해당 포스트는 책 “골빈해커의 3분 딥러닝 텐서플로맛”의 8장 “대표적 비지도 학습법 Autoencoder”을 학습하고 내용을 정리한 글입니다.
머신러닝 학습 방법의 구분
1) 지도 학습 (supervised learning)
- 프로그램에게 원하는 결과를 알려주고 학습하게 하는 방법
- X와 Y가 둘 다 있는 상태에서 학습
2) 비지도 학습 (unsupervised learning)
- 입력갑으로부터 데이터의 특징을 찾아내는 학습 방법
- X만 있는 상태에서 학습
- 오토인코더(Autoencoder) : 비지도 학습 중 가장 널리 쓰이는 신경망
8.1 오토인코더 개념
오토인코더
- 아래 그림과 같이 입력값과 출력값을 같게 하는 신경망
- 가운데 계층의 노드 수가 입력값보다 적은 것이 특징
- 이런 구조로 인해 입력 데이터를 압축하는 효과를 얻게 됨
- 이 과정에서 노이즈 제거에도 매우 효과적이라고 알려져 있음
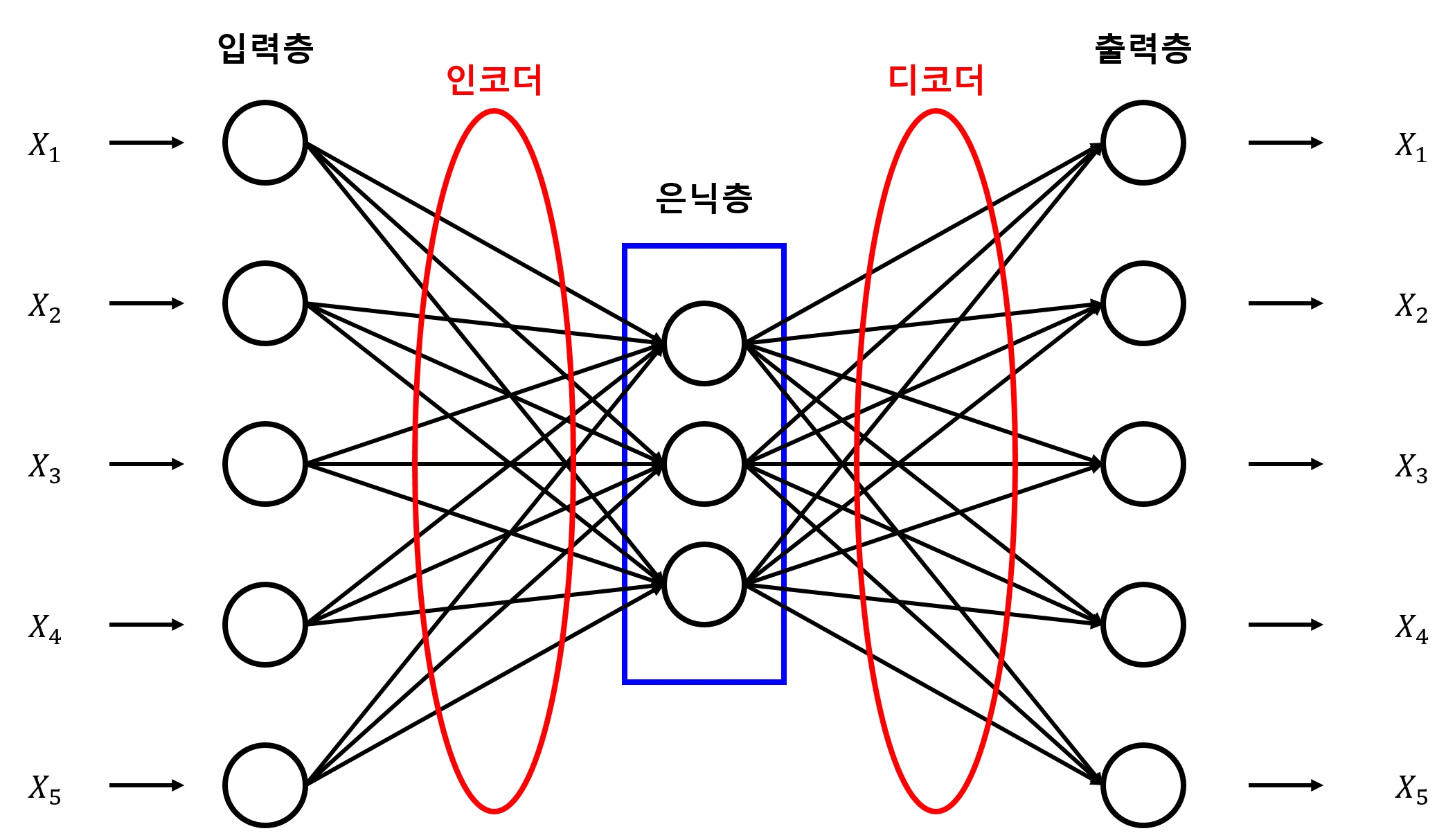
- 오토인코더의 핵심
- 입력층으로 들어온 데이터를 인코더 를 통해 은닉층으로 내보냄
- 은닉층의 데이터를 디코더 를 통해 출력층으로 내보냄
- 만들어진 출력값을 입력값과 비슷해지도록 만드는 가중치를 찾아내는 것
오토인코더의 다양한 방식
- 변이형 오토인코더(Variational Autoencoder)
-
잡음제거 오토인코더(Denoising Autoencoder)
- 여기서는 아주 기본적인 형태를 구현하면서 개념을 이해할 예정
8.2 오토인코더 구현하기
8.2.1 라이브러리 및 학습 데이터 Import
