해당 포스트는 책 “골빈해커의 3분 딥러닝 텐서플로맛”의 9장 “딥러닝의 미래 GAN”을 학습하고 내용을 정리한 글입니다.
GAN (Generative Adversarial Network)
- 2016년에 가장 이슈가 많이 된 딥러닝 모델
- 오토인코더와 같이 결과물을 생성하는 생성 모델 중 하나
- 서로 대립(adversarial)하는 두 신경망을 경쟁시켜가며 결과물 생성 방법을 학습
이안 굿펠로우(lan Goodfellow)가 제시한 GAN의 비유
- 위조지폐범(생성자)과 경찰(구분자)에 대한 이야기
- 위조지폐범은 경찰을 최대한 속이려고 노력
- 경찰은 위조한 지폐를 최대한 감별하려고 노력
-
위조지폐를 만들고 감별하려는 경쟁을 통해 서로의 능력이 발전
- 신경망 모델의 구조는 아래 그림과 같음
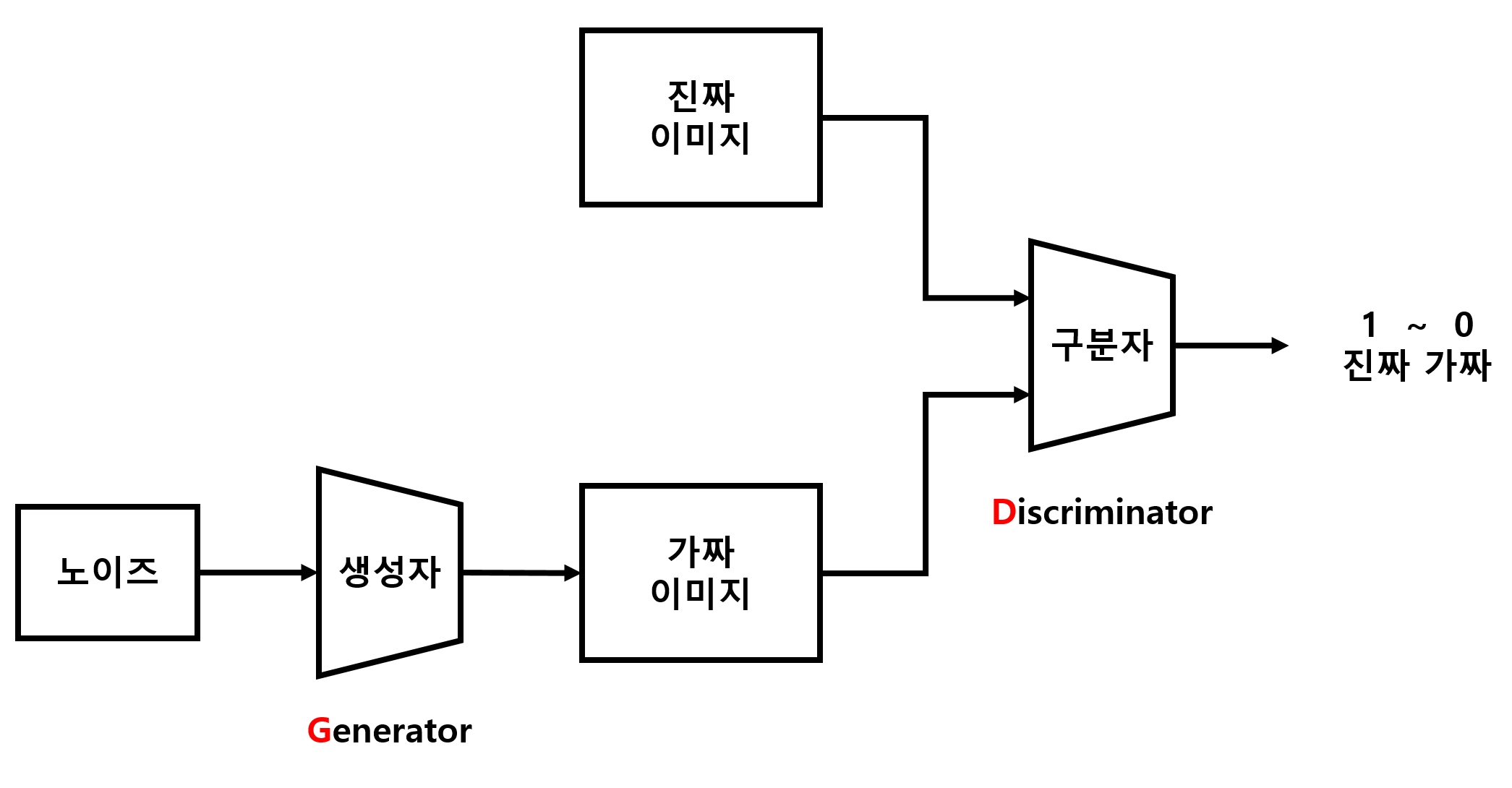
- 실제 이미지를 주고 구분자(Discriminator)에게 이 이미지가 진짜임을 판단하게 함
- 그 다음 생성자(Generator)를 통해 노이즈로부터 임의의 이미지를 만듬
- 이것을 다시 구분자를 통해 진짜 이미지인지를 판단하게 함
- 이와 같이 생성자는 구분자를 속여 진짜처럼 보이게 하고, 구분자는 생성자가 만든 이미지를 최대한 가짜라고 구분하도록 훈련하는 것이 GAN의 핵심
- 생성자와 구분자의 경쟁을 통해 결과적으로 생성자는 실제 이미지와 상당히 비슷한 이미지를 생성해낼 수 있게 됨
GAN 기법의 사용 예시
- 사진을 고흐 풍 그림으로 다시 그리기
- 선으로만 그려진 만화를 자동으로 채색
-
모자이크 없애기
-
GAN 기법을 이용한 자연어 문장 생성 등에 관한 연구도 활발하게 진행 중
- 이번 장에선 GAN 모델을 이용하여 MNIST 손글씨 숫자를 무작위로 생성하는 간단한 예제를 만들어 보기
- 모델을 조금 확장하여 원하는 숫자에 해당하는 이미지를 생성하는 모델 만들어 보기
9.1 기본 모델 구현하기
9.1.1 필요한 라이브러리 및 MNIST 데이터 Import
import tensorflow as tf
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("./mnist/data", one_hot=True)
9.1.2 하이퍼파라미터 설정
total_epoch = 100
batch_size = 100
learning_rate = 0.0002
n_hidden = 256
n_input = 28 * 28
n_noise = 128
n_noise
- 생성자의 입력값으로 사용할 노이즈의 크기
- 랜덤한 노이즈를 입력하고, 그 노이즈에서 손글씨 이미지를 무작위로 생성해내도록 할 것
9.1.3 플레이스홀더 설정
- GAN도 비지도 학습 \(\rightarrow\) 오토인코더처럼 Y를 사용하지 않음
- 다만, 구분자에 넣을 이미지가 실제 이미지와 생성한 가짜 이미지 2개임
- 가짜 이미지는 노이즈에서 생성 \(\rightarrow\) 노이즈를 입력할 플레이스홀더 Z 추가
X = tf.placeholder(tf.float32, [None, n_input])
Z = tf.placeholder(tf.float32, [None, n_noise])
9.1.4 생성자 신경망에서 사용할 변수 설정
- 첫 번째 가중치와 편향 : 은닉층으로 출력하기 위한 변수들
- 두 번째 가중치와 편향 : 출력층에 사용할 변수들 \(\rightarrow\) 두 번째 가중치의 변수 크기는 실제 이미지 크기(
n_input=28x28=784)와 같아야 함
G_W1 = tf.Variable(tf.random_normal([n_noise, n_hidden], stddev=0.01))
G_b1 = tf.Variable(tf.zeros([n_hidden]))
G_W2 = tf.Variable(tf.random_normal([n_hidden, n_input], stddev=0.01))
G_b2 = tf.Variable(tf.zeros([n_input]))
9.1.5 구분자 신경망에서 사용할 변수 설정
