해당 포스트는 책 “골빈해커의 3분 딥러닝 텐서플로맛”의 7장 “이미지 인식의 은총알 CNN”을 학습하고 내용을 정리한 글입니다.
합성곱 신경망 (CNN; Convolutional Neural Network)
- 1998년 얀 레쿤(Yann LeCun) 교수가 소개한 이래로 널리 사용되고 있는 신경망
- 이미지 인식 분야에서는 강력한 성능을 발휘
- 최근에는 음성인식이나 자연어 처리에도 사용됨
- 활용성에서도 매우 뛰어난 성과를 보여주고 있음
7.1 CNN 개념
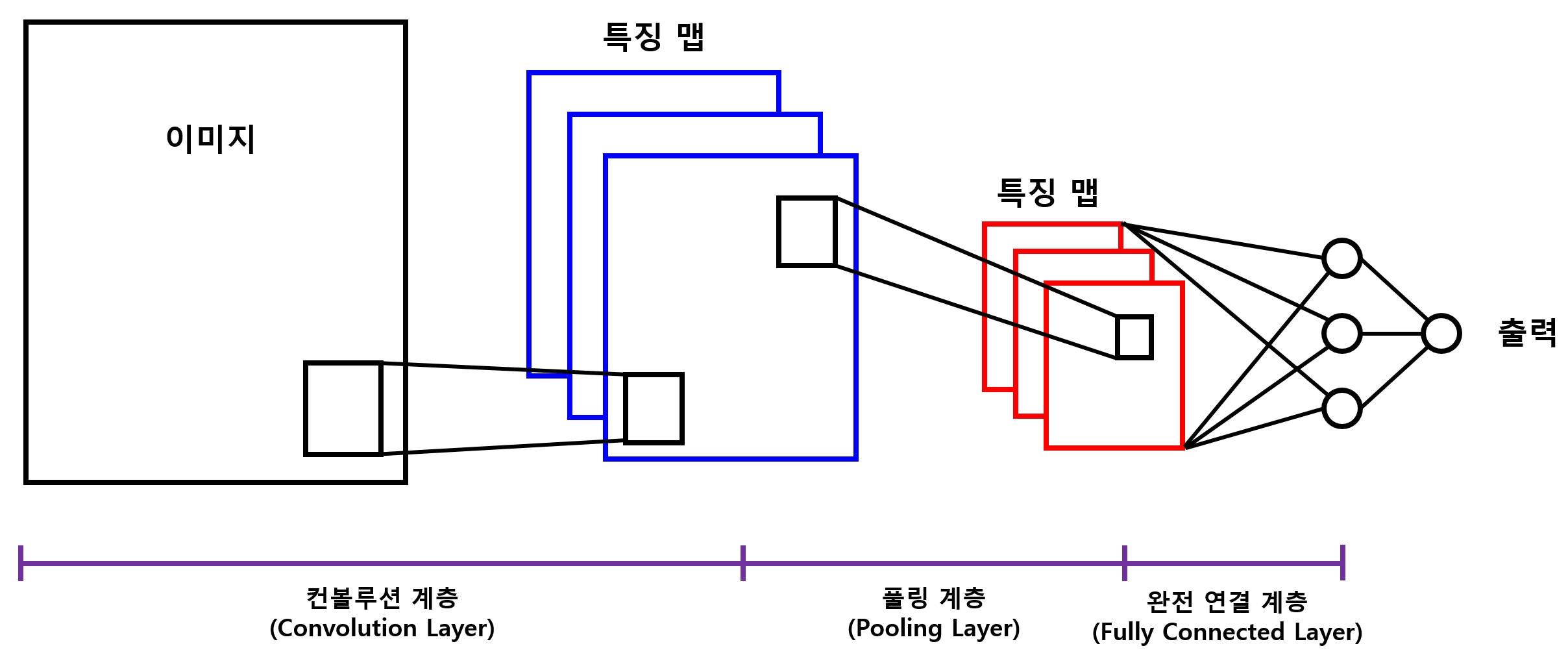
7.1.1 CNN 모델 구성
- 컨볼루션 계층(convolution layer, 합성곱 계층)
- 풀링 계층 (pooling layer)
-
이 계층들을 얼마나 많이, 또 어떠한 방식으로 쌓느냐에 따라 성능 차이는 물론 풀 수 있는 문제가 달라질 수 있다.