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("./mnist/data", one_hot=True)
Extracting ./mnist/data\train-images-idx3-ubyte.gz
Extracting ./mnist/data\train-labels-idx1-ubyte.gz
Extracting ./mnist/data\t10k-images-idx3-ubyte.gz
Extracting ./mnist/data\t10k-labels-idx1-ubyte.gz
8.2.2 하이퍼파라미터 정의
learning_rate = 0.01
training_epoch = 20
batch_size = 100
n_hidden = 256
n_input = 28*28
learning_rate: 최적화 함수에서 사용할 학습률training_epoch: 전체 데이터를 학습할 총 횟수batch_size: 미니배치, 한 번에 학습할 데이터(이미지)의 개수n_hidden: 은닉층의 뉴런 개수n_input: 입력값의 크기, 사용하는 MNIST의 이미지 크기가 28x28이므로 784가 됨
8.2.3 신경망 모델 구성
- X의 플레이스홀더 설정
- 이 모델은 비지도 학습이므로 Y 값이 없음
X = tf.placeholder(tf.float32, [None, n_input])
8.2.4 인코더 구성
- 오토인코더의 핵심 모델 \(\rightarrow\) 인코더와 디코더를 만드는 것
-
인코더와 디코더를 만드는 방식에 따라 다양한 오토인코더를 만들 수 있음
- 먼저 인코더를 구성
W_encode = tf.Variable(tf.random_normal([n_input, n_hidden]))