- 은닉층은 생성자와 동일하게 구성
- 구분자 : 진짜와 얼마나 가까운가를 판단하는 값 \(\rightarrow\) 0~1사이의 값을 출력할 것 \(\rightarrow\) 하나의 스칼라값을 출력하도록 구성
D_W1 = tf.Variable(tf.random_normal([n_input, n_hidden], stddev=0.01))
D_b1 = tf.Variable(tf.zeros([n_hidden]))
D_W2 = tf.Variable(tf.random_normal([n_hidden, 1], stddev=0.01))
D_b2 = tf.Variable(tf.zeros([1]))
NOTE
- 실제 이미지를 판별하는 구분자 신경망과 생성한 이미지를 판별하는 구분자 신경망은 같은 변수를 사용 해야 함
- 같은 신경망으로 구분을 시켜야 진짜 이미지와 가짜 이미지를 구분하는 특징을 동시에 잡아낼 수 있기 때문임
9.1.6 생성자 신경망 구성
def generator(noise_z):
hidden = tf.nn.relu(tf.matmul(noise_z, G_W1) + G_b1)
output = tf.nn.sigmoid(tf.matmul(hidden, G_W2) + G_b2)
return output
- 생성자는 무작위로 생성한 노이즈를 받아 가중치와 편향을 반영하여 은닉층을 생성
- 은닉층에서 실제 이미지와 같은 크기의 결괏값을 출력
9.1.7 구분자 신경망 구성
- 0~1 사이의 스칼라값 하나를 출력하도록 구성
- 이를 위한 활성화 함수로 sigmoid 함수 사용
def discriminator(inputs):
hidden = tf.nn.relu(tf.matmul(inputs, D_W1) + D_b1)
output = tf.nn.sigmoid(tf.matmul(hidden, D_W2) + D_b2)
return output
9.1.8 노이즈 생성
- 무작위한 노이즈를 만들어주는 유틸리티 함수 생성
def get_noise(batch_size, n_noise):
return np.random.normal(size=(batch_size, n_noise))
9.1.9 생성자 및 구분자 생성
- 노이즈 Z를 이용해 가짜이미지를 만들 생성자 G 만듬
- 이 G가 만든 가짜 이미지와 진짜 이미지 X를 각각 구분자에 넣어 입력한 이미지가 진짜인지 판별하게 함
G = generator(Z)
D_gene = discriminator(G)
D_real = discriminator(X)
- 이를 잘 학습시키면 생성자가 실제에 가까운 이미지를 만들 수 있게 됨
9.1.10 손실값 계산
- 두 개의 손실값 계산 필요
1) 경찰 학습용 손실값
- 생성자가 만든 이미지를 구분자가 가짜 라고 판단하도록 하는 손실값
2) 위조지폐범 학습용 손실값
- 생성자가 만든 이미지를 구분자가 진짜 라고 판단하도록 하는 손실값
1) 경찰 학습
- 경찰을 학습시키려면 진짜 이미지 판별값 D_real은 1에 가까워야하고(진짜라고 판별), 가짜 이미지 판별값 D_gene은 0에 가까워야 함(가짜라고 판별)
loss_D = tf.reduce_mean(tf.log(D_real) + tf.log(1 - D_gene))
- 손실값 = log(D_real) + (1에서 D_gene를 뺀 값)
- 이 손실값을 최대화하면 경찰 학습이 이루어짐
2) 위조지폐범 학습
- 위조지폐범 학습은 가짜 이미지 판별값 D_gene를 1에 가깝게 만들기만 하면 됨
- 즉, 가짜 이미지를 넣어도 진짜같다고 판별해야 함
loss_G = tf.reduce_mean(tf.log(D_gene))
- 이 손실값을 최대화하면 위조지폐범 학습이 이루어짐
GAN의 학습
- loss_D와 loss_G 모두를 최대화 하는 것
- 다만, loss_D와 loss_G는 서로 연관되어 있어서 두 손실값이 항상 같이 증가하는 경향을 보이지 않을 것
- loss_D가 증가하려면 loss_G는 하락해야 함
- loss_G가 증가하려면 loss_D는 하락해야 함
- 두 변수는 경쟁 관계이다.
