해당 포스트는 책 “골빈해커의 3분 딥러닝 텐서플로맛”의 12장 “딥마인드가 개발한 강화학습 DQN”을 학습하고 내용을 정리한 글입니다.
딥마인드(DeepMind)
- 2016년 이슈가 됐던 알파고를 만든 곳
DQN
- 딥마인드에서 만든 신경망
- 게임 화면만 보고 게임을 학습하는 신경망
- 2014년에 공개
- DQN으로 아타리 2600용 비디오 게임 49개를 학습시킨 결과, 모두 잘 학습하여 플레이 함
- 그 중 29개는 사람의 평균 기록보다 높은 점수를 보임

- 이번 장에서는 DQN의 개념을 살펴보고 직접 구현한 뒤, 간단한 게임을 학습시켜 봄
12.1 DQN 개념
- DQN (Deep Q-network)
- 강화학습 알고리즘으로 유명한 Q-러닝(Q-learning)을 딥러닝으로 구현했다는 의미
강화학습(reinforcement learning)
- 어떤 환경에서 인공지능 에이전트가 현재 상태(환경)를 판단하여 가장 이로운 행동을 하게 만드는 학습 방법
- 학습 시 이로운 행동을 하면 보상을 주고 해로운 행동을 하면 패널티를 줘서, 학습이 진행될 수 있도록 이로운 행동을 점점 많이 하도록 유도
- 누적된 이득이 최대가 되게 행동하도록 학습이 진행
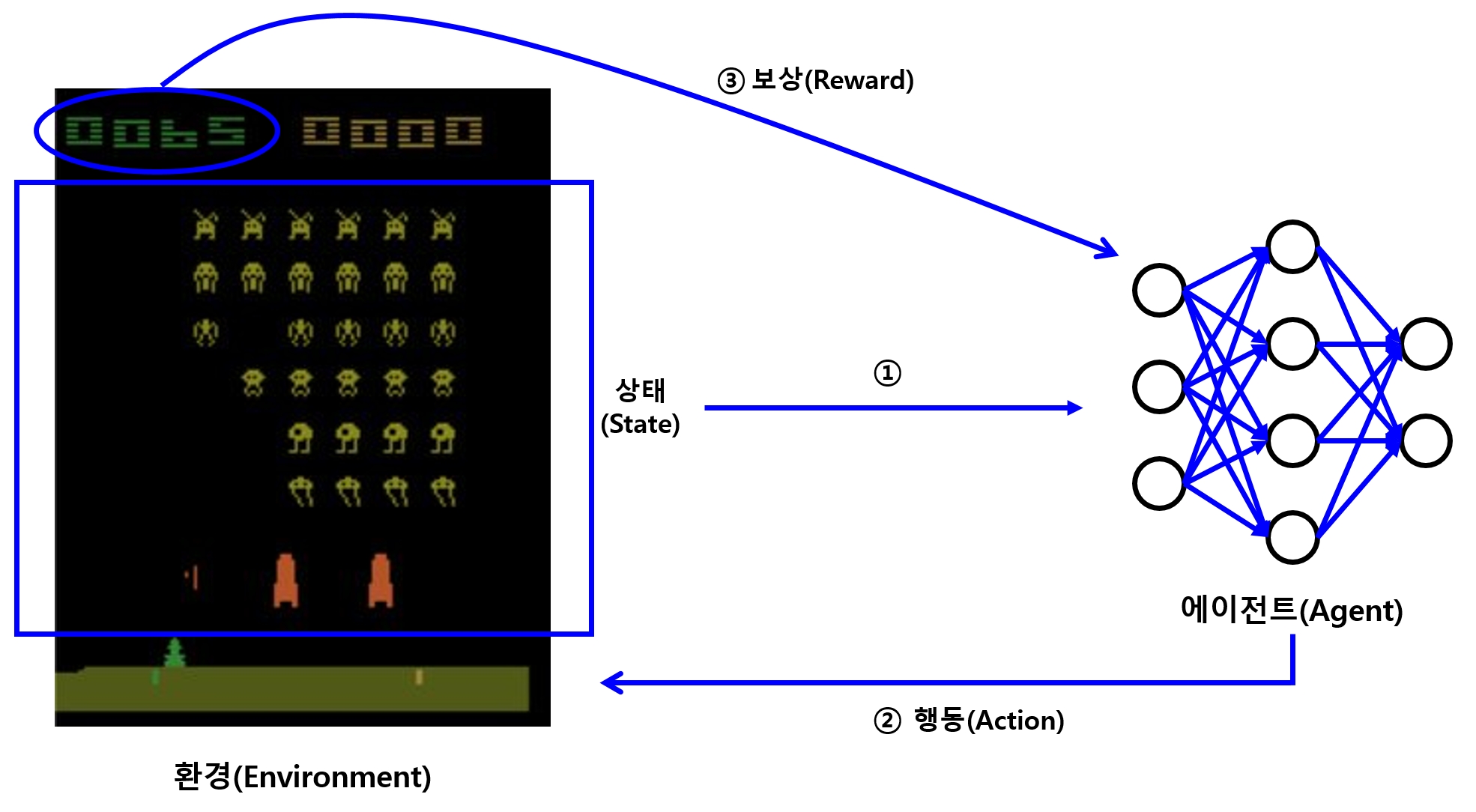
Q-러닝
- 어떠한 상태에서 특정 행동을 했을 때의 가치를 나타내는 함수인 Q 함수를 학습하는 알고리즘
- 즉, 특정 상태에서 이 함수의 값이 최대가 되는 행동을 찾도록 학습
\(\rightarrow\) 그 상태에서 어떤 행동을 취해야 할지 알 수 있게 됨 -
이 Q 함수를 신경망을 활용해 학습하게 한 것이 바로 DQN
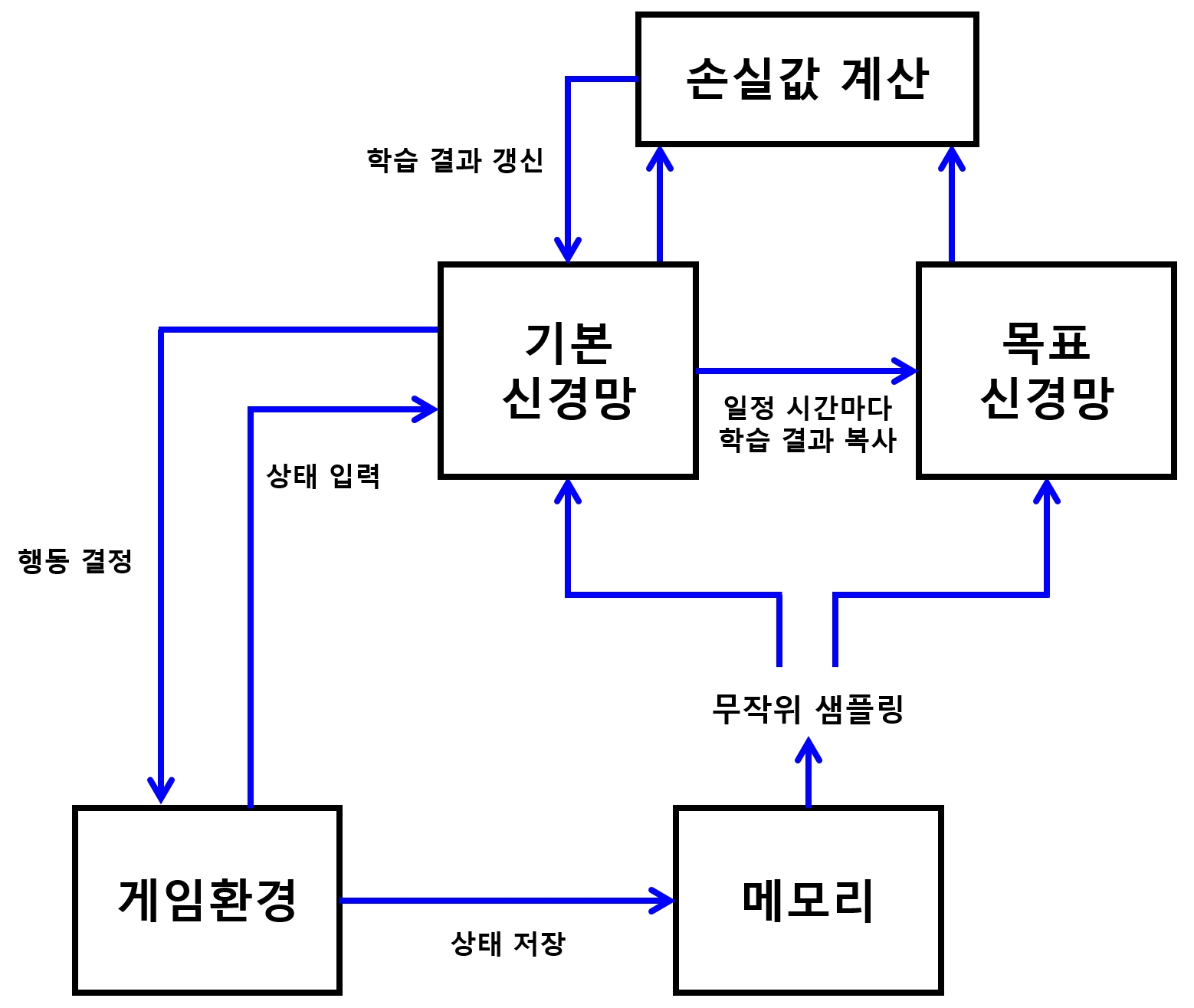
- Q-러닝을 신경망으로 구현하면 학습이 상당히 불안정해짐
- 딥마인드는 다음의 두 방법을 사용하여 이 문제를 해결
(1) 과거의 상태를 기억한 뒤 그중에서 임의의 상태를 뽑아 학습시키는 방법
- 이렇게 하면 특수한 상황에 치우치지 않도록 학습시킬 수 있어서 더 좋은 결과를 나타내는 데 도움이 됨
(2) 기본 신경망과 목표 신경망 분리하는 방법
- 기본 신경망 : 손실값 계산을 위해 학습을 진행하면서 최적의 행동을 얻어내는 신경망
- 목표(target) 신경망 : 얻어낸 값이 좋은 선택인지 비교하는 신경망
-
목표 신경망은 계속 갱신하는 것이 아니라, 기본 신경망의 학습된 결괏값을 일정 주기마다 목표 신경먕에 갱신해 줌
- DQN은 화면의 상태, 즉 화면 영상만으로 게임을 학습
- 따라서 이미지 인식에 뛰어난 CNN을 사용하여 신경망 모델을 구성