b_encode = tf.Variable(tf.random_normal([n_hidden]))
encoder = tf.nn.sigmoid(tf.add(tf.matmul(X, W_encode), b_encode))
- 먼저
n_hidden개의 뉴런을 가진 은닉층을 만듬 - 가중치와 편향 변수를 원하는 뉴런의 개수만큼 설정
-
그 변수들을 입력값과 곱하고 더한 뒤, 활성화 함수인 sigmoid 함수를 적용
- 중요한 부분 : 입력값인
n_input값보다n_hidden값이 더 작다는 점 (은닉층이 더 큰 오토인코더 모델도 있음) - 이렇게 하면 입력값을 압축하고 노이즈를 제거하면서 입력값의 특징을 찾아내게 됨
8.2.5 디코더 구성
W_decode = tf.Variable(tf.random_normal([n_hidden, n_input]))
b_decode = tf.Variable(tf.random_normal([n_input]))
decoder = tf.nn.sigmoid(tf.add(tf.matmul(encoder, W_decode), b_decode))
- 디코더도 인코더와 같은 구성
-
다만, 입력값을 은닉층의 크기(
n_hidden)로, 출력값을 입력층의 크기(n_input)로 만듬 - 최종 모델의 구성은 아래 그림과 같음
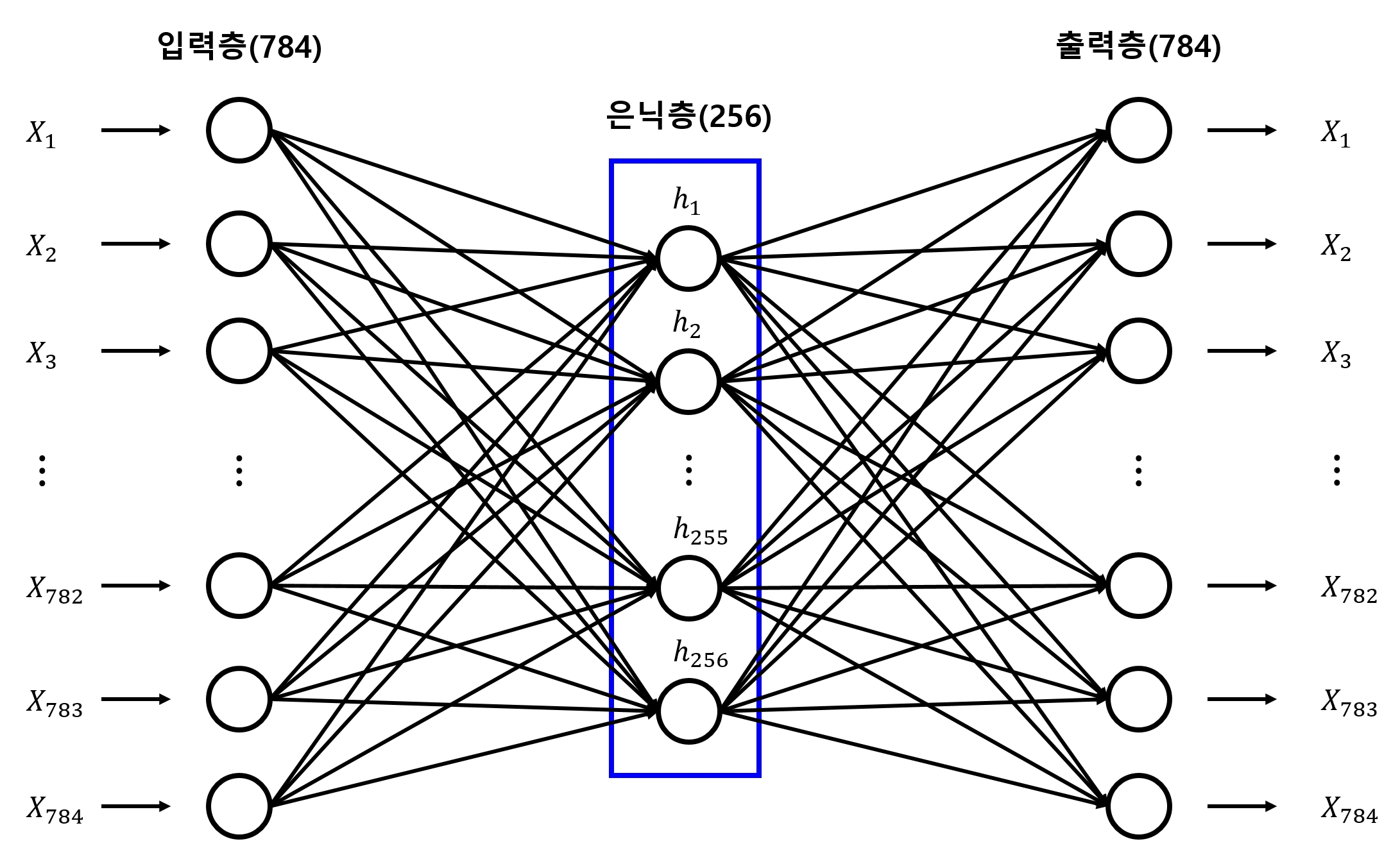
8.2.6 손실 함수 생성
- 가중치들을 최적화하기 위한 손실 함수 생성
- 기본적인 오토인코더의 목적 : 출력값을 입력값과 가장 비슷하게 만드는 것
-
그렇게 하면 압축된 은닉층의 뉴런들을 통해 입력값의 특징을 알아낼 수 있다.