9.1.11 최적화 함수 구성
- 손실값들을 이용해 학습 실행
주의할 점
- loss_D를 구할 때는 구분자 신경망에 사용되는 변수들만 사용
- loss_G를 구할 때는 생성자 신경망에 사용되는 변수들만 사용하여 최적화해야 함
- 그래야 loss_D를 학습할 때는 생성자가 변하지 않고, loss_G를 학습할 때는 구분자가 변하지 않기 때문
D_var_list = [D_W1, D_b1, D_W2, D_b2]
G_var_list = [G_W1, G_b1, G_W2, G_b2]
- GAN 논문에 따르면 loss를 최대화해야 함
- 그러나 최적화에 쓸 수 있는 함수는 minimize 뿐임
- 그래서 최적화하려는 loss_D와 loss_G에 음수 부호 를 붙여줌
train_D = tf.train.AdamOptimizer(learning_rate).minimize(-loss_D, var_list=D_var_list)
train_G = tf.train.AdamOptimizer(learning_rate).minimize(-loss_G, var_list=G_var_list)
9.1.12 학습
- 이번 모델에서는 두 개의 손실값을 학습시켜야 함
sess = tf.Session()
sess.run(tf.global_variables_initializer())
total_batch = int(mnist.train.num_examples / batch_size)
loss_val_D, loss_val_G = 0, 0
- 그런 다음 미니배치로 학습을 반복
- 구분자는 X 값을, 생성자는 노이즈인 Z 값을 받으므로 노이즈를 생성해주는
get_noise함수를 통해 배치 크기만큼 노이즈를 만들고 입력 - 그리고 구분자와 생성자 신경망을 각각 학습
9.1.13 학습 결과 확인
- 학습이 잘 되는 지는 0번째, 9번째, 19번째, 29번째, … 마다 생성기로 이미지를 생성하여 눈으로 직접 확인
- 결과를 확인하는 학습 루프 안에 작성해야 함
for epoch in range(total_epoch):
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
noise = get_noise(batch_size, n_noise)
_, loss_val_D = sess.run([train_D, loss_D], feed_dict={X: batch_xs, Z: noise})
_, loss_val_G = sess.run([train_G, loss_G], feed_dict={Z: noise})
print('Epoch: ', '%04d' % (epoch + 1),
'D loss: {:.4f}'.format(loss_val_D),
'G loss: {:.4f}'.format(loss_val_G))
# 9.1.13 학습 결과 확인
# 1) 노이즈를 만들고, 이것을 생성자 G에 넣어 결괏값을 만듬
if epoch == 0 or (epoch + 1) % 10 == 0:
sample_size = 10
noise = get_noise(sample_size, n_noise)
samples = sess.run(G, feed_dict={Z: noise})
# 2) 이 결괏값들을 28x28 크기의 가짜 이미지로 만들어 samples 폴더에 저장, sample 폴더는 미리 만들어져 있어야 함
fig, ax = plt.subplots(1, sample_size, figsize=(sample_size, 1))
for i in range(sample_size):
ax[i].set_axis_off()
ax[i].imshow(np.reshape(samples[i], (28, 28)))
plt.savefig('ch09/samples/{}.png'.format(str(epoch).zfill(3)), bbox_inches='tight')
plt.close(fig)
print('최적화 완료!')
Epoch: 0001 D loss: -0.1399 G loss: -3.0402
Epoch: 0002 D loss: -0.5577 G loss: -1.7184
Epoch: 0003 D loss: -0.4298 G loss: -1.9335
Epoch: 0004 D loss: -0.3020 G loss: -2.3219
Epoch: 0005 D loss: -0.1572 G loss: -3.1037
Epoch: 0006 D loss: -0.3758 G loss: -2.5447
Epoch: 0007 D loss: -0.2211 G loss: -2.6173
Epoch: 0008 D loss: -0.5092 G loss: -1.8401
Epoch: 0009 D loss: -0.3930 G loss: -2.5040
Epoch: 0010 D loss: -0.4289 G loss: -2.1434
Epoch: 0011 D loss: -0.2952 G loss: -2.4895
Epoch: 0012 D loss: -0.5662 G loss: -2.2163
Epoch: 0013 D loss: -0.4247 G loss: -2.2828
Epoch: 0014 D loss: -0.3283 G loss: -2.5070
Epoch: 0015 D loss: -0.2892 G loss: -2.5007
Epoch: 0016 D loss: -0.3443 G loss: -2.4098
Epoch: 0017 D loss: -0.2780 G loss: -2.9053
Epoch: 0018 D loss: -0.3079 G loss: -2.5370
Epoch: 0019 D loss: -0.2731 G loss: -2.8487
Epoch: 0020 D loss: -0.3312 G loss: -2.5594
Epoch: 0021 D loss: -0.2522 G loss: -3.0832
Epoch: 0022 D loss: -0.5072 G loss: -2.4625
Epoch: 0023 D loss: -0.5457 G loss: -2.5679
Epoch: 0024 D loss: -0.3908 G loss: -2.7024
Epoch: 0025 D loss: -0.4558 G loss: -2.2455
Epoch: 0026 D loss: -0.4798 G loss: -2.5598
Epoch: 0027 D loss: -0.5405 G loss: -2.2828
Epoch: 0028 D loss: -0.4112 G loss: -2.5276
Epoch: 0029 D loss: -0.4740 G loss: -2.4195
Epoch: 0030 D loss: -0.6027 G loss: -2.3809
Epoch: 0031 D loss: -0.4013 G loss: -2.6011
Epoch: 0032 D loss: -0.6586 G loss: -2.3437
Epoch: 0033 D loss: -0.5296 G loss: -2.3004
Epoch: 0034 D loss: -0.5962 G loss: -2.2269
Epoch: 0035 D loss: -0.7364 G loss: -2.4746
Epoch: 0036 D loss: -0.6788 G loss: -2.0995
Epoch: 0037 D loss: -0.4604 G loss: -2.4726
Epoch: 0038 D loss: -0.6414 G loss: -2.0904
Epoch: 0039 D loss: -0.4309 G loss: -2.3798
Epoch: 0040 D loss: -0.5819 G loss: -2.0959
Epoch: 0041 D loss: -0.7244 G loss: -2.0573
Epoch: 0042 D loss: -0.5711 G loss: -2.2700
Epoch: 0043 D loss: -0.6347 G loss: -2.1476
Epoch: 0044 D loss: -0.5493 G loss: -2.3116
Epoch: 0045 D loss: -0.7013 G loss: -2.1721
Epoch: 0046 D loss: -0.7662 G loss: -2.1663
Epoch: 0047 D loss: -0.6501 G loss: -2.2048
Epoch: 0048 D loss: -0.6144 G loss: -2.1497
Epoch: 0049 D loss: -0.7009 G loss: -2.1497
Epoch: 0050 D loss: -0.6359 G loss: -2.2275
Epoch: 0051 D loss: -0.7476 G loss: -1.9514
Epoch: 0052 D loss: -0.6552 G loss: -2.1042
Epoch: 0053 D loss: -0.7431 G loss: -1.9225
Epoch: 0054 D loss: -0.7869 G loss: -1.7013
Epoch: 0055 D loss: -0.7035 G loss: -1.8629
Epoch: 0056 D loss: -0.6798 G loss: -2.0418
Epoch: 0057 D loss: -0.7380 G loss: -2.0399
Epoch: 0058 D loss: -0.7941 G loss: -1.9064
Epoch: 0059 D loss: -0.6415 G loss: -1.9918
Epoch: 0060 D loss: -0.5898 G loss: -2.0356
