해당 포스트는 책 “골빈해커의 3분 딥러닝 텐서플로맛”의 10장 “번역과 챗봇 모델의 기본 RNN”을 학습하고 내용을 정리한 글입니다.
- 이미지 인식 \(\rightarrow\) CNN
- 자연어 인식 \(\rightarrow\) RNN
순환 신경망 (RNN; Recurrent Neural Network)
- 다른 신경망들은 상태가 고정된 데이터를 처리
- RNN은 자연어 처리나 음성 인식처럼 순서가 있는 데이터를 처리하는 데 강점을 가진 신경망
- 앞이나 뒤의 정보에 따라 전체의 의미가 달라지거나, 앞의 정보로 다음에 나올 정보를 추측하려는 경우, RNN을 사용하면 성능 좋은 프로그램을 만들 수 있음
구글의 신경망 기반 기계번역
- 2016년 알파고와 함께 화제가 됨
- RNN을 이용하여 만든 서비스
- 기존에 제공하던 통계 기반 번역 서비스의 성능을 한참 뛰어넘을 수 있었음
-
지속적인 학습으로 빠르게 성능을 개선하여 몇몇 언어에서는 인간에 가까운 수준에 도달
- 구글 기계번역 성능 그래프 (출처 : Google AI Blog)
![]()
- 이번 장에서는 RNN의 기본적인 사용법 을 배우고, 마지막에는 Sequence to Sequence 모델을 이용해 간단한 번역 프로그램을 만들어 봄
10.1 MNIST를 RNN으로
- RNN의 개념은 다른 신경망과는 많이 다름
- 개념을 쉽게 이해하기 위해 계속 사용해온 손글씨 이미지를 RNN 방식으로 학습하고 예측하는 모델 만들어 봄
기본적인 RNN의 개념
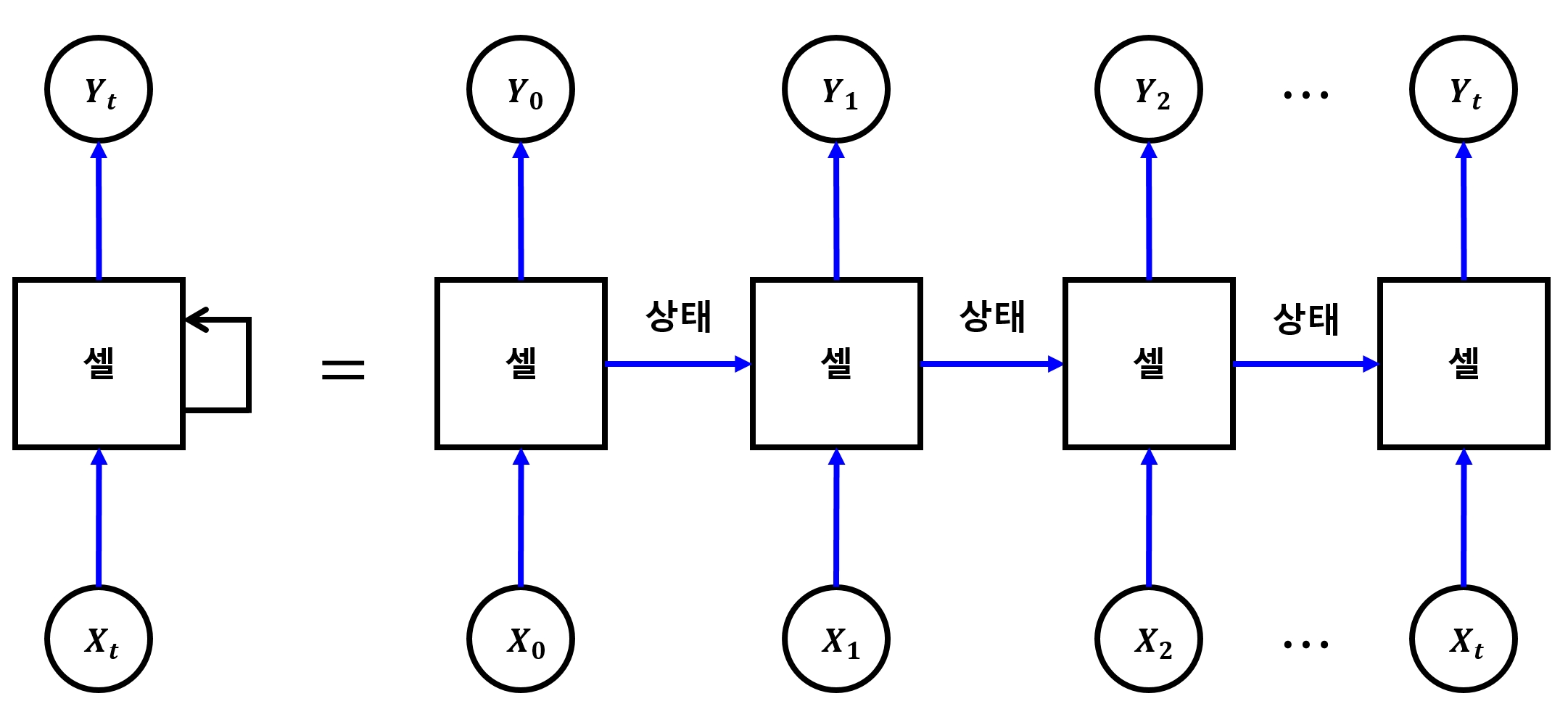
셀(Cell)
- 위 그림의 가운데 있는 한 덩어리의 신경망을 RNN에서는 셀(Cell) 이라고 함
- RNN은 이 셀을 여러 개 중첩하여 심층 신경망을 만듬
- 앞 단계에서 학습한 결과를 다음 단계의 학습에 이용하는 것
-
이런 구조로 인해 학습 데이터를 단계별로 구분하여 입력해야 함
- 따라서 MNIST의 입력값도 단계별로 입력할 수 있는 형태로 변경해줘야 한다.