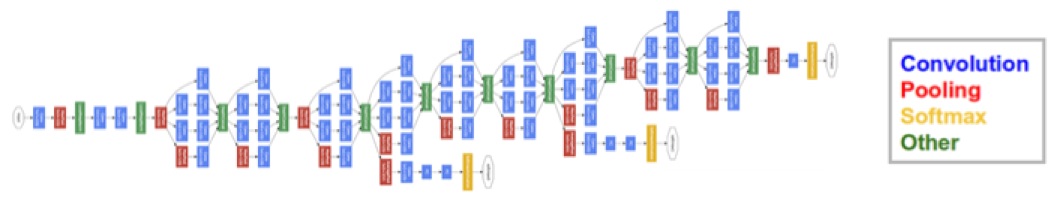
- ex) 구글 인셉션 모델의 계층 구성
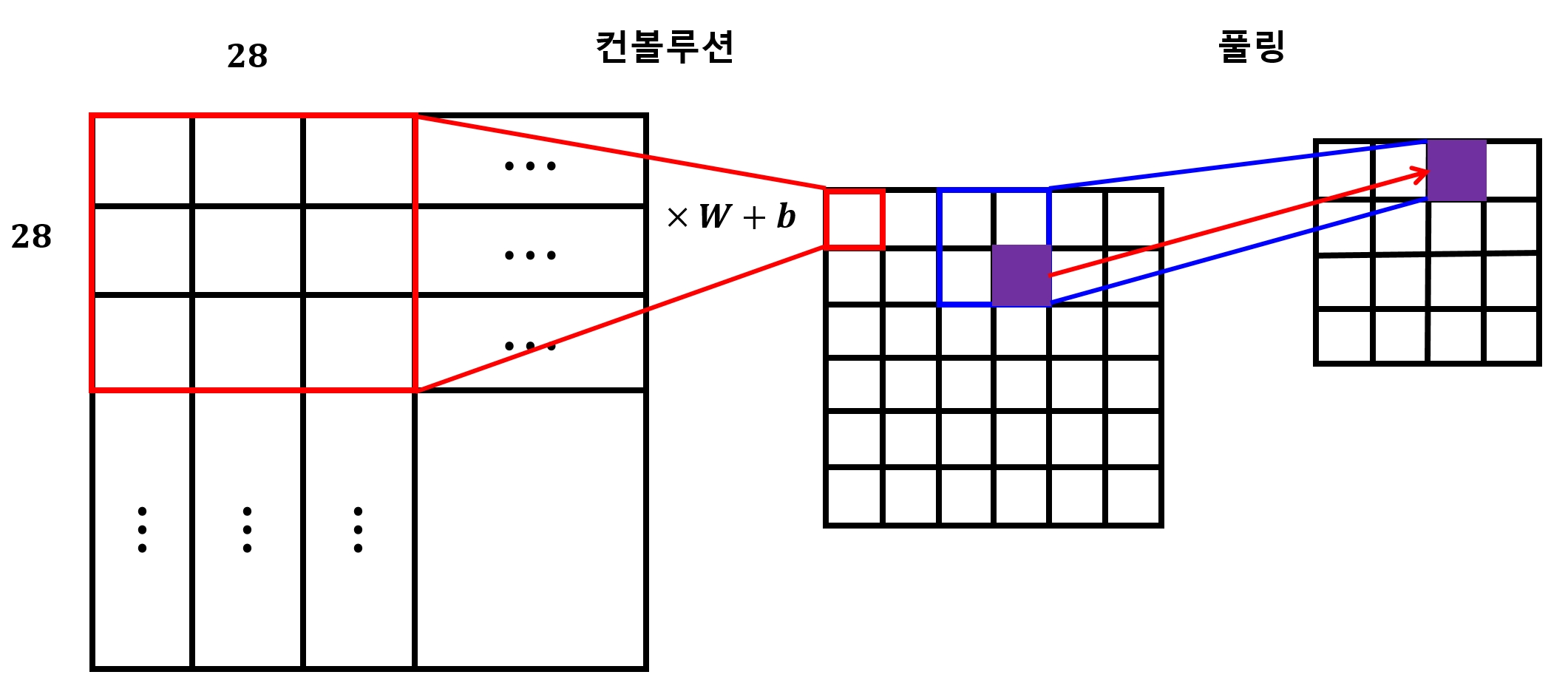
7.1.2 컨볼루션 계층과 풀링 계층의 개념
- 2D 컨볼루션의 경우
-
2차원의 평면 행렬에서 지정한 영역의 값들을 하나의 값으로 압축하는 것
- 단, 하나의 값으로 압축할 때 계층별로 방법이 다름
- (1) 컨볼루션 계층 : 압축 시 가중치와 편향 적용
- (2) 풀링 계층 : 압축 시 단순히 값들 중 하나를 선택해서 가져오는 방식을 취함
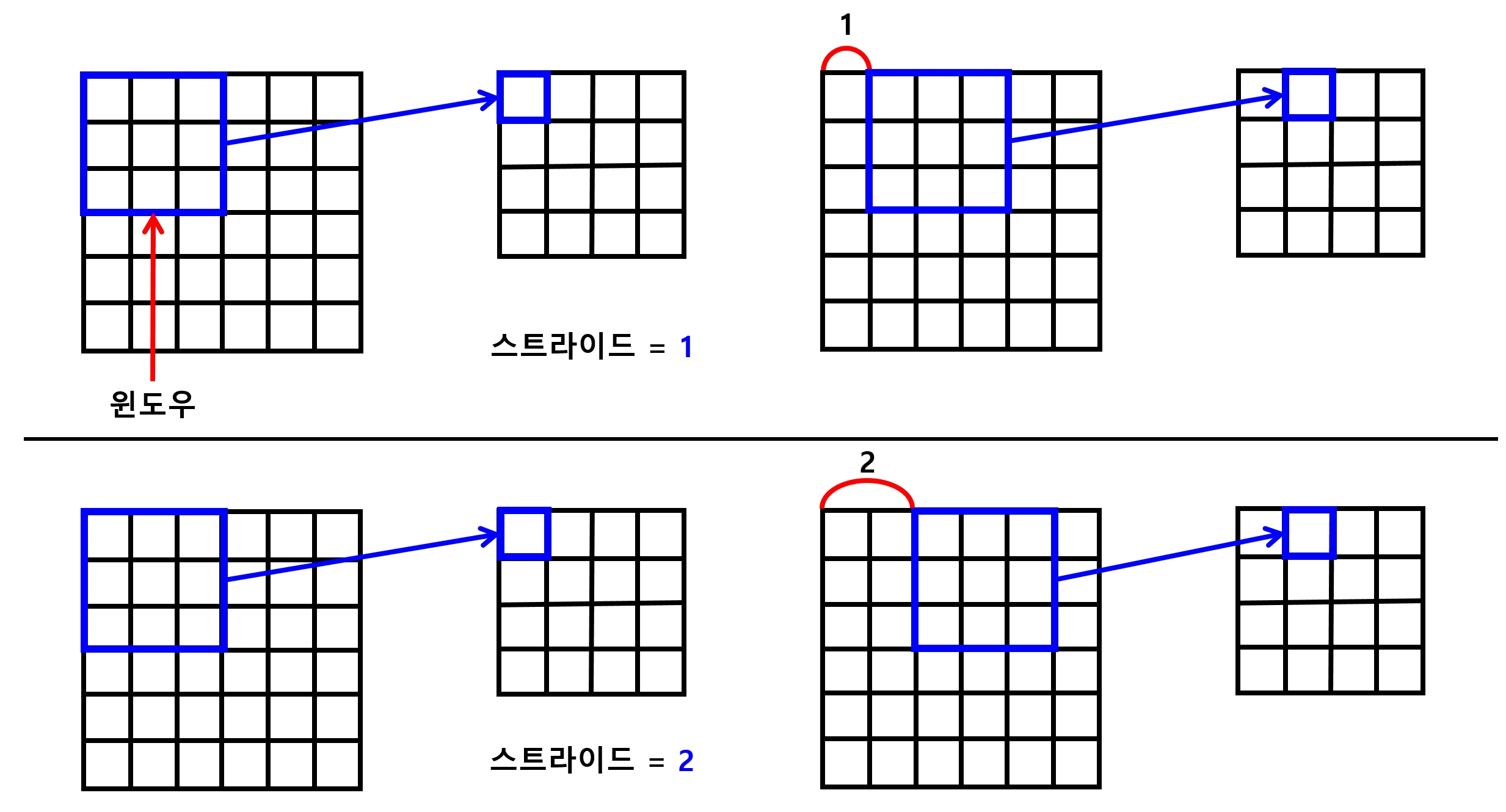
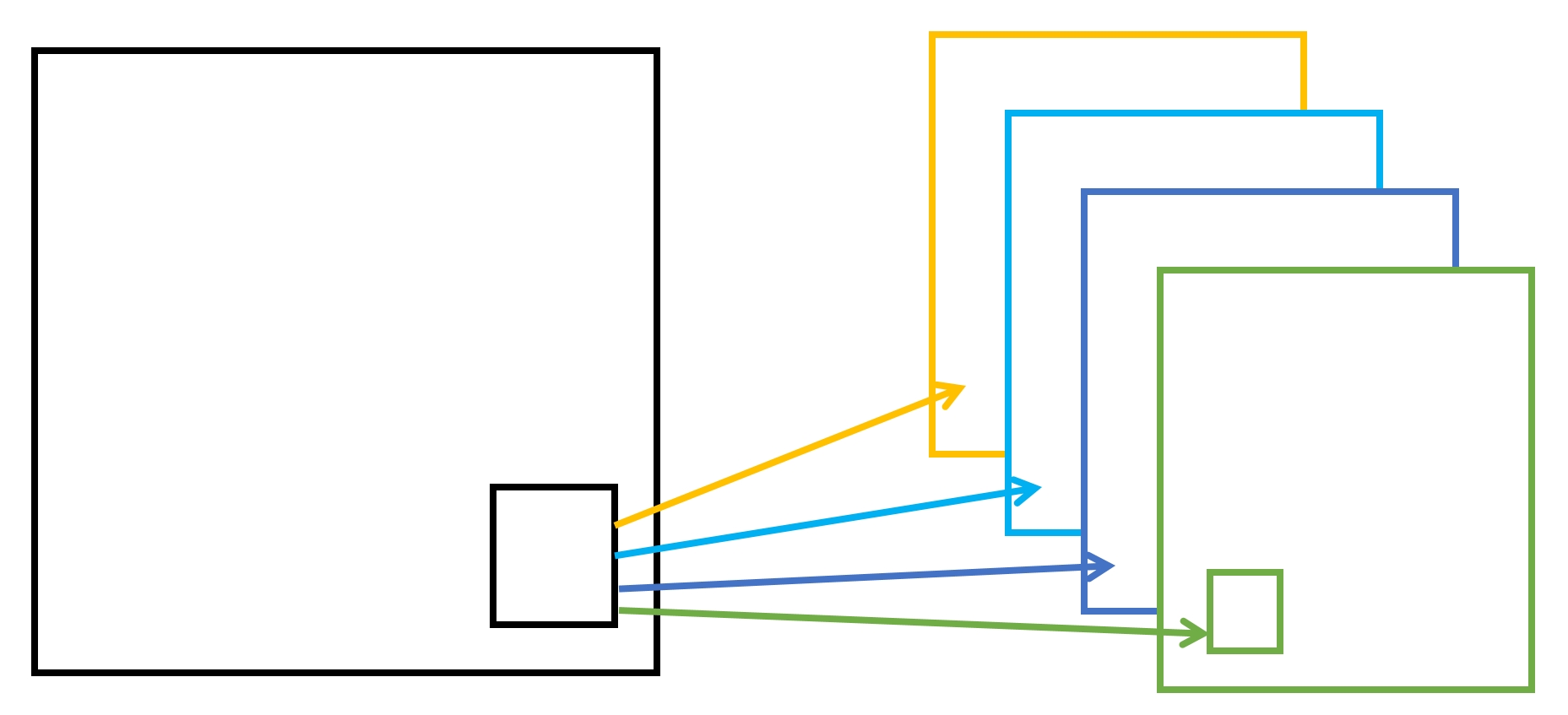
- 아래의 그림과 같이 지정한 크기의 영역을 윈도우라고 함
- 이 윈도우의 값을 오른쪽, 그리고 아래쪽으로 한 칸씩 움직이면서 은닉층 완성
- 움직이는 크기 또한 변경할 수 있음
7.1.3 스트라이드(stride)
- 몇 칸씩 움직일지 정하는 값
- 입력층의 윈도우를 은닉층의 뉴런 하나로 압축할 때, 컨볼루션 계층에서는 윈도우 크기만큼의 가중치와 1개의 편향을 적용
- ex) 윈도우 크기 = 3x3 \(\rightarrow\) 3x3(=9)개의 가중치와 1개의 편향이 필요
7.1.4 커널(kernel) 또는 필터(filer)
- 위에서 말한 3x3개의 가중치와 1개의 편향을 의미
- 이 커널은 해당 은닉층을 만들기 위한 모든 윈도우에 공통으로 적용됨
-
이것이 바로 CNN의 가장 중요한 특징 중의 하나
- ex) 입력층 = 28x28 일때,
- 기본 신경망으로 모든 뉴런을 연결 : 784개의 가중치를 찾아야 함
- 컨볼루션 계층 : 3x3개인 9개의 가중치만 찾아내면 됨
-
따라서 계산량이 매우 적어져 학습이 더 빠르고 효율적으로 이뤄짐
- 하지만 이렇게 하면 복잡한 특징을 가진 이미지들을 분석하기에는 부족할 수 있으므로 보통 커널을 여러 개 사용
- 커널의 크기나 개수 \(\rightarrow\) 하이퍼파라미터
- MNIST 데이터를 CNN으로 학습시키는 모델을 만들어 보자.
7.2 모델 구현하기
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("./mnist/data/", one_hot=True)