12.2 게임 소개
OpenAI
- 인공지능을 연구하는 비영리 회사
- 인공지능의 발전을 위해 다양한 실험을 할 수 있는 Gym이라는 강화학습 알고리즘 개발 도구를 제공
- 이 도구를 이용하면 아타리 게임들을 쉽게 구동할 수 있음
-
다만, 아타리 게임을 학습시키려면 매우 성능 좋은 컴퓨터가 필요하고 시간도 아주 오래 걸림
- 학습을 빠르게 시켜볼 수 있는 간단한 게임으로 실습 진행
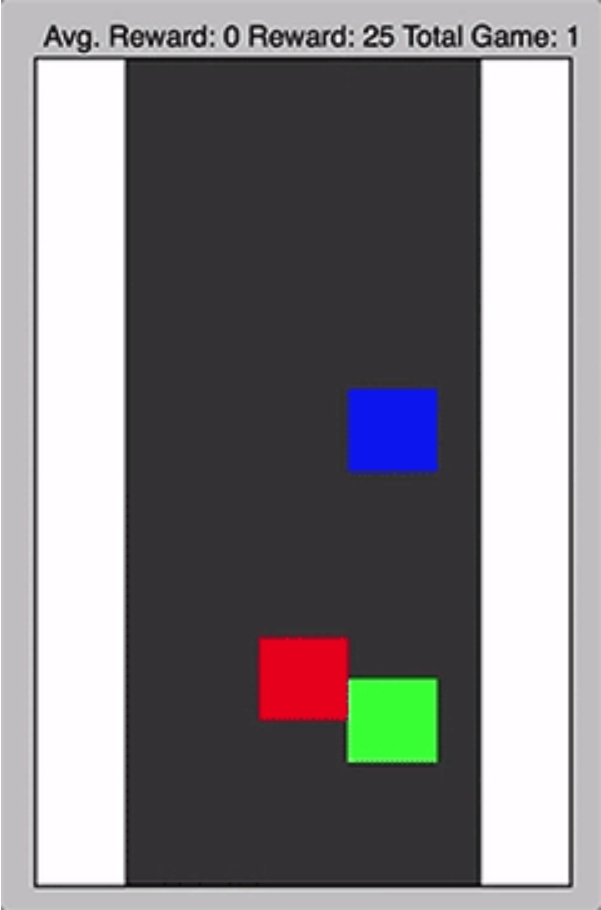
- 아래로 떨어지는 물체를 피하는 간단한 게임
- 검정색 배경 = 도록
- 빨간, 파란색 사각형 = 자동차
-
녹색 사각형 = 자율주행차
- 게임 소스는 깃허브 저장소에서 내려받을 수 있음
- game.py 파일을 내려받아, 앞으로 에이전트를 구현할 소스를 저장할 디렉토리에 같이 저장
-
DQN 모델을 포함한 model.py도 내려받아 같은 디렉토리에 저장
- 신경망을 이용하여 게임의 현재 상태를 토대로 이로운 행동을 선택하는 인공지능 에이전트 만들기
12.3 에이전트 구현하기
에이전트
- 게임의 상태를 입력받아 신경망으로 전달
- 신경망에서 판단한 행동을 게임에 적용해서 다음 단계로 진행
- 그러므로 에이전트가 어떤 식으로 작동하는 지 알아야 신경망 구현 시 이해가 더 수월할 것
- 신경망 모델을 구현하기 전에 에이전트부터 구현
12.3.1 필요한 모듈 Import
- Game 모듈 : 앞서 내려받은 game.py 파일에 정의된 게임 클래스
- 이 모듈은 게임을 진행하고 필요 시 matplotlib을 써서 게임 상태를 화면에 출력
- DQN 모듈 : 다음 절에서 구현할 신경망 모델
import tensorflow as tf
import numpy as np
import random
import time
from game import Game
from model import DQN
12.3.2 학습 모드(train)와 게임 실행 모드(replay) 구분
- 에이전트는 학습 모드(train)와 게임 실행 모드(replay)로 나뉨
- 학습 모드 : 게임을 화면에 보여주지 않은 채 빠르게 실행하여 학습 속도를 높임
-
게임 실행 모드 : 학습한 결과를 이용해서 게임을 진행하면서 화면에도 출력
- 이를 위해 에이전트 실행 시 모드를 나누어 실행할 수 있도록
tf.app.flags를 이용해 실행 시 받을 옵션들을 설정
tf.app.flags.DEFINE_boolean("train", False, "학습모드. 게임을 화면에 보여주지 않습니다.")