- 사람은 글씨를 위에서 아래로 내려가면서 쓰는 경향이 많음
- 그러므로 데이터를 아래 그림처럼 구성
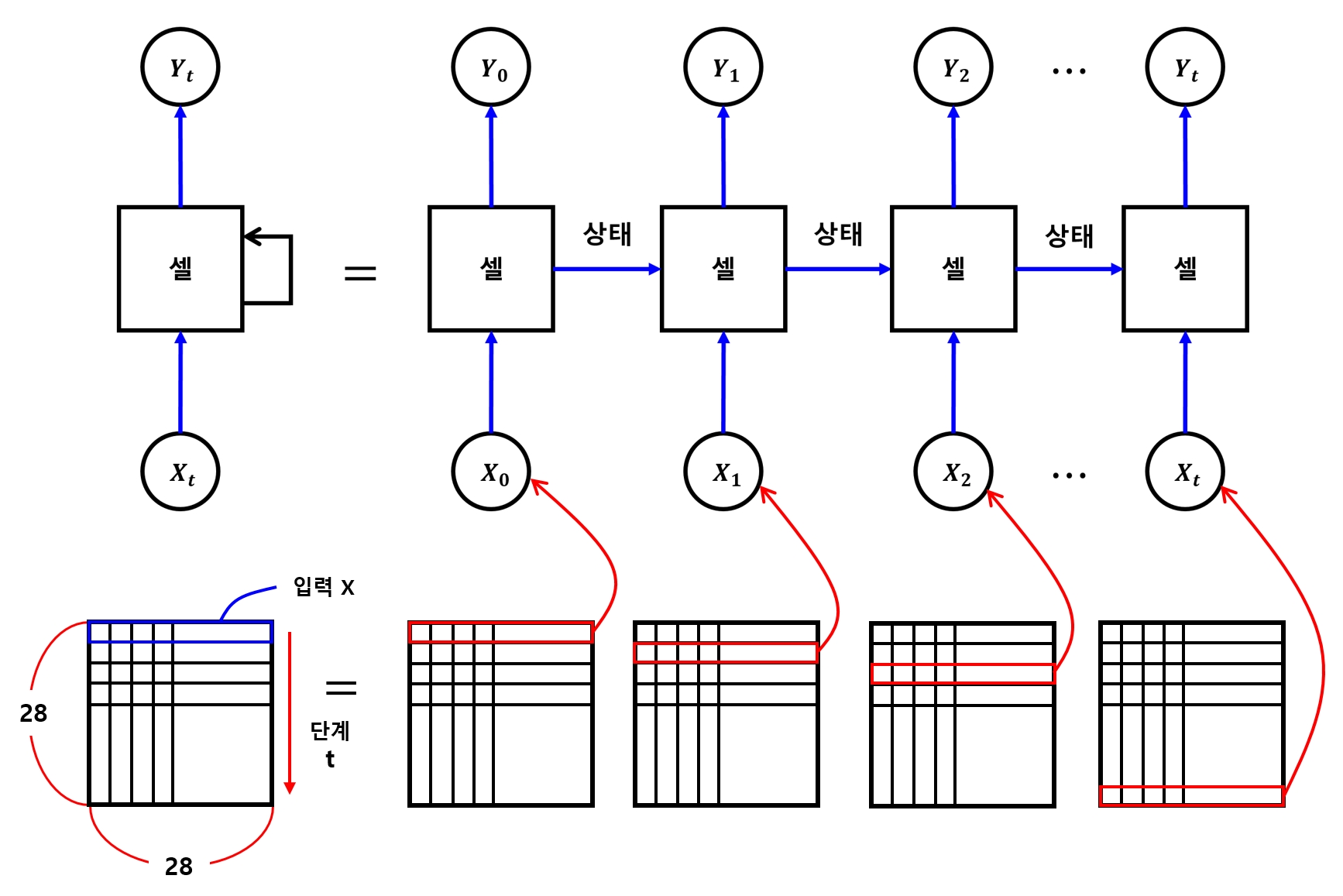
- MNIST 데이터가 가로·세로 28x28 크기 \(\rightarrow\) 가로 한 줄의 28픽셀을 한 단계의 입력으로 삼음
- 세로줄이 총 28개이므로 28단계를 거쳐 데이터를 입력받는 개념
10.1.1 라이브러리 Import & 하이퍼파라미터, 변수, 가중치 및 편향 정의
- 학습에 사용할 하이퍼파라미터들과 변수 정의
- 출력층을 위한 가중치와 편향 정의
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("./mnist/data/", one_hot=True)
learning_rate = 0.001
total_epoch = 30
batch_size = 128
n_input = 28
n_step = 28
n_hidden = 128
n_class = 10
X = tf.placeholder(tf.float32, [None, n_step, n_input])
Y = tf.placeholder(tf.float32, [None, n_class])
W = tf.Variable(tf.random_normal([n_hidden, n_class]))
b = tf.Variable(tf.random_normal([n_class]))
Extracting ./mnist/data/train-images-idx3-ubyte.gz
Extracting ./mnist/data/train-labels-idx1-ubyte.gz
Extracting ./mnist/data/t10k-images-idx3-ubyte.gz
Extracting ./mnist/data/t10k-labels-idx1-ubyte.gz
기존 모델과 다른 점
- 입력값 X에
n_step이라는 차원을 하나 추가한 부분 - RNN은 순서가 있는 데이터를 다루므로 한 번에 입력 받을 개수와 총 몇 단계로 이뤄진 데이터를 받을 지를 설정
-
가로 픽셀 수 =
n_input, 세로 픽셀 수 =n_step(입력단계) 로 설정 - 출력값은 MNIST의 분류인 0~9까지 10개의 숫자를 원-핫 인코딩으로 표현
10.1.2 RNN 셀 생성
n_hidden개의 출력값을 갖는 RNN 셀을 생성- RNN을 직접 구현하려면 다른 신경망보다 복잡한 계산을 거쳐야 함
- 텐서플로를 이용하면 아래와 같이 매우 간단하게 생성할 수 있음
cell = tf.nn.rnn_cell.BasicRNNCell(n_hidden)
RNN 셀 생성 함수
- 여기서는 신경망 구성을 위해
BasicRNNCell함수를 사용했음 - 텐서플로에선 이 외에도
BasicLSTMCell,GRUCell등 다양한 방식의 셀을 사용할 수 있는 함수들을 제공
여러 가지 신경망 아키텍쳐
- RNN의 기본 신경망은 긴 단계의 데이터를 학습할 때 맨 뒤에서는 맨 앞의 정보를 잘 기억하지 못하는 특성이 있음
- 이를 보완하기 위해 다양한 구조가 만들어짐
- 그 중 가장 많이 사용되는 것 \(\rightarrow\) LSTM(Long Sort-Term Memory) 이라는 신경망
- GRU(Gatd Recurrent Units) 는 LSTM과 비슷하지만 구조가 조금 더 간단한 신경망 아키텍쳐
10.1.3 RNN 신경망 완성
dynamic_rnn함수를 이용해 RNN 신경망을 완성
outputs, states = tf.nn.dynamic_rnn(cell, X, dtype=tf.float32)
- 앞서 생성한 RNN 셀(
cell)과 입력값(X), 그리고 입력값의 자료형(dtype=tf.float32)을 넣어주기만 하면 간단하게 신경망을 생성할 수 있음 - 원래는 다음과 같이 주어진 단계를 반복하는 과정을 거쳐야 함
states = tf.zeros(batch_size)
for i in range(n_step):
outputs, states = cell(X[[:, i]], states)
...
- 위의 그림처럼 한 단계를 학습한 뒤 상태를 저장하고, 그 상태를 다음 단계의 입력 상태로 하여 다시 학습을 실시
-
이렇게 주어진 단계만큼 반복하여 상태를 전파하면서 출력값을 만들어가는 것이 RNN의 기본 구조
- 반복 단계에서 고려해야 할 것이 많음 \(\rightarrow\) 이 과정을 대신해주는
dynamic_rnn함수를 바로 사용 - 이 함수를 사용하면 간단하게 RNN 모델의 핵심 구조(셀과 신경망)를 만들 수 있음
10.1.4 최종 출력값 생성
- RNN에서 나온 출력값(
outputs)을 가지고 최종 출력값 생성 - 결괏값을 원-핫 인코딩 형태로 만들 것 \(\rightarrow\) 손실 함수로
tf.nn.softmax_cross_entropy_with_logits_v2를 사용 - 이 함수를 사용하려면 최종 결괏값이 실측값 Y와 동일한 형태인
[batch_size, n_class]여야 함 - 이 형태의 출력값을 만들기 위해 가중치와 편향을 다음과 같이 설정함
W = tf.Variable(tf.random_normal([n_hidden, n_class]))
b = tf.Variable(tf.random_normal([n_class]))
- 그런데 RNN 신경망에서 나오는 출력값은 각 단계가 포함된
[batch_size, n_step, n_hidden]형태임 - 따라서 아래와 같이 은닉층의 출력값을 가중치 W와 같은 형태로 만들어줘야 함
-
그래야 행렬곱을 수행하여 원하는 출력값을 얻을 수 있음
- cf)
dynamic_rnn함수의 옵션 중time_major의 값을True로 하면[n_step, batch_size, n_hidden]형태로 출력됨
# outputs : [batch_size, n_step, n_hidden]
# -> [n_step, batch_size, n_hidden]
outputs = tf.transpose(outputs, [1, 0, 2])
# -> [batch_size, n_hidden]
outputs = outputs[-1]
tf.transpose함수를 이용해n_step과batch_size차원의 순서를 바꿈- 그런 다음
n_step차원을 제거하여 마지막 단계의 결괏값만 취함
10.1.5 최종 결괏값 생성
- 인공신경망의 기본 수식 \(y = X \times W + b\)를 이용하여 최종 결괏값을 만듬
model = tf.matmul(outputs, W) + b
10.1.6 손실값 계산 및 최적화
- 지금까지 만든 모델과 실측값을 비교 \(\wrightarrow\) 손실값을 구함
- 신경망을 최적화하는 함수를 사용하여 신경망 구성을 마무리
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=model, labels=Y))
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost)
10.1.7 신경망 학습 및 결과 확인
주의 사항
- 입력값이
[batch_size, n_step, n_input]형태이므로 CNN에서 사용한 것처럼reshape함수를 이용해 데이터 형태를 바꿔주는 부분 주의
sess = tf.Session()
sess.run(tf.global_variables_initializer())
total_batch = int(mnist.train.num_examples/batch_size)
for epoch in range(total_epoch):
total_cost = 0
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
batch_xs = batch_xs.reshape((batch_size, n_step, n_input))
_, cost_val = sess.run([optimizer, cost], feed_dict={X: batch_xs, Y: batch_ys})
total_cost += cost_val
print('Epoch: ', '%04d' % (epoch+1),
'Avg. Cost = ', '{:.3f}'.format(total_cost / total_batch))
print('최적화 완료!')