Extracting ./mnist/data/train-images-idx3-ubyte.gz
Extracting ./mnist/data/train-labels-idx1-ubyte.gz
Extracting ./mnist/data/t10k-images-idx3-ubyte.gz
Extracting ./mnist/data/t10k-labels-idx1-ubyte.gz
7.2.1 입력값 정의
- 6장에서 만든 기본 신경망 모델은 입력값을 28x28 짜리 차원 하나로 구성
- CNN 모델에서는 입력값을 2차원 평면으로 구성 \(\rightarrow\) 조금 더 직관적인 형태로 구성
1) X 정의
- X의 shape : [None, 28, 28, 1]
- 첫 번째 차원 (None) : 입력 데이터의 개수
- 네 번째 차원 (1) : 특징의 개수, MNIST 데이터는 회색조 이미지라 채널에 색상이 한 개 뿐이므로 1을 사용
2) Y 정의
- 출력값인 10개의 분류
3) keep_prob
- 드롭아웃을 위한
keep_prob플레이스홀더도 정의
X = tf.placeholder(tf.float32, [None, 28, 28, 1])
Y = tf.placeholder(tf.float32, [None, 10])
keep_prob = tf.placeholder(tf.float32)
print(X)
Tensor("Placeholder_6:0", shape=(?, 28, 28, 1), dtype=float32)
7.2.2 첫 번째 CNN 계층 구성 - 1) 컨볼루션 계층
- 3x3 크기의 커널을 가진 컨볼루션 계층 생성
- 다음처럼 커널에 사용할 가중치 변수와 텐서플로가 제공하는
tf.nn.conv2d함수를 사용하여 간단하게 구성
W1 = tf.Variable(tf.random_normal([3, 3, 1, 32], stddev=0.01))
L1 = tf.nn.conv2d(X, W1, strides=[1,1,1,1], padding='SAME')
L1 = tf.nn.relu(L1)
print(L1)
Tensor("Relu_4:0", shape=(?, 28, 28, 32), dtype=float32)
- 입력층
X와 첫 번째 계층의 가중치W1을 가지고, 오른쪽과 아래쪽으로 한 칸씩 움직이는 32개의 커널을 가진 컨볼루션 계층을 만들겠다는 의미