FLAGS = tf.app.flags.FLAGS
12.3.3 하이퍼파라미터 설정
MAX_EPISODE = 10000
TARGET_UPDATE_INTERVAL = 1000
TRAIN_INTERVAL = 4
OBSERVE = 100
MAX_EPISODE
- 최대로 학습할 게임 횟수
TRAIN_INTERVAL
- 게임 4프레임(상태)마다 한 번씩 학습하라는 이야기
OBSERVE
- 일정 수준의 학습 데이터가 쌓이기 전에는 학습하지 않고 지켜보기만 하라는 이야기
- 학습 데이터가 적을 때는 학습을 진행해도 효과가 크지 않기 때문
- 100번의 프레임이 지난 뒤부터 학습을 진행
TARGET_UPDATE_INTERVAL
- 학습을 일정 횟수만큼 진행할 때마다 한번씩 목표 신경망을 갱신하라는 옵션
- DQN은 안정된 학습을 위해, 학습을 진행하면서 최적의 행동을 얻어내는 기본 신경망과 얻어낸 값이 좋은 선택인지 비교하는 목표 신경망이 분리
- 가장 최근의 학습 결과나 아주 오래된 학습 결과로 현재의 선택을 비교한다면 적절한 비교가 되지 않을 것
- 따라서 적당한 시점에 최신의 학습 결과로 목표 신경망을 갱신해줘야 함
12.3.4 게임에 필요한 설정
- 게임 자체에 필요한 설정
- 떨어지는 물건을 좌우로 움직이면서 피하는 게임
- 취할 수 있는 행동(
NUM_ACTION) : 좌, 우, 상태유지 (3가지) - 게임 화면 : 가로(
SCREEN_WIDTH) 6칸, 세로(SCREEN_HEIGHT) 10칸으로 설정 - 원래 이 설정은 Game 모듈에 들어있는 것이 맞지만, 이해를 위해 에이전트에 넣었음
NUM_ACTION = 3 # 행동 - 0: 좌, 1: 유지, 2: 우
SCREEN_WIDTH = 6
SCREEN_HEIGHT = 10
- 에이전트는 학습시키는 부분과 학습된 결과로 게임을 실행해보는 두 부분으로 나뉘어 있음
- 학습 부분부터 만들어 봄
12.3.5 에이전트 코드 - 1) 학습
- 텐서플로 세션과 게임 객체, 그리고 DQN 모델 객체를 생성
- 게임 객체 : 화면 크기를 넣어줌
show_game=FALSE: 학습을 빠르게 진행하기 위해 게임을 화면에 출력하지 않는다는 옵션- DQN 객체: 신경망을 학습시키기 위해 텐서플로 세션을 넣어줌
- 화면을 입력받아 CNN을 구성할 것이므로 화면 크기를 넣어 초기 설정을 함
- 가장 중요한 신경망의 최종 결괏값의 개수인 선택할 행동의 개수(
NUM_ACTION)를 넣어줌
12.3.6 에이전트 코드 - 2) 학습 결과 저장 및 학습 상태 확인
(1) 에피소드별 점수 저장
rewards: 에피소드(한 판)마다 얻는 점수를 저장하고 확인하기 위한 텐서- 에피소드 10번에 한 번씩 로그를 저장할 것
- 그때
rewards의 평균을 저장
(2) 학습 결과 저장
- 학습 결과를 저장하기 위해
tf.train.Saver와 텐서플로 세션, 그리고 로그를 저장하기 위한tf.summary.FileWriter객체를 생성 - 학습 상태를 확인하기 위한 값들을 모아서 저장하기 위한 텐서를 설정
12.3.7 에이전트 코드 - 3) 목표 신경망 초기화
- 목표 신경망을 한 번 초기화해줌
- 아직 학습된 결과가 없으므로, 여기서 목표 신경망의 값은 초기화된 기본 신경망의 값과 같음
12.3.8 에이전트 코드 - 4) DQN 이용 시점 설정 및 진행 상태와 결과 저장 값 초기화
(1) DQN 이용 시점
- 행동을 선택할 때 DQN을 이용할 시점을 정함
- 학습 초반에는 DQN이 항상 같은 값만 내놓을 가능성이 높음
- 따라서 일정 시간이 지나기 전에는 행동을 무작위로 선택해야 함
- 이를 위해 게임 진행 중에
epsilon(입실론)값을 줄여나가는 코드 입력
(2) 학습 진행 상태
- 학습 진행을 조절하기 위해 진행된 프레임(상태) 횟수 초기화
(3) 점수 저장 배열
- 학습 결과를 확인하기 위해 점수들을 저장할 배열을 초기화
12.3.9 에이전트 코드 - 5) 학습 진행 및 학습
- 게임을 진행하고 학습시키는 부분을 작성
- 앞서 설정한
MAX_EPISODE횟수만큼 게임 에피소드를 진행 - 매 게임을 시작하기 전에 초기화
(1) 게임 종료 상태 : terminal
(2) 한 게임당 얻은 총 점수 : total_reward
(3) 게임 상태 초기화 : game.reset()
(4) DQN 초기 상태값 설정
- 초기화한 게임 상태를 DQN에 초기 상탯값으로 넣어 줌
- 상태는 screen_width * screen_height 크기의 화면 구성
NOTE
- 원래 DQN에서는 픽셀값들을 상탯값으로 받음
- 여기서 사용하는 Game 모듈에서는 학습 속도를 높이고자 해당 위치에 사각형이 있는 지 없는지를 1과 0으로 전달
12.3.10 에이전트 코드 - 6) 최초 게임 진행
- 게임 에피소드를 한 번 진행
- 녹색 사각형이 다른 사각형에 충돌할때까지 진행
- 게임에서 처음으로 해야 할 일 : 다음에 취할 행동을 선택하는 일
- 학습 초반에는 행동을 무작위로 선택
- 일정 시간(에피소드 100번)이 지난 뒤
epsilon값을 조금씩 줄여나감 - 그러면 초반에는 대부분 무작위 값을 사용하다가, 무작위 값을 사용하는 비율이 점점 줄어들어, 나중에는 거의 사용하지 않게 됨
- 이 값들도 하이퍼파라미터임 (실험적으로 잘 조절)
12.3.11 에이전트 코드 - 7) 결정한 행동 이용 게임 진행
- 앞서 결정한 행동을 이용해 게임을 진행하고, 보상과 게임의 종료 여부를 받아옴
12.3.12 에이전트 코드 - 8) 현재 상태 신경망 객체에 기억
- 현재 상태를 신경망 객체에 기억
- 이 기억한 현재 상태를 이용해 다음 상태에서 취할 행동을 정함
- 또한 여기서 저장한 상태, 행동, 보상들을 이용하여 신경망을 학습시킬 것
12.3.13 에이전트 코드 - 9) 현재 프레임값별 학습 진행
- 현재 프레임이 100번(
OBSERVE)이 넘으면 4프레임(TRAIN_INTERVAL)마다 한 번씩 학습을 진행 - 또한 1,000프레임(
TARGET_UPDATE_INTERVAL)마다 한 번씩 목표 신경망을 갱신
12.3.14 에이전트 코드 - 10) 에피소드 종료
- 사각형들이 충돌해 에피소드(게임)가 종료되면 획득한 점수를 출력하고 이번 에피소드에서 받은 점수를 저장
- 에피소드 10번마다 받은 점수를 로그에 저장
- 100번마다 학습된 모델을 저장
# 에이전트
def train():
# 12.3.5 학습
print("뇌세포 깨우는 중...")
sess = tf.Session()
game = Game(SCREEN_WIDTH, SCREEN_HEIGHT, show_game=False)