# 결과 확인
is_correct = tf.equal(tf.argmax(model, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
test_batch_size = len(mnist.test.images)
test_xs = mnist.test.images.reshape(test_batch_size, n_step, n_input)
test_ys = mnist.test.labels
print('정확도 : ', sess.run(accuracy, feed_dict={X: test_xs, Y: test_ys}))
Epoch: 0001 Avg. Cost = 0.533
Epoch: 0002 Avg. Cost = 0.244
Epoch: 0003 Avg. Cost = 0.188
Epoch: 0004 Avg. Cost = 0.157
Epoch: 0005 Avg. Cost = 0.139
Epoch: 0006 Avg. Cost = 0.131
Epoch: 0007 Avg. Cost = 0.118
Epoch: 0008 Avg. Cost = 0.116
Epoch: 0009 Avg. Cost = 0.104
Epoch: 0010 Avg. Cost = 0.096
Epoch: 0011 Avg. Cost = 0.102
Epoch: 0012 Avg. Cost = 0.092
Epoch: 0013 Avg. Cost = 0.085
Epoch: 0014 Avg. Cost = 0.089
Epoch: 0015 Avg. Cost = 0.086
Epoch: 0016 Avg. Cost = 0.081
Epoch: 0017 Avg. Cost = 0.077
Epoch: 0018 Avg. Cost = 0.077
Epoch: 0019 Avg. Cost = 0.072
Epoch: 0020 Avg. Cost = 0.077
Epoch: 0021 Avg. Cost = 0.076
Epoch: 0022 Avg. Cost = 0.070
Epoch: 0023 Avg. Cost = 0.069
Epoch: 0024 Avg. Cost = 0.068
Epoch: 0025 Avg. Cost = 0.065
Epoch: 0026 Avg. Cost = 0.060
Epoch: 0027 Avg. Cost = 0.064
Epoch: 0028 Avg. Cost = 0.068
Epoch: 0029 Avg. Cost = 0.065
Epoch: 0030 Avg. Cost = 0.060
최적화 완료!
정확도 : 0.9735
- 실행한 결과 97.4% 의 정확도로 손글씨를 인식
10.1.8 전체 코드
# 10.1.1
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("./mnist/data/", one_hot=True)
##########
# 옵션 설정
##########
learning_rate = 0.001
total_epoch = 30
batch_size = 128
n_input = 28
n_step = 28
n_hidden = 128
n_class = 10
##########
# 신경망 모델 구성
##########
X = tf.placeholder(tf.float32, [None, n_step, n_input])
Y = tf.placeholder(tf.float32, [None, n_class])
W = tf.Variable(tf.random_normal([n_hidden, n_class]))
b = tf.Variable(tf.random_normal([n_class]))
# 10.1.2
cell = tf.nn.rnn_cell.BasicRNNCell(n_hidden)
# 10.1.3
outputs, states = tf.nn.dynamic_rnn(cell, X, dtype=tf.float32)
# 10.1.4
outputs = tf.transpose(outputs, [1, 0, 2])
outputs = outputs[-1]
# 10.1.5
model = tf.matmul(outputs, W) + b
# 10.1.6
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=model, labels=Y))
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost)
##########
# 신경망 모델 학습
##########
# 10.1.7
sess = tf.Session()
sess.run(tf.global_variables_initializer())
total_batch = int(mnist.train.num_examples/batch_size)
for epoch in range(total_epoch):
total_cost = 0
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
batch_xs = batch_xs.reshape((batch_size, n_step, n_input))
_, cost_val = sess.run([optimizer, cost], feed_dict={X: batch_xs, Y: batch_ys})
total_cost += cost_val
print('Epoch: ', '%04d' % (epoch+1),
'Avg. Cost = ', '{:.3f}'.format(total_cost / total_batch))
print('최적화 완료!')
##########
# 신경망 모델 학습
##########
is_correct = tf.equal(tf.argmax(model, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
test_batch_size = len(mnist.test.images)
test_xs = mnist.test.images.reshape(test_batch_size, n_step, n_input)
test_ys = mnist.test.labels
print('정확도 : ', sess.run(accuracy, feed_dict={X: test_xs, Y: test_ys}))
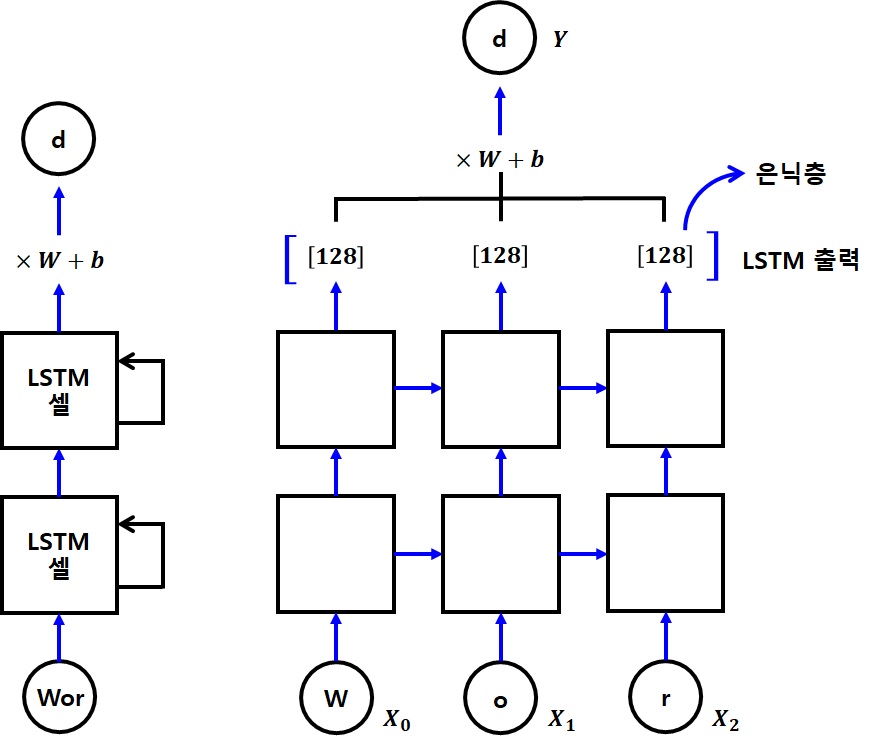
10.2 단어 자동 완성
- RNN 모델을 이용하여 단어를 자동 완성하는 프로그램 만들기
-
영문자 4개로 구성된 단어를 학습시켜, 3글자만 주어지면 나머지 한 글자를 추천하여 단어를 완성하는 프로그램
dynamic_rnn의sequence_length옵션을 사용하면 가변 길이 단어를 학습시킬 수 있음- 짧은 단어는 가장 긴 단어의 길이 만큼 뒷부분을 0으로 채우고, 해당 단어의 길이를 계산해
sequence_length로 넘겨줌 (batch_size만큼의 배열로) -
여기서는 고정길이 단어를 사용
- 학습시킬 데이터 : 영문자로 구성된 임의의 단어를 사용
- 한 글자 한 글자를 하나의 단계로 볼 것
- 그러면 한 글자가 한 단계의 입력값이 되고, 총 글자 수가 전체 단계가 됨
10.2.1 데이터 전처리 - 알파벳 정의
- 입력으로 알파벳 순서에서 각 글자에 해당하는 인덱스를 원-핫 인코딩으로 표현한 값 사용
- 알파벳 글자들을 배열에 넣고, 해당 글자의 인덱스를 구할 수 있는 연관 배열(딕셔너리)도 생성
import tensorflow as tf
import numpy as np
char_arr = ['a', 'b', 'c', 'd', 'e', 'f', 'g',
'h', 'i', 'j', 'k', 'l', 'm', 'n',
'o', 'p', 'q', 'r', 's', 't', 'u',
'v', 'w', 'x', 'y', 'z']
# {'a': 0, 'b': 1, 'c': 2, ..., 'j': 9, 'k', 10, ...}
num_dic = {n: i for i, n in enumerate(char_arr)}
dic_len = len(num_dic)
10.2.2 데이터 전처리 - 단어 정의
- 학습에 사용할 단어를 배열로 저장
seq_data = ['word', 'wood', 'deep', 'dive', 'cold', 'cool', 'load', 'love', 'kiss', 'kind']
10.2.3 데이터 전처리 - 단어 형식 변환 함수
- 단어들을 학습에 사용할 수 있는 형식으로 변환해주는 유틸리티 함수 작성
- 이 함수는 다음 순서로 데이터를 변환
- 입력값용, 단어의 처음 세 글자의 알파벳 인덱스를 구한 배열을 만듬
input = [num_dic[n] for n in seq[:-1]] # seq[:-1] : 각 단어의 처음 3글자 (ex. wor, woo, ...)