Epoch: 0061 D loss: -0.7919 G loss: -1.9953
Epoch: 0062 D loss: -0.8061 G loss: -1.6075
Epoch: 0063 D loss: -0.7627 G loss: -1.8456
Epoch: 0064 D loss: -0.8155 G loss: -2.0026
Epoch: 0065 D loss: -0.7951 G loss: -1.9633
Epoch: 0066 D loss: -0.6892 G loss: -1.9054
Epoch: 0067 D loss: -0.9283 G loss: -1.9096
Epoch: 0068 D loss: -0.7800 G loss: -1.8842
Epoch: 0069 D loss: -0.7763 G loss: -1.8369
Epoch: 0070 D loss: -1.1049 G loss: -1.7920
Epoch: 0071 D loss: -0.8607 G loss: -1.7032
Epoch: 0072 D loss: -0.6872 G loss: -1.8790
Epoch: 0073 D loss: -0.7905 G loss: -1.8233
Epoch: 0074 D loss: -0.7625 G loss: -1.7791
Epoch: 0075 D loss: -0.7547 G loss: -2.0161
Epoch: 0076 D loss: -0.7156 G loss: -1.8741
Epoch: 0077 D loss: -0.8200 G loss: -1.7391
Epoch: 0078 D loss: -0.7407 G loss: -1.6534
Epoch: 0079 D loss: -0.8413 G loss: -1.7666
Epoch: 0080 D loss: -0.8202 G loss: -1.8811
Epoch: 0081 D loss: -0.8458 G loss: -1.6986
Epoch: 0082 D loss: -0.7958 G loss: -1.7505
Epoch: 0083 D loss: -0.7657 G loss: -1.8469
Epoch: 0084 D loss: -0.6639 G loss: -1.8922
Epoch: 0085 D loss: -0.6768 G loss: -2.2530
Epoch: 0086 D loss: -0.7334 G loss: -1.6212
Epoch: 0087 D loss: -0.7539 G loss: -1.7957
Epoch: 0088 D loss: -0.6677 G loss: -1.8437
Epoch: 0089 D loss: -0.6891 G loss: -1.8812
Epoch: 0090 D loss: -0.7217 G loss: -1.9857
Epoch: 0091 D loss: -0.7341 G loss: -1.7571
Epoch: 0092 D loss: -0.7062 G loss: -2.1142
Epoch: 0093 D loss: -0.8058 G loss: -1.9465
Epoch: 0094 D loss: -0.7102 G loss: -1.8433
Epoch: 0095 D loss: -0.7571 G loss: -1.9795
Epoch: 0096 D loss: -0.6843 G loss: -1.9896
Epoch: 0097 D loss: -0.8948 G loss: -1.9126
Epoch: 0098 D loss: -0.8353 G loss: -1.9674
Epoch: 0099 D loss: -0.6777 G loss: -1.8901
Epoch: 0100 D loss: -0.5310 G loss: -1.9507
최적화 완료!











- 학습이 정상적으로 진행되었다면 그림과 같이 학습 세대가 지나면서 이미지가 점점 그럴듯해지는 것을 볼 수 있음
9.1.14 전체 코드
# 9.1.1
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("./mnist/data/", one_hot=True)
##########
# 옵션 설정
##########
# 9.1.2
total_epoch = 100
batch_size = 100
learning_rate = 0.0002
n_hidden = 256
n_input = 28 * 28
n_noise = 128
##########
# 신경망 모델 구성
##########
# 9.1.3
X = tf.placeholder(tf.float32, [None, n_input])
Z = tf.placeholder(tf.float32, [None, n_noise])
# 9.1.4
G_W1 = tf.Variable(tf.random_normal([n_noise, n_hidden], stddev=0.01))
G_b1 = tf.Variable(tf.zeros([n_hidden]))
G_W2 = tf.Variable(tf.random_normal([n_hidden, n_input], stddev=0.01))
G_b2 = tf.Variable(tf.zeros([n_input]))
# 9.1.5
D_W1 = tf.Variable(tf.random_normal([n_input, n_hidden], stddev=0.01))
D_b1 = tf.Variable(tf.zeros([n_hidden]))
D_W2 = tf.Variable(tf.random_normal([n_hidden, 1], stddev=0.01))
D_b2 = tf.Variable(tf.zeros([1]))
# 9.1.6
def generator(noise_z):
hidden = tf.nn.relu(tf.matmul(noise_z, G_W1) + G_b1)
output = tf.nn.sigmoid(tf.matmul(hidden, G_W2) + G_b2)
return output
# 9.1.7
def discriminator(inputs):
hidden = tf.nn.relu(tf.matmul(inputs, D_W1) + D_b1)
output = tf.nn.sigmoid(tf.matmul(hidden, D_W2) + D_b2)
return output
# 9.1.8
def get_noise(batch_size, n_noise):
return np.random.normal(size=(batch_size, n_noise))
# 9.1.9
G = generator(Z)
D_gene = discriminator(G)
D_real = discriminator(X)
# 9.1.10
loss_D = tf.reduce_mean(tf.log(D_real) + tf.log(1 - D_gene))
loss_G = tf.reduce_mean(tf.log(D_gene))
# 9.1.11
D_var_list = [D_W1, D_b1, D_W2, D_b2]
G_var_list = [G_W1, G_b1, G_W2, G_b2]
train_D = tf.train.AdamOptimizer(learning_rate).minimize(-loss_D, var_list=D_var_list)
train_G = tf.train.AdamOptimizer(learning_rate).minimize(-loss_G, var_list=G_var_list)
##########
# 신경망 모델 학습
##########
# 9.1.12
sess = tf.Session()
sess.run(tf.global_variables_initializer())
total_batch = int(mnist.train.num_examples / batch_size)
loss_val_D, loss_val_G = 0, 0
for epoch in range(total_epoch):
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
noise = get_noise(batch_size, n_noise)
_, loss_val_D = sess.run([train_D, loss_D], feed_dict={X: batch_xs, Z: noise})
_, loss_val_G = sess.run([train_G, loss_G], feed_dict={Z: noise})
print('Epoch: ', '%04d' % (epoch + 1),
'D loss: {:.4f}'.format(loss_val_D),
'G loss: {:.4f}'.format(loss_val_G))
# 9.1.13
if epoch == 0 or (epoch + 1) % 10 == 0:
sample_size = 10
noise = get_noise(sample_size, n_noise)
samples = sess.run(G, feed_dict={Z: noise})
fig, ax = plt.subplots(1, sample_size, figsize=(sample_size, 1))
for i in range(sample_size):
ax[i].set_axis_off()
ax[i].imshow(np.reshape(samples[i], (28, 28)))
plt.savefig('ch09/samples2/{}.png'.format(str(epoch).zfill(3)), bbox_inches='tight')
plt.close(fig)
print('최적화 완료!')