brain = DQN(sess, SCREEN_WIDTH, SCREEN_HEIGHT, NUM_ACTION)
# 12.3.6 학습 결과 저장 및 학습 상태 확인
## (1) 에피소드별 점수 저장
rewards = tf.placeholder(tf.float32, [None])
tf.summary.scalar('avg.reward/ep.', tf.reduce_mean(rewards))
## (2) 학습 결과 저장
saver = tf.train.Saver()
sess.run(tf.global_variables_initializer())
writer = tf.summary.FileWriter('logs', sess.graph)
summary_merged = tf.summary.merge_all()
# 12.3.7 목표 신경망 초기화
brain.update_target_network()
# 12.3.8 DQN 이용 시점 설정 및 진행 상태와 결과 저장 값 초기화
## (1) DQN 이용 시점
epsilon = 1.0
## (2) 학습 진행 상태
time_step = 0
## (3) 점수 저장 배열
total_reward_list = []
# 12.3.9 학습 진행 및 학습
for episode in range(MAX_EPISODE):
## (1) 게임 종료 상태
terminal = False
## (2) 한 게임당 얻은 총 점수
total_reward = 0
## (3) 게임 상태 초기화
state = game.reset()
## (4) DQN 초기 상태 설정
brain.init_state(state)
# 12.3.10 최초 게임 진행
while not terminal:
if np.random.rand() < epsilon: # 입실론이 랜덤값보다 작은 경우에는 랜덤한 액션을 선택
action = random.randrange(NUM_ACTION)
else: # 그 이상일 경우에는 DQN을 이용해 액션을 선택
action = brain.get_action()
# 일정 시간이 지난 뒤부터 입실론 값을 줄임 (초반에는 학습이 전혀 안되어 있기 때문)
if episode > OBSERVE:
epsilon -= 1 / 1000
# 12.3.11 결정한 행동 이용 게임 진행
state, reward, terminal = game.step(action)
total_reward += reward
# 12.3.12 현재 상태 신경망 객체에 기억
brain.remember(state, action, reward, terminal)
# 12.3.13 현재 프레임값별 학습 진행
if time_step > OBSERVE and time_step % TRAIN_INTERVAL == 0:
brain.train()
if time_step % TARGET_UPDATE_INTERVAL == 0:
brain.update_target_network()
time_step += 1
# 12.3.14 에피소드 종료
print('게임횟수: %d 점수: %d' % (episode + 1, total_reward))
total_reward_list.append(total_reward)
if episode % 10 == 0:
summary = sess.run(summary_merged, feed_dict={rewards: total_reward_list})
writer.add_summary(summary, time_step)
total_reward_list = []
if episode % 100 == 0:
saver.save(sess, 'model/dqn.ckpt', global_step=time_step)
12.3.15 학습 결과 실행 함수 - 1) 결과 실행
- 결과를 실행하는
replay()함수는 학습 부분만 빠져있을 뿐train()함수와 거의 같음 - 주의할 점은 텐서플로 세션을 새로 생성하지 않고,
tf.train.Saver()로 저장해둔 모델을 읽어와서 생성한다는 것
12.3.16 학습 결과 실행 함수 - 2) 게임 진행
- 게임을 진행하는 부분
- 학습 코드가 빠져있어 매우 단순함
- 게임 진행을 인간이 인지할 수 있는 속도로 보여주기 위해 마지막 부분에
time.sleep(0.3)코드를 추가함
def replay():
# 12.3.15 결과 실행
print('뇌세포 깨우는 중...')
sess = tf.Session()
game = Game(SCREEN_WIDTH, SCREEN_HEIGHT, show_game=True)
brain = DQN(sess, SCREEN_WIDTH, SCREEN_HEIGHT, NUM_ACTION)
saver = tf.train.Saver()
ckpt = tf.train.get_checkpoint_state('model')
saver.restore(sess, ckpt.model_checkpoint_path)
# 12.3.16 게임 진행
for episode in range(MAX_EPISODE):
terminal = False
total_reward = 0
state = game.reset()
brain.init_state(state)
while not terminal:
action = brain.get_action()
state, reward, terminal = game.step(action)
total_reward += reward
brain.remember(state, action, reward, terminal)
time.sleep(0.3)
print('게임횟수: %d 점수: %d' % (episode + 1, total_reward))
12.3.17 게임 진행 방법 선택
- 스크립트 학습용으로 실행할 지, 학습된 결과로 게임을 진행할 지 선택하는 부분
- 터미널(명령 프롬프트)에서 스크립트를 실행할 때 train 옵션을 받아 정하게 함
def main(_):
if FLAGS.train:
train()
else:
replay()
if __name__ == '__main__':
tf.app.run()
12.3.18 전체 코드
# 12.3.1
import tensorflow as tf
import numpy as np
import random
import time
from game import Game
from model import DQN
# 12.3.2
tf.app.flags.DEFINE_boolean("train", False, "학습모드. 게임을 화면에 보여주지 않습니다.")