- 출력값용, 마지막 글자의 알파벳 인덱스를 구함
target = num_dic[seq[-1]] # seq[-1] : 각 단어의 마지막 글자 (ex. d, d, ...)
- 입력값을 원-핫 인코딩으로 변환
input_batch.append(np.eye(dic_len)[input])
cf) np.eye(n)
- n행 n열의 단위 행렬 생성
np.eye(10)
array([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 1., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 1., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 1., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 1., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.]])
np.eye(10)[[1, 2, 3]]
array([[0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 1., 0., 0., 0., 0., 0., 0.]])
- 예를 들어, “deep”는 입력으로 d, e, e를 취하고, 각 알파벳의 인덱스를 구해 배열로 만들면 [3, 4, 4]가 나옴
- 그리고 이를 원-핫 인코딩하면 최종 입력값은 다음이 됨
[[0. 0. 0. 1. 0. 0. 0. ... 0.] [0. 0. 0. 0. 1. 0. 0. ... 0.] [0. 0. 0. 0. 1. 0. 0. ... 0.]] - 실측값 = 15 (p의 인덱스)
- 실측값은 원-핫 인코딩하지 않고 15를 그대로 사용
- 그 이유는 손실 함수로 지금까지 사용하던
softmax_cross_entropy_with_logits가 아닌sparse_softmax_cross_entropy_with_logits를 사용할 것이기 때문 - 함수 앞에
sparse가 붙어 있다는 것에 유의
sparse_softmax_cross_entropy_with_logits
-
실측값, 즉
labels값에 원-핫 인코딩을 사용하지 않아도 자동으로 변환하여 계산해 줌 -
변화하는 함수 작성
def make_batch(seq_data):
input_batch = []
target_batch = []
for seq in seq_data:
input = [num_dic[n] for n in seq[:-1]]
target = num_dic[seq[-1]]
input_batch.append(np.eye(dic_len)[input])
target_batch.append(target)
return input_batch, target_batch
10.2.4 옵션 설정
learning_rate = 0.01
n_hidden = 128
total_epoch = 30
n_step = 3
n_input = n_class = dic_len
- 단어의 전체 중 처음 3글자를 단계적으로 학습 \(\rightarrow\)
n_step=3 - 입력값(
n_input)과 출력값(n_class)은 알파벳의 원-핫 인코딩을 사용 \(\rightarrow\) 알파벳 글자들의 배열 크기인dic_len과 같음
주의 사항
sparse_softmax_cross_entropy_with_logits함수를 사용하더라도 비교를 위한 예측 모델의 출력값은 원-핫 인코딩을 사용해야 함-
그래서
n_class값도n_input값과 마찬가지로dic_len과 크기가 같도록 설정 - 즉, 해당 함수를 사용할 때,
- 실측값인
labels값 \(\rightarrow\) 인덱스의 숫자 그대로 사용 - 예측 모델의 출력값 \(\rightarrow\) 인덱스의 원-핫 인코딩을 사용
- 실측값인
10.2.5 신경망 모델 구성
X = tf.placeholder(tf.float32, [None, n_step, n_input])
Y = tf.placeholder(tf.int32, [None])
W = tf.Variable(tf.random_normal([n_hidden, n_class]))
b = tf.Variable(tf.random_normal([n_class]))
Y : 실측값의 플레이스홀더
batch_size에 해당하는 하나의 차원만 있는 것 유의- 원-핫 인코딩이 아니라 인덱스 숫자를 그대로 사용하기 때문에 다음처럼 값이 하나뿐인 1차원 배열을 입력으로 받음
[3] [3] [15] [4] ...
10.2.6 RNN 셀 생성
- 두 개의 RNN 셀 생성 (여러 셀을 조합해 심층 신경망을 만들기 위해)
DropoutWrapper함수를 사용하여 RNN에도 과적합 방지를 위한 드롭아웃 기법 적용
cell1 = tf.nn.rnn_cell.BasicLSTMCell(n_hidden)
cell1 = tf.nn.rnn_cell.DropoutWrapper(cell1, output_keep_prob=0.5)
cell2 = tf.nn.rnn_cell.BasicLSTMCell(n_hidden)
10.2.7 Deep RNN 생성
- 앞서 만든 셀들을
MultiRNNCell함수를 사용하여 조합 - 그러고난 후
dynamic_rnn함수를 사용하여 심층 순환 신경망, 즉 Deep RNN을 만듬
multi_cell = tf.nn.rnn_cell.MultiRNNCell([cell1, cell2])
outputs, states = tf.nn.dynamic_rnn(multi_cell, X, dtype=tf.float32)
10.2.8 최종 출력층 생성
- MNIST 예측 모델과 같은 방식으로 최종 출력층 생성
outputs = tf.transpose(outputs, [1, 0, 2])
outputs = outputs[-1]
model = tf.matmul(outputs, W) + b
10.2.9 손실 함수 및 최적화 함수 정의
- 손실 함수 생성 :
sparse_softmax_cross_entropy_with_logits사용 - 최적화 함수 생성 :
AdamOptimizer사용
cost = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=model, labels=Y))
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost)
10.2.10 신경망 학습
make_batch함수를 이용하여seq_data에 저장한 단어들을 입력값(처음 세 글자)과 실측값(마지막 한 글자)으로 분리- 이 값들을 최적화 함수를 실행하는 코드에 넣어 신경망을 학습
sess = tf.Session()
sess.run(tf.global_variables_initializer())
input_batch, target_batch = make_batch(seq_data)
for epoch in range(total_epoch):
_, loss = sess.run([optimizer, cost], feed_dict={X: input_batch, Y: target_batch})
print('Epoch: ', '%04d' % (epoch+1),
'Cost = ', '{:.6f}'.format(loss))
print('최적화 완료!')