Extracting ./mnist/data/train-images-idx3-ubyte.gz
Extracting ./mnist/data/train-labels-idx1-ubyte.gz
Extracting ./mnist/data/t10k-images-idx3-ubyte.gz
Extracting ./mnist/data/t10k-labels-idx1-ubyte.gz
Epoch: 0001 D loss: -0.4525 G loss: -2.0736
Epoch: 0002 D loss: -0.4195 G loss: -2.0122
Epoch: 0003 D loss: -0.2538 G loss: -2.5384
Epoch: 0004 D loss: -0.5348 G loss: -1.5473
Epoch: 0005 D loss: -0.4418 G loss: -1.9490
Epoch: 0006 D loss: -0.2437 G loss: -2.8000
Epoch: 0007 D loss: -0.1950 G loss: -2.9607
Epoch: 0008 D loss: -0.2833 G loss: -2.5180
Epoch: 0009 D loss: -0.2603 G loss: -2.6379
Epoch: 0010 D loss: -0.4330 G loss: -2.6899
Epoch: 0011 D loss: -0.3092 G loss: -2.6160
Epoch: 0012 D loss: -0.2992 G loss: -2.4162
Epoch: 0013 D loss: -0.2632 G loss: -2.8360
Epoch: 0014 D loss: -0.4512 G loss: -2.5799
Epoch: 0015 D loss: -0.3608 G loss: -2.3884
Epoch: 0016 D loss: -0.3092 G loss: -2.7110
Epoch: 0017 D loss: -0.4072 G loss: -2.7701
Epoch: 0018 D loss: -0.4073 G loss: -2.2823
Epoch: 0019 D loss: -0.4586 G loss: -2.2949
Epoch: 0020 D loss: -0.5479 G loss: -2.3337
Epoch: 0021 D loss: -0.4359 G loss: -2.4022
Epoch: 0022 D loss: -0.5157 G loss: -2.6122
Epoch: 0023 D loss: -0.4876 G loss: -2.6476
Epoch: 0024 D loss: -0.3934 G loss: -2.4400
Epoch: 0025 D loss: -0.4535 G loss: -2.4756
Epoch: 0026 D loss: -0.4845 G loss: -2.1708
Epoch: 0027 D loss: -0.5144 G loss: -2.6206
Epoch: 0028 D loss: -0.6159 G loss: -2.1669
Epoch: 0029 D loss: -0.5833 G loss: -2.2591
Epoch: 0030 D loss: -0.7123 G loss: -2.0221
Epoch: 0031 D loss: -0.4026 G loss: -2.6372
Epoch: 0032 D loss: -0.3825 G loss: -2.5118
Epoch: 0033 D loss: -0.4381 G loss: -2.4950
Epoch: 0034 D loss: -0.5625 G loss: -2.5313
Epoch: 0035 D loss: -0.5411 G loss: -2.5609
Epoch: 0036 D loss: -0.5246 G loss: -2.4377
Epoch: 0037 D loss: -0.5901 G loss: -2.1766
Epoch: 0038 D loss: -0.4808 G loss: -2.6071
Epoch: 0039 D loss: -0.6059 G loss: -2.0402
Epoch: 0040 D loss: -0.5990 G loss: -2.0862
Epoch: 0041 D loss: -0.7299 G loss: -1.8490
Epoch: 0042 D loss: -0.7669 G loss: -2.0850
Epoch: 0043 D loss: -0.5823 G loss: -2.1306
Epoch: 0044 D loss: -0.6824 G loss: -2.1041
Epoch: 0045 D loss: -0.7729 G loss: -1.9316
Epoch: 0046 D loss: -0.7186 G loss: -2.0564
Epoch: 0047 D loss: -0.6575 G loss: -2.0236
Epoch: 0048 D loss: -0.6766 G loss: -2.0315
Epoch: 0049 D loss: -0.9746 G loss: -1.8182
Epoch: 0050 D loss: -0.6675 G loss: -2.2242
Epoch: 0051 D loss: -0.6897 G loss: -1.6935
Epoch: 0052 D loss: -0.7941 G loss: -2.1622
Epoch: 0053 D loss: -0.8329 G loss: -1.8549
Epoch: 0054 D loss: -0.7359 G loss: -1.6378
Epoch: 0055 D loss: -0.9469 G loss: -1.6177
Epoch: 0056 D loss: -0.8023 G loss: -1.9922
Epoch: 0057 D loss: -0.7113 G loss: -1.9368
Epoch: 0058 D loss: -0.8535 G loss: -1.9742
Epoch: 0059 D loss: -0.8974 G loss: -1.7681
Epoch: 0060 D loss: -0.7571 G loss: -1.6957
Epoch: 0061 D loss: -0.7507 G loss: -2.1013
Epoch: 0062 D loss: -0.7624 G loss: -2.0016
Epoch: 0063 D loss: -0.8997 G loss: -1.6240
Epoch: 0064 D loss: -0.7035 G loss: -1.8999
Epoch: 0065 D loss: -0.7890 G loss: -1.6671
Epoch: 0066 D loss: -0.7508 G loss: -1.6910
Epoch: 0067 D loss: -0.7593 G loss: -1.7145
Epoch: 0068 D loss: -0.8873 G loss: -1.6613
Epoch: 0069 D loss: -0.8758 G loss: -1.7970
Epoch: 0070 D loss: -0.8210 G loss: -1.7346
Epoch: 0071 D loss: -0.8191 G loss: -1.8268
Epoch: 0072 D loss: -0.8098 G loss: -1.7033
Epoch: 0073 D loss: -0.8549 G loss: -1.7904
Epoch: 0074 D loss: -0.7877 G loss: -1.8194
Epoch: 0075 D loss: -0.8457 G loss: -1.5673
Epoch: 0076 D loss: -0.8635 G loss: -1.9003
Epoch: 0077 D loss: -0.8762 G loss: -1.5612