- 다음과 같이 입력값인 X를 평가하기 위한 실측값으로 사용
- 디코더가 내보낸 결과값과의 차이를 손실값 으로 설정
- 이 값의 차이는 거리 함수로 구함
cost = tf.reduce_mean(tf.pow(X - decoder, 2)) # tf.pow : 거듭 제곱 값 계산
8.2.7 최적화 함수
RMSPropOptimizer함수를 이용한 최적화 함수 설정
optimizer = tf.train.RMSPropOptimizer(learning_rate).minimize(cost)
8.2.8 모델 학습
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
total_batch = int(mnist.train.num_examples / batch_size)
for epoch in range(training_epoch):
total_cost = 0
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
_, cost_val = sess.run([optimizer, cost], feed_dict={X: batch_xs})
total_cost += cost_val
print('Epoch: ', '%04d' % (epoch+1),
'Avg. Cost = ', '{:.4f}'.format(total_cost/total_batch))
print('최적화 완료!')
Epoch: 0001 Avg. Cost = 0.1932
Epoch: 0002 Avg. Cost = 0.0496
Epoch: 0003 Avg. Cost = 0.0387
Epoch: 0004 Avg. Cost = 0.0333
Epoch: 0005 Avg. Cost = 0.0306
Epoch: 0006 Avg. Cost = 0.0287
Epoch: 0007 Avg. Cost = 0.0277
Epoch: 0008 Avg. Cost = 0.0270
Epoch: 0009 Avg. Cost = 0.0264
Epoch: 0010 Avg. Cost = 0.0260
Epoch: 0011 Avg. Cost = 0.0255
Epoch: 0012 Avg. Cost = 0.0252
Epoch: 0013 Avg. Cost = 0.0248
Epoch: 0014 Avg. Cost = 0.0243
Epoch: 0015 Avg. Cost = 0.0239
Epoch: 0016 Avg. Cost = 0.0237
Epoch: 0017 Avg. Cost = 0.0235
Epoch: 0018 Avg. Cost = 0.0233
Epoch: 0019 Avg. Cost = 0.0232
Epoch: 0020 Avg. Cost = 0.0231
최적화 완료!