Epoch: 0001 Cost = 2.687207
Epoch: 0002 Cost = 1.947173
Epoch: 0003 Cost = 1.424140
Epoch: 0004 Cost = 1.117906
Epoch: 0005 Cost = 0.519626
Epoch: 0006 Cost = 0.663280
Epoch: 0007 Cost = 0.665404
Epoch: 0008 Cost = 0.271773
Epoch: 0009 Cost = 0.280525
Epoch: 0010 Cost = 0.360162
Epoch: 0011 Cost = 0.232401
Epoch: 0012 Cost = 0.154692
Epoch: 0013 Cost = 0.222488
Epoch: 0014 Cost = 0.179288
Epoch: 0015 Cost = 0.066757
Epoch: 0016 Cost = 0.118170
Epoch: 0017 Cost = 0.047960
Epoch: 0018 Cost = 0.022420
Epoch: 0019 Cost = 0.103166
Epoch: 0020 Cost = 0.227972
Epoch: 0021 Cost = 0.024374
Epoch: 0022 Cost = 0.024660
Epoch: 0023 Cost = 0.011359
Epoch: 0024 Cost = 0.012229
Epoch: 0025 Cost = 0.022206
Epoch: 0026 Cost = 0.018780
Epoch: 0027 Cost = 0.003324
Epoch: 0028 Cost = 0.001062
Epoch: 0029 Cost = 0.061766
Epoch: 0030 Cost = 0.003813
최적화 완료!
10.2.11 정확도 출력
- 결괏값으로 예측한 단어를 정확도와 함께 출력
prediction = tf.cast(tf.argmax(model, 1), tf.int32)
prediction_check = tf.equal(prediction, Y)
accuracy = tf.reduce_mean(tf.cast(prediction_check, tf.float32))
- 실측값을 원-핫 인코딩이 아닌 인덱스를 그대로 사용하므로 실측값, 즉 Y는 정수
- 따라서 argmax로 변환한 예측값도 정수로 변경
- 또한 정확도를 구할 때 입력값을 그대로 비교
10.2.12 단어 예측 모델 실행
- 학습에 사용한 단어들을 넣고 예측 모델을 돌림
input_batch, target_batch = make_batch(seq_data)
predict, accuracy_val = sess.run([prediction, accuracy], feed_dict={X: input_batch, Y: target_batch})
10.2.13 예측 단어 출력
- 모델이 예측한 값들을 가지고, 각각의 값에 해당하는 인덱스의 알파벳을 가져와서 예측한 단어를 출력
predict_words = []
for idx, val in enumerate(seq_data):
last_char = char_arr[predict[idx]]
predict_words.append(val[:3] + last_char)
print('\n=== 예측 결과 ===')
print('입력값: ', [w[:3] + ' ' for w in seq_data])
print('예측값: ', predict_words)
print('정확도: ', accuracy_val)
=== 예측 결과 ===
입력값: ['wor ', 'woo ', 'dee ', 'div ', 'col ', 'coo ', 'loa ', 'lov ', 'kis ', 'kin ']
예측값: ['word', 'wood', 'deep', 'dive', 'cold', 'cool', 'load', 'love', 'kiss', 'kind']
정확도: 1.0
10.2.14 전체 코드
# 10.2.1
import tensorflow as tf
import numpy as np
char_arr = ['a', 'b', 'c', 'd', 'e', 'f', 'g',
'h', 'i', 'j', 'k', 'l', 'm', 'n',
'o', 'p', 'q', 'r', 's', 't', 'u',
'v', 'w', 'x', 'y', 'z']
# {'a': 0, 'b': 1, 'c': 2, ..., 'j': 9, 'k', 10, ...}
num_dic = {n: i for i, n in enumerate(char_arr)}
dic_len = len(num_dic)
# 10.2.2
seq_data = ['word', 'wood', 'deep', 'dive', 'cold', 'cool', 'load', 'love', 'kiss', 'kind']
# 10.2.3
def make_batch(seq_data):
input_batch = []
target_batch = []
for seq in seq_data:
input = [num_dic[n] for n in seq[:-1]]
target = num_dic[seq[-1]]
input_batch.append(np.eye(dic_len)[input])
target_batch.append(target)
return input_batch, target_batch
##########
# 옵션 설정
##########
# 10.2.4
learning_rate = 0.01
n_hidden = 128
total_epoch = 30
n_step = 3
n_input = n_class = dic_len
##########
# 신경망 모델 구성
##########
# 10.2.5
X = tf.placeholder(tf.float32, [None, n_step, n_input])
Y = tf.placeholder(tf.int32, [None])
W = tf.Variable(tf.random_normal([n_hidden, n_class]))
b = tf.Variable(tf.random_normal([n_class]))
# 10.2.6
cell1 = tf.nn.rnn_cell.BasicLSTMCell(n_hidden)
cell1 = tf.nn.rnn_cell.DropoutWrapper(cell1, output_keep_prob=0.5)
cell2 = tf.nn.rnn_cell.BasicLSTMCell(n_hidden)
# 10.2.7
multi_cell = tf.nn.rnn_cell.MultiRNNCell([cell1, cell2])
outputs, states = tf.nn.dynamic_rnn(multi_cell, X, dtype=tf.float32)
# 10.2.8
outputs = tf.transpose(outputs, [1, 0, 2])
outputs = outputs[-1]
model = tf.matmul(outputs, W) + b
# 10.2.9
cost = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=model, labels=Y))
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost)
##########
# 신경망 모델 학습
##########
# 10.2.10
sess = tf.Session()
sess.run(tf.global_variables_initializer())
input_batch, target_batch = make_batch(seq_data)
for epoch in range(total_epoch):
_, loss = sess.run([optimizer, cost], feed_dict={X: input_batch, Y: target_batch})
print('Epoch: ', '%04d' % (epoch+1),
'Cost = ', '{:.6f}'.format(loss))
print('최적화 완료!')