Epoch: 0078 D loss: -0.9845 G loss: -1.4545
Epoch: 0079 D loss: -0.8598 G loss: -2.1132
Epoch: 0080 D loss: -0.8108 G loss: -1.2954
Epoch: 0081 D loss: -1.0054 G loss: -1.6819
Epoch: 0082 D loss: -0.8827 G loss: -1.6904
Epoch: 0083 D loss: -0.8544 G loss: -1.5752
Epoch: 0084 D loss: -0.8397 G loss: -1.7697
Epoch: 0085 D loss: -0.7601 G loss: -1.7584
Epoch: 0086 D loss: -0.8847 G loss: -1.5585
Epoch: 0087 D loss: -0.7784 G loss: -1.8776
Epoch: 0088 D loss: -0.8065 G loss: -1.7737
Epoch: 0089 D loss: -0.8339 G loss: -1.7528
Epoch: 0090 D loss: -0.8330 G loss: -1.8131
Epoch: 0091 D loss: -0.8428 G loss: -1.5982
Epoch: 0092 D loss: -0.8034 G loss: -1.9229
Epoch: 0093 D loss: -0.7156 G loss: -1.6945
Epoch: 0094 D loss: -0.8387 G loss: -1.6095
Epoch: 0095 D loss: -0.7017 G loss: -1.6662
Epoch: 0096 D loss: -0.7620 G loss: -1.6581
Epoch: 0097 D loss: -0.7900 G loss: -1.9732
Epoch: 0098 D loss: -0.8118 G loss: -1.8099
Epoch: 0099 D loss: -0.7702 G loss: -1.7755
Epoch: 0100 D loss: -0.7709 G loss: -1.5756
최적화 완료!
9.2 원하는 숫자 생성하기
- 이번에는 숫자를 무작위로 생성하지 않고 원하는 숫자를 지정해 생성하는 모델 생성
필요 라이브러리 Import
import tensorflow as tf
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
데이터 Import
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("./mnist/data/", one_hot=True)
Extracting ./mnist/data/train-images-idx3-ubyte.gz
Extracting ./mnist/data/train-labels-idx1-ubyte.gz
Extracting ./mnist/data/t10k-images-idx3-ubyte.gz
Extracting ./mnist/data/t10k-labels-idx1-ubyte.gz
하이퍼파라미터 정의
total_epoch = 100
batch_size = 100
n_hidden = 256
n_input = 28 * 28
n_noise = 128
n_class = 10
9.2.1 플레이스홀더 설정
- 노이즈에 레이블 데이터를 힌트로 넣어주는 방법 사용
X = tf.placeholder(tf.float32, [None, n_input])
Y = tf.placeholder(tf.float32, [None, n_class])
Z = tf.placeholder(tf.float32, [None, n_noise])
플레이스홀더 Y
- 결괏값 판정용 아님
- 노이즈와 실제 이미지에 각각에 해당하는 숫자를 힌트로 넣어주는 용도로 사용
- MNIST 데이터의 레이블은 원-핫 인코딩한 10개의 값으로 되어 있음
9.2.2 생성자 신경망 구성
- 변수들을 선언하지 않고
tf.layers를 사용 - GAN 모델은 생성자와 구분자를 동시에 학습시켜야 함
- 따라서 학습 시 각 신경망의 변수들을 따로따로 학습시켜야 했음
- 하지만
tf.layers를 사용하면 변수를 선언하지 않고 다음과 같이tf.variable_scope를 이용해 스코프를 지정해줄 수 있음 -
이렇게 하면 나중에 이 스코프에 해당하는 변수들만 따로 불러올 수 있음
- 그런 다음
tf.concat함수를 이용해 noise값에 labels 정보를 간단하게 추가 tf.layers.dense함수를 이용해 은닉층 (hidden)을 만듬- 마찬가지로 진짜 이미지와 같은 크기의 값을 만드는 출력층 (output)도 구성
def generator(noise, labels):
with tf.variable_scope('generator'):
inputs = tf.concat([noise, labels], 1)
hidden = tf.layers.dense(inputs, n_hidden, activation=tf.nn.relu)
output = tf.layers.dense(hidden, n_input, activation=tf.nn.sigmoid)
return output
9.2.3 구분자 신경망 구성
- 생성자 신경망과 같은 방법으로 구분자 신경망을 만듬
주의할 점
- 구분자는 진짜 이미지를 판별할 때와 가짜 이미지를 판별할 때 똑같은 변수를 사용해야 함
- 그러기 위해
scope.reuse_variables함수를 이용해 이전에 사용한 변수를 재사용하도록 작성
def discriminator(inputs, labels, reuse=None):
with tf.variable_scope('discriminator') as scope:
if reuse:
scope.reuse_variables()
inputs = tf.concat([inputs, labels], 1)
hidden = tf.layers.dense(inputs, n_hidden, activation=tf.nn.relu)
output = tf.layers.dense(hidden, 1, activation=None)
return output
- 출력값에 활성화 함수를 사용하지 않음
- 손실값 계산에
sigmoid_cross_entropy_with_logits함수를 사용하기 위함
9.2.4 노이즈 생성
- 노이즈 생성 유틸리티 함수에서 노이즈를 균등분포로 생성하도록 작성
def get_noise(batch_size, n_noise):
return np.random.uniform(-1., 1., size=[batch_size, n_noise])
9.2.5 생성자 및 구성자 생성
- 생성자를 구성
- 진짜 이미지 데이터와 생성자가 만든 이미지 데이터를 이용하는 구분자를 하나씩 만들어 줌
- 이때 생성자에는 레이블 정보를 추가하여 추후 레이블 정보에 해당하는 이미지를 생성할 수 있도록 유도
- 가짜 이미지를 만들 때는 진짜 이미지 구분자에서 사용한 변수들을 재사용하도록
reuse옵션을True로 설정
G = generator(Z, Y)
D_real = discriminator(X, Y)
D_gene = discriminator(G, Y, True)
9.2.6 구분자 학습용 손실값(loss_D) 계산
- Image Completion with Deep Learning in TensorFlow 글을 참고하여 GAN 논문의 방식과는 약간 다르게 손실 함수 생성