FLAGS = tf.app.flags.FLAGS
# 12.3.3
MAX_EPISODE = 10000
TARGET_UPDATE_INTERVAL = 1000
TRAIN_INTERVAL = 4
OBSERVE = 100
# 12.3.4
NUM_ACTION = 3 # 행동 - 0: 좌, 1: 유지, 2: 우
SCREEN_WIDTH = 6
SCREEN_HEIGHT = 10
def train():
# 12.3.5
print("뇌세포 깨우는 중...")
sess = tf.Session()
game = Game(SCREEN_WIDTH, SCREEN_HEIGHT, show_game=False)
brain = DQN(sess, SCREEN_WIDTH, SCREEN_HEIGHT, NUM_ACTION)
# 12.3.6
rewards = tf.placeholder(tf.float32, [None])
tf.summary.scalar('avg.reward/ep.', tf.reduce_mean(rewards))
saver = tf.train.Saver()
sess.run(tf.global_variables_initializer())
writer = tf.summary.FileWriter('logs', sess.graph)
summary_merged = tf.summary.merge_all()
# 12.3.7
brain.update_target_network()
# 12.3.8
epsilon = 1.0
time_step = 0
total_reward_list = []
# 12.3.9
for episode in range(MAX_EPISODE):
terminal = False
total_reward = 0
state = game.reset()
brain.init_state(state)
# 12.3.10
while not terminal:
if np.random.rand() < epsilon:
action = random.randrange(NUM_ACTION)
else:
action = brain.get_action()
if episode > OBSERVE:
epsilon -= 1 / 1000
# 12.3.11
state, reward, terminal = game.step(action)
total_reward += reward
# 12.3.12
brain.remember(state, action, reward, terminal)
# 12.3.13
if time_step > OBSERVE and time_step % TRAIN_INTERVAL == 0:
brain.train()
if time_step % TARGET_UPDATE_INTERVAL == 0:
brain.update_target_network()
time_step += 1
# 12.3.14
print('게임횟수: %d 점수: %d' % (episode + 1, total_reward))
total_reward_list.append(total_reward)
if episode % 10 == 0:
summary = sess.run(summary_merged, feed_dict={rewards: total_reward_list})
writer.add_summary(summary, time_step)
total_reward_list = []
if episode % 100 == 0:
saver.save(sess, 'model/dqn.ckpt', global_step=time_step)
def replay():
# 12.3.15
print('뇌세포 깨우는 중...')
sess = tf.Session()
game = Game(SCREEN_WIDTH, SCREEN_HEIGHT, show_game=True)
brain = DQN(sess, SCREEN_WIDTH, SCREEN_HEIGHT, NUM_ACTION)
saver = tf.train.Saver()
ckpt = tf.train.get_checkpoint_state('model')
saver.restore(sess, ckpt.model_checkpoint_path)
# 12.3.16
for episode in range(MAX_EPISODE):
terminal = False
total_reward = 0
state = game.reset()
brain.init_state(state)
while not terminal:
action = brain.get_action()
state, reward, terminal = game.step(action)
total_reward += reward
brain.remember(state, action, reward, terminal)
time.sleep(0.3)
print('게임횟수: %d 점수: %d' % (episode + 1, total_reward))
# 12.3.17
def main(_):
if FLAGS.train:
train()
else:
replay()
if __name__ == '__main__':
tf.app.run()
12.4 신경망 모델 구현하기
- 게임을 진행하고 신경망을 학습할 에이전트까지 구현 완료
- 이제 DQN을 구현
12.4.1 DQN 구현에 필요한 모듈 Import
import tensorflow as tf
import numpy as np
import random
from collections import deque
