392267 ,
4.577215 , -28.028595 ],
[-13.773045 , -17.91676 , -16.14539 , ..., -42.442455 ,
-15.203808 , -22.238316 ]], dtype=float32)
6.3.3 그래프 출력 준비
- 손글씨를 출력할 그래프를 준비
6.3.4 테스트 데이터 이미지 및 예측값 출력
- 테스트 데이터의 첫 번째부터 열 번째까지의 이미지와 예측한 값을 출력
6.3.5 그래프를 화면에 표시
# 6.3.3
fig = plt.figure()
# 6.3.4
for i in range(10):
# 2행 5열의 그래프 생성 후 i+1 번째에 숫자 이미지를 출력
subplot = fig.add_subplot(2, 5, i+1)
# 이미지를 깨끗하게 출력하기 위해 x와 y의 눈금을 출력하지 않음
subplot.set_xticks([])
subplot.set_yticks([])
# 출력한 이미지 위에 예측한 숫자를 출력
# np.argmax는 tf.argmax와 같은 기능인 함수
# 결과값인 labels의 i번째 요소가 원-핫 인코딩 형식을 되어 있음
# 해당 배열에서 가장 높은 값을 가진 인덱스를 예측한 숫자로 출력
subplot.set_title('%d' % np.argmax(labels[i]))
# 1차원 배열로 되어 있는 i번째 이미지 데이터를 28x28 형식의 2차원 배열로 변형하여 이미지 형태로 출력
# cmap 파라미터를 통해 이미지를 그레이스케일로 출력
subplot.imshow(mnist.test.images[i].reshape((28,28)), cmap=plt.cm.gray_r)
# 6.3.5
plt.show()
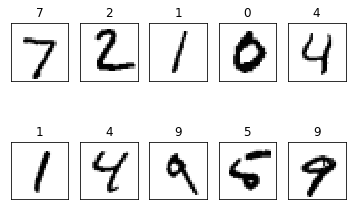
6.3.6 전체 코드
import tensorflow as tf
import numpy as np
# 6.3.1
import matplotlib.pyplot as plt
%matplotlib inline
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("./mnist/data/", one_hot=True)
##########
# 신경망 모델 구성
##########
X = tf.placeholder(tf.float32, [None, 784])
Y = tf.placeholder(tf.float32, [None, 10])
keep_prob = tf.placeholder(tf.float32)
W1 = tf.Variable(tf.random_normal([784, 256], stddev=0.01))
L1 = tf.nn.relu(tf.matmul(X, W1))
L1 = tf.nn.dropout(L1, keep_prob)
W2 = tf.Variable(tf.random_normal([256, 256], stddev=0.01))
L2 = tf.nn.relu(tf.matmul(L1, W2))
L2 = tf.nn.dropout(L2, keep_prob)
W3 = tf.Variable(tf.random_normal([256, 10], stddev=0.01))
model = tf.matmul(L2, W3)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=model, labels=Y))
optimizer = tf.train.AdamOptimizer(0.001).minimize(cost)
##########
# 신경망 모델 학습
##########
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
batch_size = 100
total_batch = int(mnist.train.num_examples / batch_size)
for epoch in range(30):
total_cost = 0
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
_, cost_val = sess.run([optimizer, cost], feed_dict={X: batch_xs, Y: batch_ys, keep_prob: 0.8})
total_cost += cost_val
print('Epoch: ', '%04d' % (epoch + 1),
'Avg. Cost = ', '{:.3f}'.format(total_cost / total_batch))
print('최적화 완료!')
##########
# 결과 확인
##########
is_correct = tf.equal(tf.argmax(model, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
print('정확도: ', sess.run(accuracy, feed_dict={X: mnist.test.images, Y: mnist.test.labels, keep_prob: 1}))
##########
# 결과 확인 (matplotlib)
##########
# 6.3.2
labels = sess.run(model, feed_dict={X: mnist.test.images, Y: mnist.test.labels, keep_prob: 1})
# 6.3.3
fig = plt.figure()
# 6.3.4
for i in range(10):
# 2행 5열의 그래프 생성 후 i+1 번째에 숫자 이미지를 출력
subplot = fig.add_subplot(2, 5, i+1)
# 이미지를 깨끗하게 출력하기 위해 x와 y의 눈금을 출력하지 않음
subplot.set_xticks([])
subplot.set_yticks([])
# 출력한 이미지 위에 예측한 숫자를 출력
# np.argmax는 tf.argmax와 같은 기능인 함수
# 결과값인 labels의 i번째 요소가 원-핫 인코딩 형식을 되어 있음
# 해당 배열에서 가장 높은 값을 가진 인덱스를 예측한 숫자로 출력
subplot.set_title('%d' % np.argmax(labels[i]))
# 1차원 배열로 되어 있는 i번째 이미지 데이터를 28x28 형식의 2차원 배열로 변형하여 이미지 형태로 출력
# cmap 파라미터를 통해 이미지를 그레이스케일로 출력
subplot.imshow(mnist.test.images[i].reshape((28,28)), cmap=plt.cm.gray_r)
# 6.3.5
plt.show()
Extracting ./mnist/data/train-images-idx3-ubyte.gz
Extracting ./mnist/data/train-labels-idx1-ubyte.gz
Extracting ./mnist/data/t10k-images-idx3-ubyte.gz
Extracting ./mnist/data/t10k-labels-idx1-ubyte.gz
Epoch: 0001 Avg. Cost = 0.430
Epoch: 0002 Avg. Cost = 0.168
Epoch: 0003 Avg. Cost = 0.115
Epoch: 0004 Avg. Cost = 0.089
Epoch: 0005 Avg. Cost = 0.073
Epoch: 0006 Avg. Cost = 0.060
Epoch: 0007 Avg. Cost = 0.054
Epoch: 0008 Avg. Cost = 0.046
Epoch: 0009 Avg. Cost = 0.041
Epoch: 0010 Avg. Cost = 0.036
Epoch: 0011 Avg. Cost = 0.034
Epoch: 0012 Avg. Cost = 0.031
Epoch: 0013 Avg. Cost = 0.030
Epoch: 0014 Avg. Cost = 0.029
Epoch: 0015 Avg. Cost = 0.026
Epoch: 0016 Avg. Cost = 0.026
Epoch: 0017 Avg. Cost = 0.024
Epoch: 0018 Avg. Cost = 0.022
Epoch: 0019 Avg. Cost = 0.020
Epoch: 0020 Avg. Cost = 0.022
Epoch: 0021 Avg. Cost = 0.020
Epoch: 0022 Avg. Cost = 0.021
Epoch: 0023 Avg. Cost = 0.018
Epoch: 0024 Avg. Cost = 0.018
Epoch: 0025 Avg. Cost = 0.018
Epoch: 0026 Avg. Cost = 0.014
Epoch: 0027 Avg. Cost = 0.018
Epoch: 0028 Avg. Cost = 0.017
Epoch: 0029 Avg. Cost = 0.016
Epoch: 0030 Avg. Cost = 0.016
최적화 완료!
정확도: 0.9811
더 해보기
- 이미지와 레이블을 범위를 변경해가며 출력
- 학습시킨 모델을 저장하고 예측 결과만 빠르게 출력
- 텐서플로로 손실값 그래프 확인
댓글남기기