D_real
- 진짜 이미지를 판별하는 값
- 1에 가까워지도록 함
D_gene
- 가짜 이미지를 판별하는 값
- 0에 가까워지도록 함
sigmoid_cross_entropy_with_logis 함수를 이용하면 코드를 조금 더 간편하게 작성할 수 있음
loss_D_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_real, labels=tf.ones_like(D_real)))
loss_D_gene = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_gene, labels=tf.zeros_like(D_gene)))
loss_D = loss_D_real + loss_D_gene
loss_D는loss_D_real과loss_D_gene를 합친 것-
이 값을 최소화하면 구분자(경찰)을 학습시킬 수 있음
- 이렇게 되려면 D_real은 1에 가까워야 하고(실제 이미지는 진짜라고 판별), D_gene는 0에 가까워야 한다.(생성한 이미지는 가짜라고 판별)
loss_D-real
D_real의 결과값과D_real의 크기만큼 1로 채운 값들을 비교 (ones_like함수)
loss_D_gene
D_gene의 결과값과D_gene의 크기만큼 0으로 채운 값들을 비교 (zeros_like함수)
9.2.7 생성자 학습용 손실값(loss_G) 계산
loss_G: 생성자(위조지폐범)를 학습시키기 위한 손실값sigmoid_cross_entropy_with_logits함수를 이용하여D_gene를 1에 가깝게 만드는 값을 손실값으로 취함
loss_G = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_gene, labels=tf.ones_like(D_gene)))
9.2.8 최적화 함수 구성
- 텐서플로가 제공하는
tf.get_collection함수를 이용해discriminator와generator스코프에서 사용된 변수들을 가져옴 - 이 변수들을 최적화에 사용할 각각의 손실 함수와 함께 최적화 함수에 넣어 학습 모델 구성을 마무리
vars_D = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='discriminator')
vars_G = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='generator')
train_D = tf.train.AdamOptimizer().minimize(loss_D, var_list=vars_D)
train_G = tf.train.AdamOptimizer().minimize(loss_G, var_list=vars_G)
9.2.9 학습
- 플레이스홀더 Y의 입력값으로
batch_ys값을 넣어주는 것 주의
9.2.10 학습 결과 확인
- 학습 중간중간에 생성자로 만든 이미지를 저장하는 코드 작성
- 플레이스홀더 Y의 입력값을 넣어주는 부분 확인
- 진짜 이미지와 비교해보기 위해 위쪽에는 진짜 이미지를 출력하고, 아래쪽에는 생성한 이미지를 출력
sess = tf.Session()
sess.run(tf.global_variables_initializer())
total_batch = int(mnist.train.num_examples / batch_size)
loss_val_D, loss_val_G = 0, 0
for epoch in range(total_epoch):
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
noise = get_noise(batch_size, n_noise)
_, loss_val_D = sess.run([train_D, loss_D], feed_dict={X: batch_xs, Y: batch_ys, Z: noise})
_, loss_val_G = sess.run([train_G, loss_G], feed_dict={Y: batch_ys, Z: noise})
print('Epoch: ', '%04d' % epoch,
'D loss: {:.4}'.format(loss_val_D),
'G loss: {:.4}'.format(loss_val_G))
# 9.2.10 학습 결과 확인
if epoch == 0 or (epoch+1) % 10 == 0:
sample_size = 10
noise = get_noise(sample_size, n_noise)
samples = sess.run(G, feed_dict={Y: mnist.test.labels[:sample_size], Z: noise})
fig, ax = plt.subplots(2, sample_size, figsize=(sample_size, 2))
for i in range(sample_size):
ax[0][i].set_axis_off()
ax[1][i].set_axis_off()
ax[0][i].imshow(np.reshape(mnist.test.images[i], (28, 28)))
ax[1][i].imshow(np.reshape(samples[i], (28, 28)))
plt.savefig('ch09/samples3/{}.png'.format(str(epoch).zfill(3)), bbox_inches='tight')
plt.close(fig)
print('최적화 완료!')
Epoch: 0000 D loss: 0.01216 G loss: 7.923
Epoch: 0001 D loss: 0.009068 G loss: 8.947
Epoch: 0002 D loss: 0.01319 G loss: 7.376
Epoch: 0003 D loss: 0.01164 G loss: 7.238
Epoch: 0004 D loss: 0.02879 G loss: 7.419
Epoch: 0005 D loss: 0.06732 G loss: 9.02
Epoch: 0006 D loss: 0.046 G loss: 7.713
Epoch: 0007 D loss: 0.1212 G loss: 7.944
Epoch: 0008 D loss: 0.0554 G loss: 7.596
Epoch: 0009 D loss: 0.09603 G loss: 6.804
Epoch: 0010 D loss: 0.07182 G loss: 6.612
Epoch: 0011 D loss: 0.3079 G loss: 3.848
Epoch: 0012 D loss: 0.176 G loss: 5.156
Epoch: 0013 D loss: 0.258 G loss: 4.7
Epoch: 0014 D loss: 0.2213 G loss: 4.922
Epoch: 0015 D loss: 0.5062 G loss: 3.315
Epoch: 0016 D loss: 0.4972 G loss: 3.416
Epoch: 0017 D loss: 0.4266 G loss: 4.159
Epoch: 0018 D loss: 0.6634 G loss: 3.931
Epoch: 0019 D loss: 0.4229 G loss: 2.776
Epoch: 0020 D loss: 0.6514 G loss: 2.506
Epoch: 0021 D loss: 0.6768 G loss: 2.813
Epoch: 0022 D loss: 0.6133 G loss: 3.04
Epoch: 0023 D loss: 0.7854 G loss: 2.379