- 지금까지 작성해온 코드와 다르게 DQN은 파이썬 클래스로 작성
- 과거의 상태들을 기억하고 사용하는 기능을 조금 더 구조적으로 만들고, 기능별로 나누어 이해와 수정을 쉽게 하기 위함
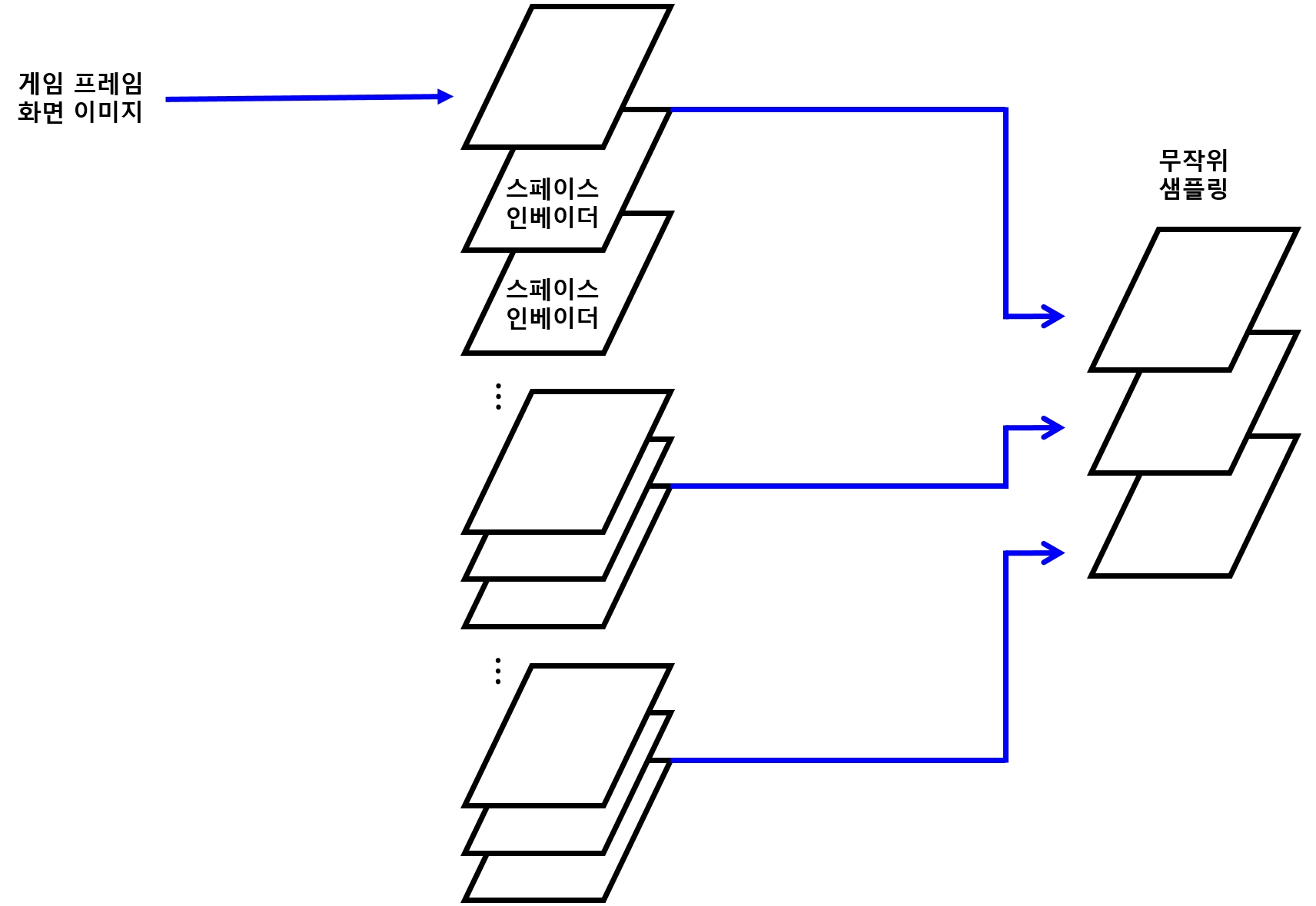
12.4.2 하이퍼파라미터
REPLAY_MEMORY
- 학습에 사용할 플레이 결과를 얼마나 많이 저장해서 사용할 지를 정함
BATCH_SIZE
- 한번 학습할 때 몇 개의 기억응ㄹ 사용할지를 정함
- 미니배치의 크기
GAMMA
- 오래된 상태의 가중치를 줄이기 위한 하이퍼파라미터
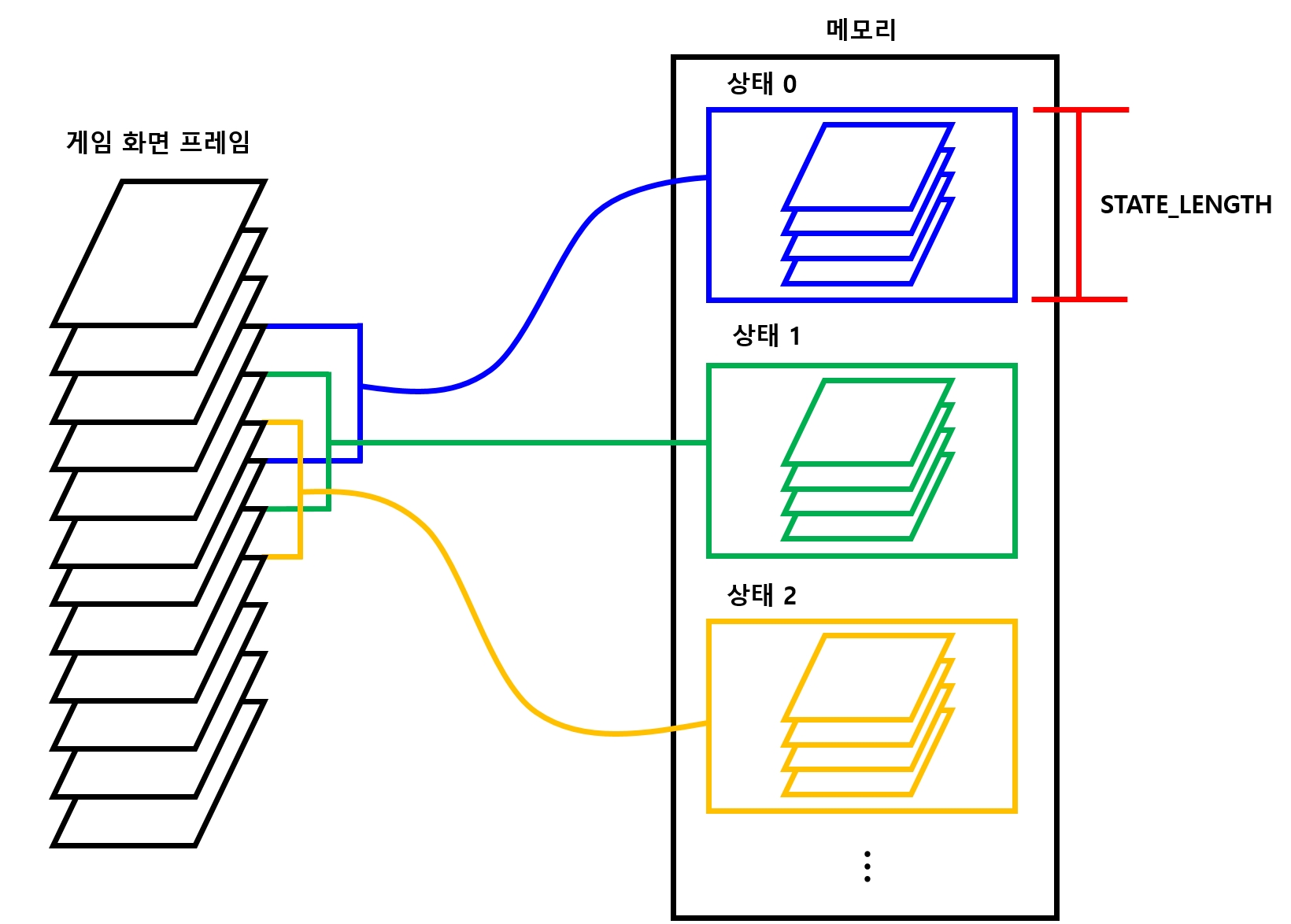
STATE_LEN
- 한 번에 볼 프레임의 총 수
- 에이전트에서 DQN에 상태를 넘겨줄 때는 한 프레임의 상태만 넘겨줌
- 다만, DQN이 상태를 받으면 해당 상태만이 아니라
STATE_LEN - 1개의 앞 상태까지 고려해서 현재의 상태로 만들어 저장 - 즉, 이전 상태까지 고려하는 것
- 다음 그림 참고
12.4.3 DQN 객체 초기화
- DQN 객체를 초기화
- 텐서플로 세션과 가로/세로 크기, 그리고 행동의 개수를 받아 객체를 초기화
self.memory = deque()
- 게임 플레이 결과를 저장할 메모리를 만드는 코드
collections모듈의deque()함수로 만들어진 객체는 배열과 비슷하지만, 맨 처음 들어간 요소를 쉽게 제거해주는popleft함수를 제공- 저장할 기억의 개수를 제한하는 데 사용
12.4.4 플레이스홀더 설정
- 각 변수는 다음 용도로 사용
input_X
- 게임의 상태를 입력 받음
- 구조 : [게임판의 가로 크기, 게임판의 세로 크기, 게임 상태의 개수(현재+과거+과거+…)] 형식
input_A
- 각 상태를 만들어낸 액션의 값을 입력 받음
- 원-핫 인코딩이 아닌 행동을 나타내는 숫자를 그대로 받아서 사용
input_Y
- 손실값 계산에 사용할 값을 입력 받음
- 보상에 목표 신경망으로 구한 다음 상태의 Q 값을 더한 값
- 여기에서 학습 신경망에서 구한 Q 값을 뺀 값을 손실값으로 하여 학습 진행
Q 값
- 행동에 따른 가치를 나타내는 값
- 목표 신경망에서 구한 Q 값 : 구한 값 중 최대의 값(최적 행동) 사용
- 학습 신경망에서 구한 Q 값 : 현재 행동에 따른 값을 사용
-
이렇게 하면 행동을 선택할 때 가장 가치가 높은 행동을 선택하도록 학습할 것
- 뒤에 나올
train함수와_build_op함수의 Q_value 값들을 참조
12.4.5 신경망 구성
- 학습을 진행할 신경망과 목표 신경망 구성
- 두 신경망은 구성이 같음 \(\rightarrow\) 신경망을 구성하는 함수는 같은 것을 사용하되 이름만 다르게 지었음
- 목표 신경망은 단순히 Q 값을 구하는 데만 사용 (손실값과 최적화 함수를 사용하지 않음)
NOTE
- 학습 신경망
- 학습을 진행할 때마다 가중치들이 갱신되므로 학습 신경망이라고 함
- 이 신경망이 실제 게임을 진행할 때 행동을 예측하는 데 사용하는 주 신경망
- 목표 신경망
- 학습 시에만 보조적으로 사용하는 신경망
12.4.6 신경망 구성 함수 정의
_build_network
- 앞서 나온 학습 신경망과 목표 신경망을 구성하는 함수
- 상탯값
input_X를 받아 행동의 가짓수만큼의 출력값을 만듬 -
이 값들의 최댓값을 취해 다음 행동을 정할 것
- 이 신경망 모델은 일반적인 간단한 CNN으로 되어 있음
- 특이한 점 : 풀링 계층이 없다는 것
- 표현력을 높여 이미지의 세세한 부분까지 판단하도록 하기 위해서임
- 게임 환경에 따라 CNN의 필터 크기나 층수를 조절해야 좋은 결과를 얻을 수 있음
12.4.7 DQN 손실 함수 정의
- 현재 상태를 이용해 학습 신경망으로 구한 Q_value와 다음 상태를 이용해 목표 신경망으로 구한 Q_value(
input_Y)를 이용하여 손실값을 구하고 최적화
tf.multiply(self.Q, one_hot) 함수
self.Q로 구한 값에서 현재 행동의 인덱스에 해당하는 값만 선택하기 위해 사용
one_hot
- 현재 행동의 인덱스에 해당하는 값에만 1, 나머지에는 0이 들어있음
Q값과one_hot값을 곱하면 현재 행동의 인덱스에 해당하는 값만 남고 나머지는 전부 0이 됨
12.4.8 목표 신경망 갱신 함수
- 학습 신경망의 변수들의 값을 목표 신경망으로 복사해서 목표 신경망의 변수들을 최신 값으로 갱신하는 것
12.4.9 다음 행동 정의 함수
get_action
- 현재 상태를 이용해 다음에 취해야 할 행동을 찾는 함수
_build_network함수에서 계산한Q_value를 이용-
출력값이 원-핫 인코딩되어 있으므로
np.argmax함수를 이용해 최댓값이 담긴 index 값을 행동값으로 취함 - 학습에 필요한 텐서와 연산이 모두 준비됨
요약
- CNN을 사용한 신경망으로 Q_value 구함
- 이 Q_value를 이용해 학습에 필요한 손실 함수를 만듬
- 그리고 DQN의 핵심인 목표 신경망을 학습 신경망의 값으로 갱신
- Q_value를 이용해 다음 행동을 판단
12.4.10 학습 함수
1) 메모리에서 값 가져오기
_sample_memory함수를 사용해 게임 플레이를 저장한 메모리에서 배치 크기만큼을 샘플링하여 가져옴
(_sample_memory함수 설명은 뒤에 나옴)
2) target_Q_value 구하기
- 가져온 메모리에서 다음 상태를 만들어 목표 신경망에 넣어