8.2.9 결과값 확인
- 결괏값을 정확도가 아닌, 디코더로 생성해낸 결과를 직관적인 방법으로 확인
-
matplotlib을 이용해 이미지로 출력
- 먼저 총 10개의 테스트 데이터를 가져와 디코더를 이용해 출력값으로 만듬
sample_size = 10
samples = sess.run(decoder, feed_dict={X: mnist.test.images[:sample_size]})
- numpy 모듈을 이용해 MNIST 데이터를 28x28 크기의 이미지 데이터로 재구성
- matplotlib의 imshow 함수를 이용해 그래프에 이미지로 출력
- 위쪽 : 입력값의 이미지 출력
- 아래쪽 : 신경망으로 생성한 이미지 출력
%matplotlib inline
fig, ax = plt.subplots(2, sample_size, figsize=(sample_size, 2))
for i in range(sample_size):
ax[0][i].set_axis_off()
ax[1][i].set_axis_off()
ax[0][i].imshow(np.reshape(mnist.test.images[i], (28, 28)))
ax[1][i].imshow(np.reshape(samples[i], (28, 28)))
plt.show()
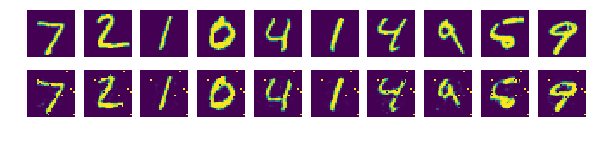
8.2.10 전체 코드
# 8.2.1
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("./mnist/data", one_hot=True)
##########
# 옵션 설정
##########
# 8.2.2
learning_rate = 0.01
training_epoch = 20
batch_size = 100
n_hidden = 256
n_input = 28*28
##########
# 신경망 모델 구성
##########
# 8.2.3
X = tf.placeholder(tf.float32, [None, n_input])
# 8.2.4
W_encode = tf.Variable(tf.random_normal([n_input, n_hidden]))
b_encode = tf.Variable(tf.random_normal([n_hidden]))
encoder = tf.nn.sigmoid(tf.add(tf.matmul(X, W_encode), b_encode))
# 8.2.5
W_decode = tf.Variable(tf.random_normal([n_hidden, n_input]))
b_decode = tf.Variable(tf.random_normal([n_input]))
decoder = tf.nn.sigmoid(tf.add(tf.matmul(encoder, W_decode), b_decode))
# 8.2.6
cost = tf.reduce_mean(tf.pow(X - decoder, 2))
# 8.2.7
optimizer = tf.train.RMSPropOptimizer(learning_rate).minimize(cost)
##########
# 신경망 모델 학습
##########
# 8.2.8
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
total_batch = int(mnist.train.num_examples / batch_size)
for epoch in range(training_epoch):
total_cost = 0
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
_, cost_val = sess.run([optimizer, cost], feed_dict={X: batch_xs})
total_cost += cost_val
print('Epoch: ', '%04d' % (epoch+1),
'Avg. Cost = ', '{:.4f}'.format(total_cost/total_batch))
print('최적화 완료!')
##########
# 결과 확인
##########
# 8.2.9
sample_size = 10
samples = sess.run(decoder, feed_dict={X: mnist.test.images[:sample_size]})
fig, ax = plt.subplots(2, sample_size, figsize=(sample_size, 2))
for i in range(sample_size):
ax[0][i].set_axis_off()
ax[1][i].set_axis_off()
ax[0][i].imshow(np.reshape(mnist.test.images[i], (28, 28)))
ax[1][i].imshow(np.reshape(samples[i], (28, 28)))
plt.show()
Extracting ./mnist/data\train-images-idx3-ubyte.gz
Extracting ./mnist/data\train-labels-idx1-ubyte.gz
Extracting ./mnist/data\t10k-images-idx3-ubyte.gz
Extracting ./mnist/data\t10k-labels-idx1-ubyte.gz
Epoch: 0001 Avg. Cost = 0.2031
Epoch: 0002 Avg. Cost = 0.0630
Epoch: 0003 Avg. Cost = 0.0512
Epoch: 0004 Avg. Cost = 0.0452
Epoch: 0005 Avg. Cost = 0.0417
Epoch: 0006 Avg. Cost = 0.0396
Epoch: 0007 Avg. Cost = 0.0374
Epoch: 0008 Avg. Cost = 0.0357
Epoch: 0009 Avg. Cost = 0.0344
Epoch: 0010 Avg. Cost = 0.0328
Epoch: 0011 Avg. Cost = 0.0320
Epoch: 0012 Avg. Cost = 0.0310
Epoch: 0013 Avg. Cost = 0.0304
Epoch: 0014 Avg. Cost = 0.0300
Epoch: 0015 Avg. Cost = 0.0297
Epoch: 0016 Avg. Cost = 0.0283
Epoch: 0017 Avg. Cost = 0.0279
Epoch: 0018 Avg. Cost = 0.0276
Epoch: 0019 Avg. Cost = 0.0273
Epoch: 0020 Avg. Cost = 0.0272
최적화 완료!
댓글남기기