padding='SAME'
- 커널 슬라이딩 시 이미지의 가장 외곽에서 한 칸 밖으로 움직이는 옵션
- 이미지의 테두리까지도 조금 더 정확하게 평가할 수 있음
tf.nn.relu
- 활성화 함수를 통해 컨볼루션 계층을 완성
7.2.3 첫 번째 CNN 계층 구성 - 2) 풀링 계층
L1 = tf.nn.max_pool(L1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
print(L1)
Tensor("MaxPool_4:0", shape=(?, 14, 14, 32), dtype=float32)
- 앞서 만든 컨볼루션 계층을 입력으로 사용
ksize=[1,2,2,1]
- 커널 크기(
ksize)를 2x2로 하는 풀링 계층 생성
strides=[1,2,2,1]
-
슬라이딩 시 두 칸씩 움직이겠다는 옵션
-
첫 번째 CNN 계층은 아래 그림과 같이 구성됨

NOTE
X와L1텐서의 구조 확인
Tensor("Placeholder_3:0", shape=(?, 28, 28, 1), dtype=float32)
Tensor("Relu_2:0", shape=(?, 28, 28, 32), dtype=float32)
Tensor("MaxPool_2:0", shape=(?, 14, 14, 32), dtype=float32)
- 풀링 계층의 크기는 변함
- 컨볼루션 계층은 한 칸씩 슬라이딩하고 외각을 지나가는
SAME옵션으로 인해 크기가 변경되지 않음
7.2.4 두 번째 CNN 계층 구성
W2 = tf.Variable(tf.random_normal([3, 3, 32, 64], stddev=0.01))
L2 = tf.nn.conv2d(L1, W2, strides=[1, 1, 1, 1], padding='SAME')
L2 = tf.nn.relu(L2)
print(L2)
L2 = tf.nn.max_pool(L2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
print(L2)
Tensor("Relu_5:0", shape=(?, 14, 14, 64), dtype=float32)
Tensor("MaxPool_5:0", shape=(?, 7, 7, 64), dtype=float32)
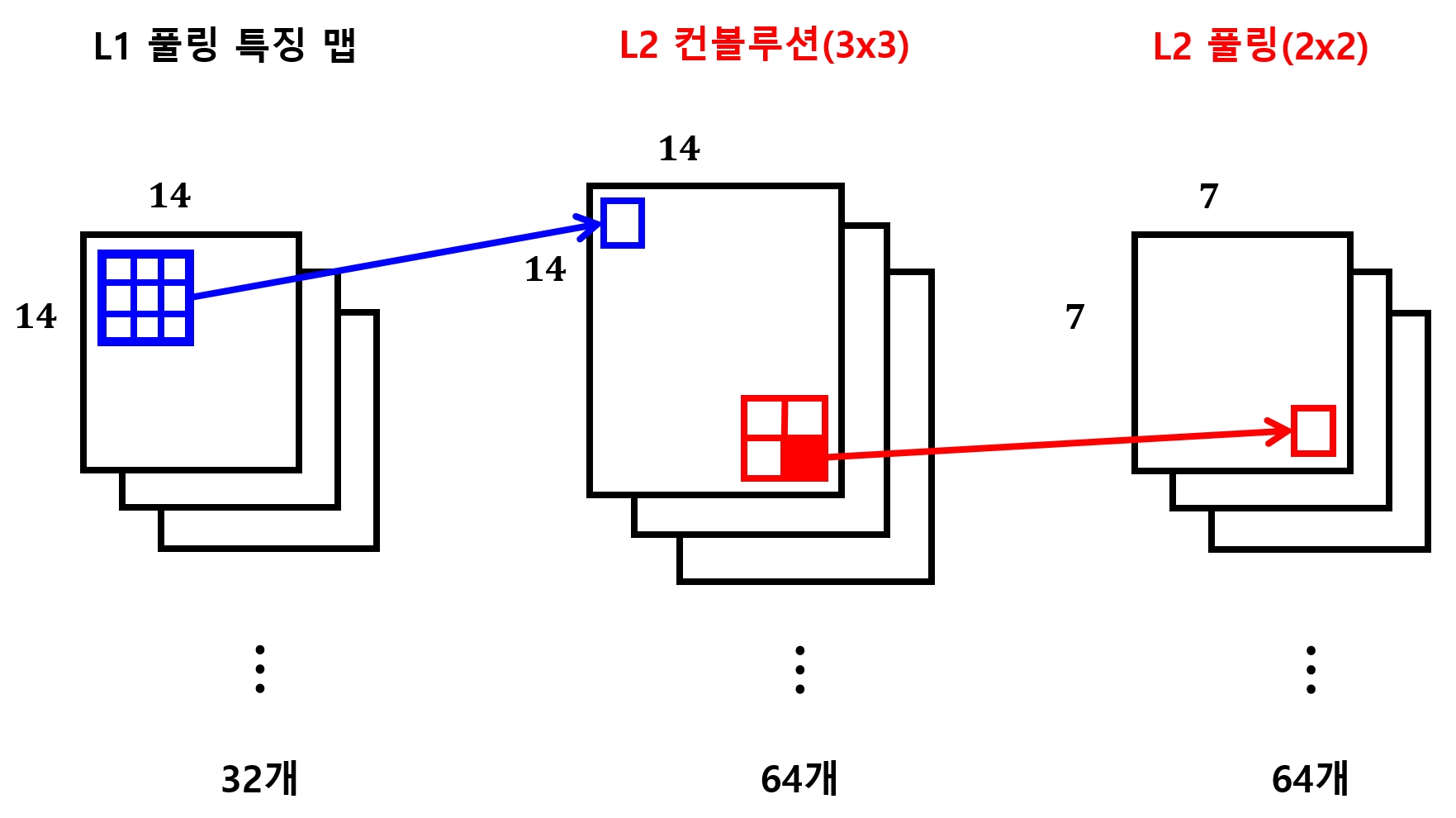