target_Q_value를 구함 - 현재 상태가 아닌 다음 상태를 넣는다는 점에 유의
3) 손실 함수에 보상값 입력
- 앞서 만든 손실 함수에 보상값을 입력
- 단, 게임이 종료된 상태 \(\rightarrow\) 보상값을 바로 입력
- 게임이 진행 중인 상태 \(\rightarrow\) 보상값에
target_Q_value의 최댓값을 추가하여 넣음
(현재 상황에서의 최대 가치를 목표로 삼기 위함)
4) 최적화 함수 실행
AdamOptimizer를 이용한 최적화 함수에 게임 플레이 메모리에서 가져온 값들과 앞에서 구한 Y 값을 넣어 학습 시킴
메모리에서 가져온 값
- 현재 상태값
-
취한 행동
- 몇 가지 헬퍼 함수들을 만듬
헬퍼 함수들
init_state: 학습에 사용할 상태값을 만드는 함수remember: 메모리에 저장하는 함수_sample_memory: 추출해오는 함수
12.4.11 현재 상태 초기화 함수
init_state: 현재의 상태를 초기화하는 함수- DQN에서 입력값으로 사용할 상태 = 게임판의 현재 상태 + 앞의 상태 몇 개를 합친 것
- 이를 입력값으로 만들기 위해
STATE_LEN크기만큼의 스택으로 만들어 둠
np.stack(state, axis=2)
- 스택을 만들면서
axis=2옵션을 준 것은input_X를 넣을 플레이스홀더를[None, width, height, self.STATE_LEN]구성으로 만들었기 때문 - 즉, 상태들을 마지막 차원으로 쌓아올린 형태로 만들었기 때문
- 이렇게 해야 컨볼루션 계층을 손쉽게 이용할 수 있음
12.4.12 게임 플레이 결과를 메모리에 기억시키는 함수
remember 함수
- 게임 플레이 결과를 받아 메모리에 기억하는 기능을 수행
- 가장 오래된 상태를 제거
- 새로운 상태를 넣어 다음 상태로 만들어 둠
- 입력받은 새로운 상태가 DQN으로 취한 행동을 통해 만들어진 상태이므로 실제로는 다음 상태라고 볼 수 있기 때문
메모리에 저장하는 값들
- 게임의 현재 상태
- 게임의 다음 상태
- 취한 행동
- 그 행동으로 얻어진 보상
- 게임 종료 여부
저장할 플레이 개수 제한
- 너무 오래된 과거까지 기억하려면 메모리가 부족할 수도 있고, 학습에도 효율적이지 않으므로 저장할 플레이 개수를 제한
12.4.13 임의의 메모리를 가져오는 함수
_sample_memory 함수
- 기억해둔 게임 플레이에서 임의의 메모리를 배치 크기만큼 가져옴
random.sample함수를 통해 임의의 메모리를 가져옴- 그 중 첫 번째 요소를 현재 상태값으로, 두 번째를 다음 상태값으로, 그리고 취한 행동, 보상, 게임 종료 여부를 순서대로 가져옴
- 그런 다음 사용하기 쉽도록 재구성하여 넘겨줌
class DQN:
# 12.4.2 하이퍼파라미터
REPLAY_MEMORY = 10000
BATCH_SIZE = 32
GAMMA = 0.99
STATE_LEN = 4
# 12.4.3 DQN 객체 초기화
def __init__(self, session, width, height, n_action):
self.session = session
self.n_action = n_action
self.width = width
self.height = height
self.memory = deque()
self.state = None
# 12.4.4 플레이스홀더 설정
self.input_X = tf.placeholder(tf.float32, [None, width, height, self.STATE_LEN])
self.input_A = tf.placeholder(tf.int64, [None])
self.input_Y = tf.placeholder(tf.float32, [None])
# 12.4.5 신경망 구성
self.Q = self._build_network('main')
self.cost, self.train_op = self._build_op()
self.target_Q = self._build_network('target')
# 12.4.6 신경망 구성 함수 정의
def _build_network(self, name):
with tf.variable_scope(name):
model = tf.layers.conv2d(self.input_X, 32, [4, 4], padding='same', activation=tf.nn.relu)
model = tf.layers.conv2d(model, 64, [2, 2], padding='same', activation=tf.nn.relu)
model = tf.contrib.layers.flatten(model)
model = tf.layers.dense(model, 512, activation=tf.nn.relu)
Q = tf.layers.dense(model, self.n_action, activation=None)
return Q
# 12.4.7 DQN 손실 함수 정의
def _build_op(self):
one_hot = tf.one_hot(self.input_A, self.n_action, 1.0, 0.0)
Q_value = tf.reduce_sum(tf.multiply(self.Q, one_hot), axis=1)
cost = tf.reduce_mean(tf.square(self.input_Y - Q_value))
train_op = tf.train.AdamOptimizer(1e-6).minimize(cost)
return cost, train_op