# 10.2.11
prediction = tf.cast(tf.argmax(model, 1), tf.int32)
prediction_check = tf.equal(prediction, Y)
accuracy = tf.reduce_mean(tf.cast(prediction_check, tf.float32))
# 10.2.12
input_batch, target_batch = make_batch(seq_data)
predict, accuracy_val = sess.run([prediction, accuracy], feed_dict={X: input_batch, Y: target_batch})
# 10.2.13
predict_words = []
for idx, val in enumerate(seq_data):
last_char = char_arr[predict[idx]]
predict_words.append(val[:3] + last_char)
print('\n=== 예측 결과 ===')
print('입력값: ', [w[:3] + ' ' for w in seq_data])
print('예측값: ', predict_words)
print('정확도: ', accuracy_val)
10.3 Sequence to Sequence
Sequence to Sequence (Seq2Seq)
- 구글이 기계번역에 사용하는 신경망 모델
- 순차적인 정보를 입력받는 신경망 (RNN)과 출력하는 신경망을 조합한 모델
- 번역이나 챗봇 등 문장을 입력받아 다른 문장을 출력하는 프로그램에서 많이 사용
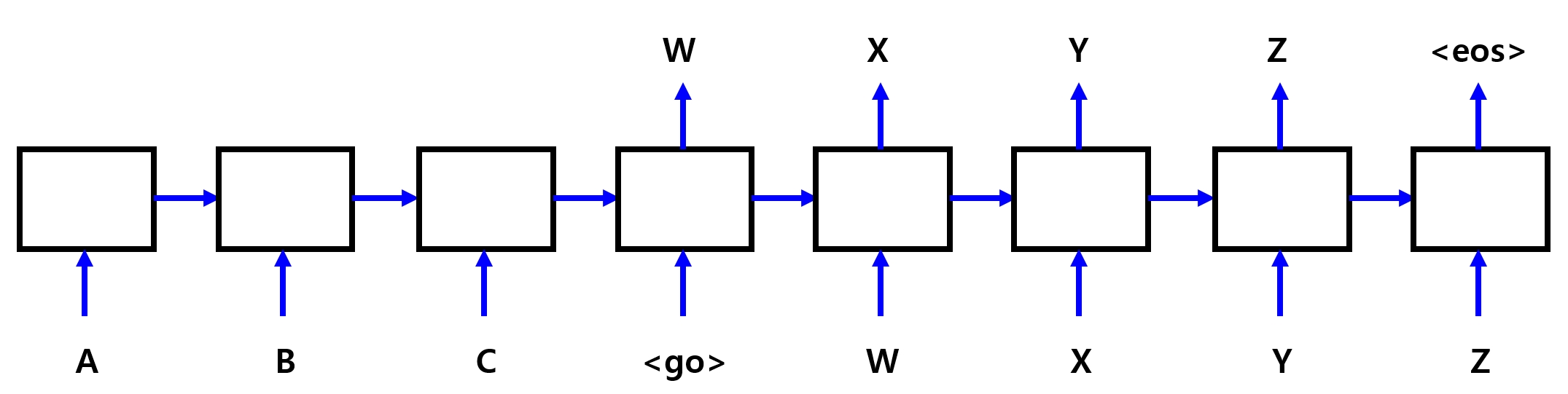
Sequence to Sequence 모델의 구성
1) 인코더
- 입력을 위한 신경망
- 원문을 입력 받음
2) 디코더
- 출력을 위한 신경망
-
인코더가 번역한 결과물을 입력 받음
- 디코더가 출력한 결과물을 번역된 결과물과 비교하면서 학습
- Sequence to Sequence 모델을 이용해 번역 프로그램 만들기
- 아래 그림처럼 네 글자의 영어 단어를 입력받아 두 글자의 한글 단어로 번역하는 프로그램
![]()
- Sequence to Sequence 모델에는 위의 그림처럼 특수한 심볼 몇 개가 필요
\(\rightarrow\)<S>: 디코더에 입력이 시작됨을 알려주는 심볼
\(\rightarrow\)<E>: 디코더의 출력이 끝났음을 알려주는 심볼
\(\rightarrow\)<P>: 빈 데이터를 채울 때 사용하는 아무 의미가 없는 심볼
10.3.1 데이터 만들기
import tensorflow as tf
import numpy as np
- 글자들을 학습시키려면 원-핫 인코딩 형식으로 바꿔야 함 \(\rightarrow\) 영어 알파벳과 한글들을 나열한 뒤 한 글자씩 배열에 집어 넣음
char_arr = [c for c in 'SEPabcdefghijklmnopqrstuvwxyz단어나무놀이소녀키스사랑']
- 그런 다음 배열에 넣은 글자들을 연관 배열(키/값 쌍) 형태로 변경
(한글은 글자 수가 매우 많으므로 여기서는 학습에 사용할 단어들에 포함된 한글만 사용)
num_dic = {n: i for i, n in enumerate(char_arr)}
dic_len = len(num_dic)
- 학습에 사용할 영어 단어와 한글 단어의 쌍을 가진 데이터를 정의
seq_data = [['word', '단어'], ['wood', '나무'],
['game', '놀이'], ['girl', '소녀'],
['kiss', '키스'], ['love', '사랑']]
10.3.2 단어 형식 변환 함수 정의
- 입력 단어와 출력 단어를 한 글자씩 떼어낸 뒤 배열로 만든 후에 원-핫 인코딩 형식으로까지 만들어주는 유틸리티 함수 생성
- 데이터(3가지) : 인코더의 입력값, 디코더의 입력값, 디코더의 출력값
- 인코더 셀의 입력값 : 입력 단어를 한 글자씩 떼어 배열로 만듬
input = [num_dic[n] for n in seq[0]]
- 디코더 셀의 입력값 : 출력 단어의 글자들을 배열로 만들고, 시작을 나타내는 심볼 ‘S’를 맨 앞에 붙임
output = [num_dic[n] for n in ('S' + seq[1])]
- 학습을 위해 비교할 디코더 셀의 출력값을 만들고, 출력의 끝을 알려주는 심볼 ‘E’를 마지막에 붙임
target = [num_dic[n] for n in (seq[1]+'E')]
- 만들어진 데이터를 원-핫 인코딩 실시
- 다만, 앞의 예제처럼 손실 함수로
sparse_softmax_cross_entropy_with_logits를 사용할 것
\(\rightarrow\) 실측값인 디코더 셀의 출력값은 원-핫 인코딩이 아닌 인덱스 숫자를 그대로 사용
def make_batch(seq_data):
input_batch = []
output_batch = []
target_batch = []
for seq in seq_data:
input = [num_dic[n] for n in seq[0]]
output = [num_dic[n] for n in ('S' + seq[1])]
target = [num_dic[n] for n in (seq[1] + 'E')]
input_batch.append(np.eye(dic_len)[input])
output_batch.append(np.eye(dic_len)[output])
# 출력값만 one-hot 인코딩이 아님 (sparse_softmax_cross_entropy_with_logits 사용)
target_batch.append(target)
return input_batch, output_batch, target_batch
함수 내용 확인
for seq in seq_data:
i = [num_dic[n] for n in seq[0]]
print('input: ', i)
print('ont-hot input: \n', np.eye(dic_len)[i])
print('\n')
o = [num_dic[n] for n in ('S' + seq[1])]
print('output: ', o)
#print('ont-hot output: \n', np.eye(dic_len)[o])
print('\n')
t = [num_dic[n] for n in (seq[1] + 'E')]
print('target: ', t)
print('\n')
input: [25, 17, 20, 6]
ont-hot input:
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]
output: [0, 29, 30]
target: [29, 30, 1]
input: [25, 17, 17, 6]
ont-hot input:
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]
output: [0, 31, 32]
target: [31, 32, 1]
input: [9, 3, 15, 7]
ont-hot input:
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]
output: [0, 33, 34]
target: [33, 34, 1]
input: [9, 11, 20, 14]
ont-hot input:
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]
output: [0, 35, 36]
target: [35, 36, 1]
input: [13, 11, 21, 21]
ont-hot input:
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]
output: [0, 37, 38]
target: [37, 38, 1]
input: [14, 17, 24, 7]
ont-hot input:
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]
output: [0, 39, 40]
target: [39, 40, 1]
10.3.3 옵션 설정
-
신경망 모델에서 사용할 하이퍼파라미터, 플레이스홀더, 입출력 변수용 수치들을 정의
-
n_class와n_input: 입출력에 사용할 글자들의 배열 크기인dic_len과 같음
learning_rate = 0.01
n_hidden = 128
total_epoch = 100
n_class = n_input = dic_len
- 인코더의 입력값, 디코더의 입력값, 출력값에 사용할 플레이스홀더 구성
- 인코더와 디코더의 입력값 형식은 아래와 같음
[batch size, time steps, input size]
- 디코더 출력값 형식은 아래와 같음
[batch size, time steps]
10.3.4 입력 데이터 정의
- 신경망 모델 구성 시작
- RNN의 특성상 입력 데이터에 단계가 있음
- 또한 입력값들은 원-핫 인코딩을 사용, 디코더의 출력값은 인덱스 숫자를 그대로 사용 \(\rightarrow\) 입력값의 랭크(차원)가 하나 더 높음
enc_input = tf.placeholder(tf.float32, [None, None, n_input])
dec_input = tf.placeholder(tf.float32, [None, None, n_input])
targets = tf.placeholder(tf.int64, [None, None])