- 3x3 크기의 커널 64개로 구성한 컨볼루션 계층과 2x2 크기의 풀링 계층으로 구성
W2의 shape = [3, 3, 32, 64]
-
32: 앞서 구성한 첫 번째 컨볼루션 계층의 커널 개수, 출력층의 개수, 첫 번째 컨볼루션 계층이 찾아낸 이미지의 특징 개수 -
두 번째 CNN 계층은 아래 그림과 같이 구성됨
7.2.5 완전 연결 계층 구성
- 추출한 특징들을 이용해 10개의 분류를 만들어내는 계층 구성
W3 = tf.Variable(tf.random_normal([7 * 7 * 64, 256], stddev=0.01))
L3 = tf.reshape(L2, [-1, 7 * 7 * 64])
L3 = tf.matmul(L3, W3)
L3 = tf.nn.relu(L3)
L3 = tf.nn.dropout(L3, keep_prob)
- 10개의 분류 = 1차원 배열 \(\rightarrow\) 차원을 줄이는 단계 필요
- 직전의 풀링 계층의 크기 = 7x7x64
tf.reshape함수를 이용해 7x7x64 크기의 1차원 계층으로 만듬- 이 배열 전체를 최종 출력값의 중간 단계인 256개의 뉴런으로 연결하는 신경망을 만들어 줌
완전 연결 계층 (fully connected layer)
- 인접한 계층의 모든 뉴런과 상호 연결된 계층
tf.nn.dropout
- 이번 계층에서는 추가로 과적합을 막아주는 드롭아웃 기법 사용
7.2.6 최종 출력값 생성
- 모델 구성의 마지막으로 직전의 은닉층인
L3의 출력값 256개를 받아 최종 출력값인 0~9 레이블을 갖는 10개의 출력값을 만듬
W4 = tf.Variable(tf.random_normal([256, 10], stddev=0.01))
model = tf.matmul(L3, W4)
7.2.7 손실 함수 & 최적화 함수
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=model, labels=Y))
optimizer = tf.train.AdamOptimizer(0.001).minimize(cost)
- 최적화 함수로
AdamOptimizer대신RMSPropOptimizer를 사용하여 모델 성능 비교
optimizer = tf.train.RMSPropOptimizer(0.001, 0.9).minimize(cost)