# 12.4.8 목표 신경망 갱신 함수
def update_target_network(self):
copy_op = []
main_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='main')
target_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='target')
for main_var, target_var in zip(main_vars, target_vars):
copy_op.append(target_var.assign(main_var.value()))
self.session.run(copy_op)
# 12.4.9 다음 행동 정의 함수
def get_action(self):
Q_value = self.session.run(self.Q, feed_dict={self.input_X: [self.state]})
action = np.argmax(Q_value[0])
return action
# 12.4.11 현재 상태 초기화 함수
def init_state(self, state):
state = [state for _ in range(self.STATE_LEN)]
self.state = np.stack(state, axis=2)
# 12.4.12 게임 플레이 결과를 메모리에 기억시키는 함수
def remember(self, state, action, reward, terminal):
next_state = np.reshape(state, (self.width, self.height, 1))
next_state = np.append(self.state[:, :, 1:], next_state, axis=2)
self.memory.append((self.state, next_state, action, reward, terminal))
if len(self.memory) > self.REPLAY_MEMORY:
self.memory.popleft()
self.state = next_state
# 12.4.13 임의의 메모리 가져오는 함수
def _sample_memory(self):
sample_memory = random.sample(self.memory, self.BATCH_SIZE)
state = [memory[0] for memory in sample_memory]
next_state = [memory[1] for memory in sample_memory]
action = [memory[2] for memory in sample_memory]
reward = [memory[3] for memory in sample_memory]
terminal = [memory[4] for memory in sample_memory]
return state, next_state, action, reward, terminal
# 12.4.10 학습 함수
def train(self):
# 1) 메모리에서 값 가져오기
state, next_state, action, reward, terminal = self._sample_memory()
# 2) target_Q_value 구하기
target_Q_value = self.session.run(self.target_Q, feed_dict={self.input_X: next_state})
# 3) 손실 함수에 보상값 입력
Y = []
for i in range(self.BATCH_SIZE):
if terminal[i]:
Y.append(reward[i])
else:
Y.append(reward[i] + self.GAMMA + np.max(target_Q_value[i]))
# 4) 최적화 함수 실행
self.session.run(self.train_op, feed_dict={self.input_X: state,
self.input_A: action,
self.input_Y: Y})
12.5 학습시키기
- 소스 파일이 있는 곳에서 터미널(명령 프롬프트)에서 다음 명령을 입력
python agent.py --train
주의할 점
-
코드가 있는 곳에
logs와model디렉토리를 미리 만들어둬야 함
(해당 디렉토리에 게임 점수에 대한 로그와 학습된 모델을 저장하기 때문 - 학습이 꽤 오랜 시간동안 진행됨
- 학습이 어느 정도 진행되면 다음처럼 점수가 많이 나면서 한 에피소드가 끝나기까지 굉장히 오래 걸릴 것
- 코드를 간략하게 하기 위해 학습 횟수를 에피소드의 횟수로 정했기 때문에 영원히 끝나지 않을 수도 있음
-
학습된 모델을 중간중간 저장하고 있으니 어느 정도 적당한 수준이 됐다고 생각되면
Ctrl + C를 눌러 강제로 종료시키면 됨 - 학습이 많이 진행되지 않았더라도 학습을 종료한 뒤 다음 명령을 이용하여 결과를 확인해볼 수 있음
python agent.py
- 초기 단계, 중간 단계, 학습이 많이 진행된 단계마다 실행
텐서보드 사용
- 텐서보드를 사용하면 언제부터 얼마나 똑똑해 졌는 지를 더 정확하게 확인할 수 있음
- 다음 명령으로 텐서보드를 띄워 게임 점수가 높아지는 모습을 그래프로 확인
tensorboard --logdir=./logs
12.6 더 보기
- 이 책에는 수식에 대한 자세한 설명은 포함되어 있지 않음
- 하지만 딥러닝을 본격적으로 공부하려면 이론도 자세히 공부하는 것이 좋음
- 김성훈 교수님의 강좌를 통해 이론을 더 깊게 공부해볼 수 있음
댓글남기기