- 입력 단계는 배치 크기처럼 입력받을 때마다 다를 수 있으므로
None으로 설정 - 나중에 영문 4글자나 한글 2글자가 아닌, 길이가 다양한 단어들을 넣어 번역을 할 때엔 같은 배치 때 입력되는 데이터는 글자 수, 즉 단계(time steps)가 모두 같아야 한다는 점을 유의
NOTE
dynamic_rnn의 옵션인sequence_length를 사용하면 길이가 다른 단어들도 한 번에 입력받을 수 있음- 하지만 그래도 입력 데이터의 길이는 같아야 함
- 따라서 입력할 때 짧은 단어는 가장 긴 단어에 맞춰 글자를 채워야 함
- 의미 없는 값인 ‘P’는 이렇게 부족한 글자 수를 채우는 데 사용
10.3.5 RNN 셀 구성
- RNN 모델을 위한 셀 구성
- 인코더 셀과 디코더 셀을 만들어야 함
with tf.variable_scope('encode'):
enc_cell = tf.nn.rnn_cell.BasicRNNCell(n_hidden)
enc_cell = tf.nn.rnn_cell.DropoutWrapper(enc_cell, output_keep_prob=0.5)
outputs, enc_states = tf.nn.dynamic_rnn(enc_cell, enc_input, dtype=tf.float32)
with tf.variable_scope('decode'):
dec_cell = tf.nn.rnn_cell.BasicRNNCell(n_hidden)
dec_cell = tf.nn.rnn_cell.DropoutWrapper(dec_cell, output_keep_prob=0.5)
outputs, dec_states = tf.nn.dynamic_rnn(dec_cell, dec_input, initial_state=enc_states, dtype=tf.float32)
- 셀은 기본 셀 사용
- 각 셀에 드롭아웃을 적용
- 주의할 점 : 디코더를 만들 때 초기 상태 값(입력값이 아님)으로 인코더의 최종 상태 값을 넣어줘야 함
- Sequence to Sequence의 핵심 아이디어 중 하나가 인코더에서 계산한 상태를 디코더로 전파하는 것이기 때문
dynamic_rnn에initial_state=enc_sates옵션을 사용하면 간단하게 처리 가능
10.3.6 출력층 생성 및 손실 함수, 최적화 함수 구성
- 출력층을 위해
layers모듈의dense함수를 사용
model = tf.layers.dense(outputs, n_class, activation=None)
cost = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=model, labels=targets))
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost)
- 이 예제에서는 가중치와 편향을 위한 변수는 하나도 사용하지 않음
- 고수준 API를 사용하면 텐서플로가 귀찮은 부분들을 다 알아서 해줌
10.3.7 신경망 학습
feed_dict으로 전달하는 학습 데이터에 3가지를 입력
(1) 인코더의 입력값
(2) 디코더의 입력값
(3) 디코더의 출력값
sess = tf.Session()
sess.run(tf.global_variables_initializer())
input_batch, output_batch, target_batch = make_batch(seq_data)
for epoch in range(total_epoch):
_, loss = sess.run([optimizer, cost], feed_dict={enc_input: input_batch,
dec_input: output_batch,
targets: target_batch})
print('Epoch: ', '%04d' % (epoch + 1),
'Cost= ', '{:.6f}'.format(loss))
print('최적화 완료!')
Epoch: 0001 Cost= 3.771066
Epoch: 0002 Cost= 2.676501
Epoch: 0003 Cost= 1.819776
Epoch: 0004 Cost= 1.068409
Epoch: 0005 Cost= 0.703591
Epoch: 0006 Cost= 0.332305
Epoch: 0007 Cost= 0.305222
Epoch: 0008 Cost= 0.346191
Epoch: 0009 Cost= 0.125179
Epoch: 0010 Cost= 0.276241
Epoch: 0011 Cost= 0.130254
Epoch: 0012 Cost= 0.290455
Epoch: 0013 Cost= 0.102508
Epoch: 0014 Cost= 0.065501
Epoch: 0015 Cost= 0.080497
Epoch: 0016 Cost= 0.164857
Epoch: 0017 Cost= 0.181879
Epoch: 0018 Cost= 0.098818
Epoch: 0019 Cost= 0.006716
Epoch: 0020 Cost= 0.022849
Epoch: 0021 Cost= 0.024864
Epoch: 0022 Cost= 0.009621
Epoch: 0023 Cost= 0.005824
Epoch: 0024 Cost= 0.005525
Epoch: 0025 Cost= 0.008529
Epoch: 0026 Cost= 0.003608
Epoch: 0027 Cost= 0.007946
Epoch: 0028 Cost= 0.006856
Epoch: 0029 Cost= 0.003377
Epoch: 0030 Cost= 0.002233
Epoch: 0031 Cost= 0.002354
Epoch: 0032 Cost= 0.001673
Epoch: 0033 Cost= 0.001465
Epoch: 0034 Cost= 0.003577
Epoch: 0035 Cost= 0.010194
Epoch: 0036 Cost= 0.004144
Epoch: 0037 Cost= 0.003938
Epoch: 0038 Cost= 0.002713
Epoch: 0039 Cost= 0.001841
Epoch: 0040 Cost= 0.006420
Epoch: 0041 Cost= 0.001922
Epoch: 0042 Cost= 0.002058
Epoch: 0043 Cost= 0.004088
Epoch: 0044 Cost= 0.003834
Epoch: 0045 Cost= 0.001397
Epoch: 0046 Cost= 0.001257
Epoch: 0047 Cost= 0.001413
Epoch: 0048 Cost= 0.000855
Epoch: 0049 Cost= 0.000419
Epoch: 0050 Cost= 0.000606
Epoch: 0051 Cost= 0.000602
Epoch: 0052 Cost= 0.000507
Epoch: 0053 Cost= 0.001443
Epoch: 0054 Cost= 0.000433
Epoch: 0055 Cost= 0.000853
Epoch: 0056 Cost= 0.003651
Epoch: 0057 Cost= 0.000908
Epoch: 0058 Cost= 0.000408
Epoch: 0059 Cost= 0.000866
Epoch: 0060 Cost= 0.004053
Epoch: 0061 Cost= 0.000864
Epoch: 0062 Cost= 0.000722
Epoch: 0063 Cost= 0.000729
Epoch: 0064 Cost= 0.000228
Epoch: 0065 Cost= 0.000269
Epoch: 0066 Cost= 0.001305
Epoch: 0067 Cost= 0.000645
Epoch: 0068 Cost= 0.000549
Epoch: 0069 Cost= 0.000629
Epoch: 0070 Cost= 0.000606
Epoch: 0071 Cost= 0.000945
Epoch: 0072 Cost= 0.001123
Epoch: 0073 Cost= 0.001153
Epoch: 0074 Cost= 0.000268
Epoch: 0075 Cost= 0.000967
Epoch: 0076 Cost= 0.001834
Epoch: 0077 Cost= 0.000941
Epoch: 0078 Cost= 0.000438
Epoch: 0079 Cost= 0.000330
Epoch: 0080 Cost= 0.000832
Epoch: 0081 Cost= 0.000402
Epoch: 0082 Cost= 0.000268
Epoch: 0083 Cost= 0.000290
Epoch: 0084 Cost= 0.003242
Epoch: 0085 Cost= 0.000290
Epoch: 0086 Cost= 0.000218
Epoch: 0087 Cost= 0.000144
Epoch: 0088 Cost= 0.001214
Epoch: 0089 Cost= 0.000545
Epoch: 0090 Cost= 0.000251
Epoch: 0091 Cost= 0.000319
Epoch: 0092 Cost= 0.000518
Epoch: 0093 Cost= 0.000453
Epoch: 0094 Cost= 0.000803
Epoch: 0095 Cost= 0.001079
Epoch: 0096 Cost= 0.000584
Epoch: 0097 Cost= 0.000454
Epoch: 0098 Cost= 0.000165
Epoch: 0099 Cost= 0.000151
Epoch: 0100 Cost= 0.000203
최적화 완료!