7.2.8 학습 및 결과 확인
- 모델에 입력값을 전달하기 위해 MNIST 데이터를 28x28 형태로 재구성하는 부분 주의
- 이 부분 역시 텐서플로의 MNIST 모듈에서 지원해줌
batch_xs.reshape(-1, 28, 28, 1)
mnist.test.images.reshape(-1, 28, 28, 1)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
batch_size = 100
total_batch = int(mnist.train.num_examples / batch_size)
for epoch in range(15):
total_cost = 0
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
batch_xs = batch_xs.reshape(-1, 28, 28, 1)
_, cost_val = sess.run([optimizer, cost], feed_dict={X: batch_xs, Y: batch_ys, keep_prob: 0.7})
total_cost += cost_val
print('Epoch: ', '%04d' % (epoch + 1),
'Avg. Cost = ', '{:.3f}'.format(total_cost / total_batch))
print('최적화 완료!')
Epoch: 0001 Avg. Cost = 0.348
Epoch: 0002 Avg. Cost = 0.109
Epoch: 0003 Avg. Cost = 0.077
Epoch: 0004 Avg. Cost = 0.061
Epoch: 0005 Avg. Cost = 0.051
Epoch: 0006 Avg. Cost = 0.043
Epoch: 0007 Avg. Cost = 0.034
Epoch: 0008 Avg. Cost = 0.033
Epoch: 0009 Avg. Cost = 0.027
Epoch: 0010 Avg. Cost = 0.024
Epoch: 0011 Avg. Cost = 0.021
Epoch: 0012 Avg. Cost = 0.019
Epoch: 0013 Avg. Cost = 0.019
Epoch: 0014 Avg. Cost = 0.016
Epoch: 0015 Avg. Cost = 0.016
최적화 완료!
is_correct = tf.equal(tf.argmax(model, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
print('정확도: ', sess.run(accuracy, feed_dict={X: mnist.test.images.reshape(-1, 28, 28, 1),
Y: mnist.test.labels,
keep_prob: 1}))
정확도: 0.9926
- 6장에서 CNN을 사용하지 않은 모델로 얻은 결과인 98.1%보다 1.15%나 높은 결과를 얻음
7.2.9 전체 코드
- 전체코드에선 최적화 함수로
AdamOptimizer대신RMSPropOptimizer를 사용
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("./mnist/data/", one_hot=True)
##########
# 신경망 모델 구성
##########
# 7.2.1
X = tf.placeholder(tf.float32, [None, 28, 28, 1])
Y = tf.placeholder(tf.float32, [None, 10])
keep_prob = tf.placeholder(tf.float32)
# 7.2.2
W1 = tf.Variable(tf.random_normal([3, 3, 1, 32], stddev=0.01))
L1 = tf.nn.conv2d(X, W1, strides=[1, 1, 1, 1], padding='SAME')
L1 = tf.nn.relu(L1)
# 7.2.3
L1 = tf.nn.max_pool(L1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 7.2.4
W2 = tf.Variable(tf.random_normal([3, 3, 32, 64], stddev=0.01))
L2 = tf.nn.conv2d(L1, W2, strides=[1, 1, 1, 1], padding='SAME')
L2 = tf.nn.relu(L2)
L2 = tf.nn.max_pool(L2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 7.2.5
W3 = tf.Variable(tf.random_normal([7 * 7 * 64, 256], stddev=0.01))
L3 = tf.reshape(L2, [-1, 7 * 7 * 64])
L3 = tf.matmul(L3, W3)
L3 = tf.nn.relu(L3)
L3 = tf.nn.dropout(L3, keep_prob)
# 7.2.6
W4 = tf.Variable(tf.random_normal([256, 10], stddev=0.01))
model = tf.matmul(L3, W4)
# 7.2.7
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=model, labels=Y))
optimizer = tf.train.RMSPropOptimizer(0.001, 0.9).minimize(cost)
##########
# 신경망 모델 학습
##########
# 7.2.8
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
batch_size = 100
total_batch = int(mnist.train.num_examples / batch_size)
for epoch in range(15):
total_cost = 0
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
batch_xs = batch_xs.reshape(-1, 28, 28, 1)
_, cost_val = sess.run([optimizer, cost], feed_dict={X: batch_xs,
Y: batch_ys,
keep_prob: 0.7})
total_cost += cost_val
print('Epoch: ', '%04d' % (epoch+1),
'Avg. Cost = ', '{:.3f}'.format(total_cost / total_batch))
print('최적화 완료!')
##########
# 결과 확인
##########
is_correct = tf.equal(tf.argmax(model, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
print('정확도: ', sess.run(accuracy, feed_dict={X: mnist.test.images.reshape(-1, 28, 28, 1),
Y: mnist.test.labels,
keep_prob: 1}))
Extracting ./mnist/data/train-images-idx3-ubyte.gz
Extracting ./mnist/data/train-labels-idx1-ubyte.gz
Extracting ./mnist/data/t10k-images-idx3-ubyte.gz
Extracting ./mnist/data/t10k-labels-idx1-ubyte.gz
Epoch: 0001 Avg. Cost = 0.923
Epoch: 0002 Avg. Cost = 0.097
Epoch: 0003 Avg. Cost = 0.062
Epoch: 0004 Avg. Cost = 0.050
Epoch: 0005 Avg. Cost = 0.041
Epoch: 0006 Avg. Cost = 0.036
Epoch: 0007 Avg. Cost = 0.030
Epoch: 0008 Avg. Cost = 0.027
Epoch: 0009 Avg. Cost = 0.023
Epoch: 0010 Avg. Cost = 0.021
Epoch: 0011 Avg. Cost = 0.018
Epoch: 0012 Avg. Cost = 0.017
Epoch: 0013 Avg. Cost = 0.016
Epoch: 0014 Avg. Cost = 0.015
Epoch: 0015 Avg. Cost = 0.013
최적화 완료!
정확도: 0.9896
- 최적화 함수로
RMSPropOptimizer를 사용한 결과AdamOptimizer를 사용했을 때의 정확도 99.26%보다 0.3% 낮은 정확도를 얻었다.
7.3 고수준 API
- 텐서플로는 고수준 API를 통해 보다 쉽게 신경망을 학습시킬 수 있는 방법을 제공
-
간단하게
layers모듈을 이용하여 7.2에서 만든 CNN 모델을 조금 더 간단하게 만들어 보자. - 신경망 모델 구성 이전 부분은 동일
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("./mnist/data/", one_hot=True)
X = tf.placeholder(tf.float32, [None, 28, 28, 1])
Y = tf.placeholder(tf.float32, [None, 10])
keep_prob = tf.placeholder(tf.float32)
Extracting ./mnist/data/train-images-idx3-ubyte.gz
Extracting ./mnist/data/train-labels-idx1-ubyte.gz
Extracting ./mnist/data/t10k-images-idx3-ubyte.gz
Extracting ./mnist/data/t10k-labels-idx1-ubyte.gz
7.3.1 첫 번째 CNN 계층 구성
layers모듈을 사용하지 않았을 때의 첫 번째 컨볼루션 및 풀링 계층의 코드
W1 = tf.Variable(tf.random_normal([3, 3, 1, 32], stddev=0.01))
L1 = tf.nn.conv2d(X, W1, strides=[1, 1, 1, 1], padding='SAME')
L1 = tf.nn.relu(L1)
L1 = tf.nn.max_pool(L1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
- 이것을
tf.layers모듈을 이용하면 다음의 두 줄로 줄일 수 있다.