10.3.8 번역 단어 예측 함수 - 1) 디코더 입출력값 초기화
-
결과 확인을 위해 단어를 입력받아 번역 단어를 예측하는 함수를 만듬
- 이 모델은 입력값과 출력값 데이터로 [영어 단어, 한글 단어]를 사용하지만, 예측 시에는 한글 단어를 알 지 못할 것
-
디코더의 입출력을 의미 없는 값인 ‘P’로 채워 데이터를 구성
- 입력 = ‘word’ \(\rightarrow\)
seq_data = ['word', 'PPPP']로 구성 input_batch: [‘w’,’o’,’r’,’d’]output_batch: [‘P’,’P’,’P’,’P’] 글자들의 인덱스를 원-핫 인코딩한 값target_batch: [‘P’,’P’,’P’,’P’] 의 각 글자의 인덱스인 [2, 2, 2, 2]가 됨
10.3.9 번역 단어 예측 함수 - 2) 예측 모델 실행
- 세 번째 차원을
argmax로 취해 가장 확률이 높은 글자(의 인덱스)를 예측값으로 만듬 - 세 번째 차원을
argmax로 취하는 이유는 결과값이[batch size, time steps, input size]형태로 나오기 때문
참고
[[[0 0 0.9 0.1 0.2 0.3 0 0 ...],
[0 0.1 0.3 0.7 0.1 0 0 0 ...],
... ]]
- 위의 값이 결과값으로 나온다면 최종 예측 결과인
tf.argmax(model, 2)의 값은 아래와 같아짐
[[[2],
[3],
... ]]
- 중간중간 결괏값을 출력해 보면 조금 더 이해하기가 쉬움
10.3.10 번역 단어 예측 함수 - 3) 예측 결과 리턴
- 예측 결과 = 글자의 인덱스를 뜻하는 숫자
- 각 숫자에 해당하는 글자를 가져와 배열을 만듬
- 그리고 출력의 끝을 의미하는 ‘E’ 이후의 글자들을 제거하고 문자열로 만듬
- 디코더의 입력(time steps) 크기만큼 출력값이 나오므로 최종 결과는 [‘사’, ‘랑’, ‘E’, ‘E’]처럼 나오기 때문
def translate(word):
# 10.3.8 디코더 입출력값 초기화
seq_data = [word, 'P' * len(word)]
input_batch, output_batch, target_batch = make_batch([seq_data])
# 10.3.9 예측 모델 실행
prediction = tf.argmax(model, 2)
result = sess.run(prediction, feed_dict={enc_input: input_batch,
dec_input: output_batch,
targets: target_batch})
# 10.3.10 예측 결과 리턴
decoded = [char_arr[i] for i in result[0]]
end = decoded.index('E')
translated = ''.join(decoded[:end])
return translated
10.3.11 단어 번역 테스트
print('\n=== 번역 테스트 ===')
print('word ->', translate('word'))
print('wodr ->', translate('wodr'))
print('love ->', translate('love'))
print('loev ->', translate('loev'))
print('abcd ->', translate('abcd'))
=== 번역 테스트 ===
word -> 단어
wodr -> 나무
love -> 사랑
loev -> 사랑
abcd -> 사
- 번역 결과, 약간의 오타를 섞은 단어들도 그럴듯하게 번역됨
- 완전히 상관없는 단어에 대해서도, 생뚱맞긴 하지만 그럴듯한 결과를 추측함
-
이렇게 학습하지 않은 데이터를 넣어도 어느 정도 그럴듯한 결과를 내주기 때문에 번역이나 챗봇 등에 매우 유용하게 사용할 수 있음
- 이 모델에서 글자들을 단어로 바꾸면 문장 단위 번역을, 그 후 입력을 질문으로, 출력을 답변으로 하는 데이터를 학습시키면 챗봇을 만들 수 있음
NOTE
- 이 모델을 학습 시키면
ValueError: 'E' is not in list와 같은 에러가 나올 수 있음 - 예측한 결괏값에 출력의 끝을 의미하는 ‘E’가 없을 수 있기 때문
- 관련한 예외처는 코드를 간략하게 만들기 위해 생략함
10.3.12 전체 코드
# 10.3.1
import tensorflow as tf
import numpy as np
char_arr = [c for c in 'SEPabcdefghijklmnopqrstuvwxyz단어나무놀이소녀키스사랑']
num_dic = {n: i for i, n in enumerate(char_arr)}
dic_len = len(num_dic)
seq_data = [['word', '단어'], ['wood', '나무'],
['game', '놀이'], ['girl', '소녀'],
['kiss', '키스'], ['love', '사랑']]
# 10.3.2
def make_batch(seq_data):
input_batch = []
output_batch = []
target_batch = []
for seq in seq_data:
input = [num_dic[n] for n in seq[0]]
output = [num_dic[n] for n in ('S' + seq[1])]
target = [num_dic[n] for n in (seq[1] + 'E')]
input_batch.append(np.eye(dic_len)[input])
output_batch.append(np.eye(dic_len)[output])
# 출력값만 one-hot 인코딩이 아님 (sparse_softmax_cross_entropy_with_logits 사용)
target_batch.append(target)
return input_batch, output_batch, target_batch
##########
# 옵션 설정
##########
# 10.3.3
learning_rate = 0.01
n_hidden = 128
total_epoch = 100
n_class = n_input = dic_len
##########
# 신경망 모델 구성
##########
# 10.3.4
enc_input = tf.placeholder(tf.float32, [None, None, n_input])
dec_input = tf.placeholder(tf.float32, [None, None, n_input])
targets = tf.placeholder(tf.int64, [None, None])
# 10.3.5
with tf.variable_scope('encode'):
enc_cell = tf.nn.rnn_cell.BasicRNNCell(n_hidden)
enc_cell = tf.nn.rnn_cell.DropoutWrapper(enc_cell, output_keep_prob=0.5)
outputs, enc_states = tf.nn.dynamic_rnn(enc_cell, enc_input, dtype=tf.float32)
with tf.variable_scope('decode'):
dec_cell = tf.nn.rnn_cell.BasicRNNCell(n_hidden)
dec_cell = tf.nn.rnn_cell.DropoutWrapper(dec_cell, output_keep_prob=0.5)
outputs, dec_states = tf.nn.dynamic_rnn(dec_cell, dec_input, initial_state=enc_states, dtype=tf.float32)
# 10.3.6
model = tf.layers.dense(outputs, n_class, activation=None)
cost = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=model, labels=targets))
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost)
##########
# 신경망 모델 학습
##########
# 10.3.7
sess = tf.Session()
sess.run(tf.global_variables_initializer())
input_batch, output_batch, target_batch = make_batch(seq_data)
for epoch in range(total_epoch):
_, loss = sess.run([optimizer, cost], feed_dict={enc_input: input_batch,
dec_input: output_batch,
targets: target_batch})
print('Epoch: ', '%04d' % (epoch + 1),
'Cost= ', '{:.6f}'.format(loss))
print('최적화 완료!')
##########
# 번역 테스트
##########
def translate(word):
# 10.3.8
seq_data = [word, 'P' * len(word)]
input_batch, output_batch, target_batch = make_batch([seq_data])
# 10.3.9
prediction = tf.argmax(model, 2)
result = sess.run(prediction, feed_dict={enc_input: input_batch,
dec_input: output_batch,
targets: target_batch})
# 10.3.10
decoded = [char_arr[i] for i in result[0]]
end = decoded.index('E')
translated = ''.join(decoded[:end])
return translated
# 10.3.11
print('\n=== 번역 테스트 ===')
print('word ->', translate('word'))
print('wodr ->', translate('wodr'))
print('love ->', translate('love'))
print('loev ->', translate('loev'))
print('abcd ->', translate('abcd'))
10.4 더 보기
10.4.1 문서 요약
- Seq2Seq 모델로 만들 수 있는 유용한 응용 분야 중 문서 요약이 있음
- 구글은 이 방식에 대해서도 쉽게 응용할 수 있도록 모델을 만들어 둠
- 문서 요약에 관심이 있으면 아래 링크 참고
Sequence-to-Sequence with Attention Model for Text Summarization
10.4.2 Word2Vec
- 딥러닝을 자연어 분석에 사용하고자 한다면, Word2Vec이라는 Word embeddings 모델을 접하게 될 것
- Word2Vec 자체는 딥러닝과 관계가 적지만, 아래 링크에서 소스 참고
Word2Vec
댓글남기기