L1 = tf.layers.conv2d(X, 32, [3, 3], activation=tf.nn.relu, padding='SAME')
L1 = tf.layers.max_pooling2d(L1, [2, 2], [2, 2], padding='SAME')
- 같은 방법으로 두 번째 CNN 계층도 구성
L2 = tf.layers.conv2d(L1, 64, [3, 3])
L2 = tf.layers.max_pooling2d(L2, [2, 2], [2, 2])
7.3.2 완전 연결 계층 구성
layers모듈을 사용하지 않았을 때의 완전 연결 계층을 만드는 코드
W3 = tf.Variable(tf.random_normal([7 * 7 * 64, 256], stddev=0.01))
L3 = tf.reshape(L2, [-1, 7 * 7 * 64])
L3 = tf.matmul(L3, W3)
L3 = tf.nn.relu(L3)
- 이 코드 역시
tf.layers모듈을 사용하면 간단하게 작성할 수 있음 - 직접 생각하고 계산해야 하는 것들을 생략할 수 있어 매우 편하게 코드를 작성할 수 있다.
L3 = tf.contrib.layers.flatten(L2)
L3 = tf.layers.dense(L3, 256, activation=tf.nn.relu)
-
이 후 최종 출력값 생성, 손실 함수 및 최적화 함수 적용, 모델 학습 및 결과 확인 부분은 7.2와 동일하므로 생략하고 전체 코드에서 확인해보자.
tf.layers등의 고급 API를 사용하면 활성화 함수 나 컨볼루션 계층 을 만들기 위한 나머지 수치들은 알아서 계산하고 적용해줌- 또한 가중치 를 초기화 할 때 기본적으로
xavier_initializer함수를 쓰는 등, 신경망을 효율적으로 만들어주는 옵션들도 쉽게 사용할 수 있도록 해줌
7.3.3 전체 코드
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("./mnist/data/", one_hot=True)
##########
# 신경망 모델 구성
##########
X = tf.placeholder(tf.float32, [None, 28, 28, 1])
Y = tf.placeholder(tf.float32, [None, 10])
is_training = tf.placeholder(tf.bool) # layers 모듈의 dropout 함수를 사용하기 위해 is_training 변수 정의
# 7.3.1
L1 = tf.layers.conv2d(X, 32, [3, 3], activation=tf.nn.relu, padding='SAME')
L1 = tf.layers.max_pooling2d(L1, [2, 2], [2, 2], padding='SAME')
L1 = tf.layers.dropout(L1, 0.7, is_training) # layers.dropout 함수 사용
L2 = tf.layers.conv2d(L1, 64, [3, 3])
L2 = tf.layers.max_pooling2d(L2, [2, 2], [2, 2])
L2 = tf.layers.dropout(L2, 0.7, is_training)
# 7.3.2
L3 = tf.contrib.layers.flatten(L2)
L3 = tf.layers.dense(L3, 256, activation=tf.nn.relu)
L3 = tf.layers.dropout(L3, 0.5, is_training)
model = tf.layers.dense(L3, 10, activation=None)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=model, labels=Y))
optimizer = tf.train.AdamOptimizer(0.001).minimize(cost)
##########
# 신경망 모델 학습
##########
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
batch_size = 100
total_batch = int(mnist.train.num_examples / batch_size)
for epoch in range(15):
total_cost = 0
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
batch_xs = batch_xs.reshape(-1, 28, 28, 1)
_, cost_val = sess.run([optimizer, cost], feed_dict={X: batch_xs,
Y: batch_ys,
is_training: True})
total_cost += cost_val
print('Epoch: ', '%04d' % (epoch+1),
'Avg. Cost = ', '{:.4f}'.format(total_cost / total_batch))
print('최적화 완료!')
##########
# 결과 확인
##########
is_correct = tf.equal(tf.argmax(model, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
print('정확도: ', sess.run(accuracy, feed_dict={X: mnist.test.images.reshape(-1, 28, 28, 1),
Y: mnist.test.labels,
is_training: False}))
Extracting ./mnist/data/train-images-idx3-ubyte.gz
Extracting ./mnist/data/train-labels-idx1-ubyte.gz
Extracting ./mnist/data/t10k-images-idx3-ubyte.gz
Extracting ./mnist/data/t10k-labels-idx1-ubyte.gz
Epoch: 0001 Avg. Cost = 0.1680
Epoch: 0002 Avg. Cost = 0.0476
Epoch: 0003 Avg. Cost = 0.0305
Epoch: 0004 Avg. Cost = 0.0205
Epoch: 0005 Avg. Cost = 0.0143
Epoch: 0006 Avg. Cost = 0.0160
Epoch: 0007 Avg. Cost = 0.0101
Epoch: 0008 Avg. Cost = 0.0086
Epoch: 0009 Avg. Cost = 0.0076
Epoch: 0010 Avg. Cost = 0.0087
Epoch: 0011 Avg. Cost = 0.0079
Epoch: 0012 Avg. Cost = 0.0055
Epoch: 0013 Avg. Cost = 0.0045
Epoch: 0014 Avg. Cost = 0.0069
Epoch: 0015 Avg. Cost = 0.0039
최적화 완료!
정확도: 0.9911
7.4 더 보기
- CNN을 구현하고 테스트해보면 학습 시간이 꽤 오래 걸림
- 실제 문제를 풀기 시작하면 더 많은 컴퓨터 자원이 필요
-
클라우드 컴퓨팅을 이용하면 더 저렴하고 빠르게 학습시킬 수 있다.
- 텐서플로를 사용하기에 좋은 클라우드 컴퓨팅 방법은 구글이 제공하는 Cloud ML이다.
- 학습뿐 아니라 학습된 모델을 Cloud ML에 올려 쉽고 편하게 예측 서비스에 사용할 수도 있음
댓글남기기