Epoch: 0024 D loss: 0.6701 G loss: 2.615
Epoch: 0025 D loss: 0.8469 G loss: 2.477
Epoch: 0026 D loss: 0.7099 G loss: 2.197
Epoch: 0027 D loss: 0.889 G loss: 1.885
Epoch: 0028 D loss: 0.5902 G loss: 2.301
Epoch: 0029 D loss: 0.4334 G loss: 2.718
Epoch: 0030 D loss: 0.763 G loss: 2.461
Epoch: 0031 D loss: 0.7462 G loss: 2.059
Epoch: 0032 D loss: 0.8536 G loss: 2.199
Epoch: 0033 D loss: 0.9273 G loss: 2.438
Epoch: 0034 D loss: 0.7546 G loss: 2.219
Epoch: 0035 D loss: 0.7201 G loss: 2.198
Epoch: 0036 D loss: 0.7723 G loss: 2.051
Epoch: 0037 D loss: 0.8882 G loss: 1.834
Epoch: 0038 D loss: 0.8636 G loss: 2.125
Epoch: 0039 D loss: 0.967 G loss: 2.053
Epoch: 0040 D loss: 0.647 G loss: 2.478
Epoch: 0041 D loss: 0.7024 G loss: 1.943
Epoch: 0042 D loss: 0.7915 G loss: 2.018
Epoch: 0043 D loss: 0.7785 G loss: 1.764
Epoch: 0044 D loss: 0.8206 G loss: 2.216
Epoch: 0045 D loss: 0.7671 G loss: 1.968
Epoch: 0046 D loss: 0.6571 G loss: 2.113
Epoch: 0047 D loss: 0.7049 G loss: 2.062
Epoch: 0048 D loss: 0.7186 G loss: 2.43
Epoch: 0049 D loss: 0.8017 G loss: 1.988
Epoch: 0050 D loss: 0.702 G loss: 2.323
Epoch: 0051 D loss: 0.7178 G loss: 1.919
Epoch: 0052 D loss: 0.7388 G loss: 2.186
Epoch: 0053 D loss: 0.6944 G loss: 2.326
Epoch: 0054 D loss: 0.8218 G loss: 2.327
Epoch: 0055 D loss: 0.8417 G loss: 2.296
Epoch: 0056 D loss: 0.6732 G loss: 2.18
Epoch: 0057 D loss: 0.7328 G loss: 2.284
Epoch: 0058 D loss: 0.8505 G loss: 2.145
Epoch: 0059 D loss: 0.7305 G loss: 2.24
Epoch: 0060 D loss: 0.5159 G loss: 2.278
Epoch: 0061 D loss: 0.7111 G loss: 2.048
Epoch: 0062 D loss: 0.761 G loss: 2.241
Epoch: 0063 D loss: 0.7827 G loss: 2.085
Epoch: 0064 D loss: 0.7492 G loss: 2.291
Epoch: 0065 D loss: 0.7227 G loss: 1.929
Epoch: 0066 D loss: 0.7131 G loss: 2.219
Epoch: 0067 D loss: 0.8709 G loss: 1.67
Epoch: 0068 D loss: 0.7446 G loss: 2.313
Epoch: 0069 D loss: 0.617 G loss: 2.156
Epoch: 0070 D loss: 0.7804 G loss: 2.009
Epoch: 0071 D loss: 0.8814 G loss: 1.97
Epoch: 0072 D loss: 0.6877 G loss: 2.485
Epoch: 0073 D loss: 0.7445 G loss: 2.254
Epoch: 0074 D loss: 0.9026 G loss: 2.102
Epoch: 0075 D loss: 0.722 G loss: 2.352
Epoch: 0076 D loss: 0.6192 G loss: 2.483
Epoch: 0077 D loss: 0.9154 G loss: 1.802
Epoch: 0078 D loss: 0.8655 G loss: 1.893
Epoch: 0079 D loss: 0.8849 G loss: 1.954
Epoch: 0080 D loss: 0.7458 G loss: 1.991
Epoch: 0081 D loss: 0.8958 G loss: 2.358
Epoch: 0082 D loss: 0.7683 G loss: 1.904
Epoch: 0083 D loss: 0.9716 G loss: 1.691
Epoch: 0084 D loss: 0.6237 G loss: 1.971
Epoch: 0085 D loss: 0.7879 G loss: 2.045
Epoch: 0086 D loss: 0.8248 G loss: 2.052
Epoch: 0087 D loss: 0.8883 G loss: 1.818
Epoch: 0088 D loss: 0.6335 G loss: 1.948
Epoch: 0089 D loss: 0.8071 G loss: 2.098
Epoch: 0090 D loss: 0.7211 G loss: 2.039
Epoch: 0091 D loss: 0.8479 G loss: 2.389
Epoch: 0092 D loss: 0.7225 G loss: 2.301
Epoch: 0093 D loss: 0.6246 G loss: 2.273
Epoch: 0094 D loss: 0.7478 G loss: 2.052
Epoch: 0095 D loss: 0.8241 G loss: 1.851
Epoch: 0096 D loss: 0.7065 G loss: 2.119
Epoch: 0097 D loss: 0.7499 G loss: 1.9
Epoch: 0098 D loss: 0.7862 G loss: 2.307
Epoch: 0099 D loss: 0.6957 G loss: 1.951
최적화 완료!
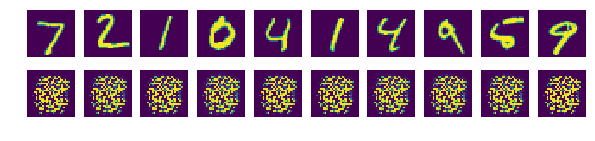
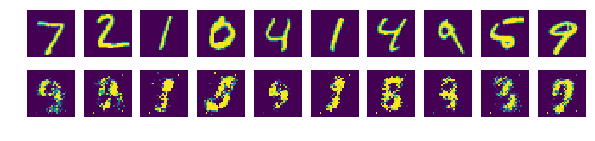
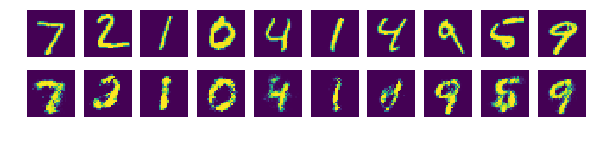








- 노이즈가 무작위로 만들어지니 매번 조금씩 다른 이미지가 생성
- 중요한 것은 생성된 이미지들은 MNIST 데이터에 없는 새로운 솔글씨 이미지라는 것
9.2.11 전체 코드
import tensorflow as tf
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("./mnist/data/", one_hot=True)
##########
# 옵션 설정
##########
total_epoch = 100
batch_size = 100
n_hidden = 256
n_input = 28 * 28
n_noise = 128
n_class = 10
##########
# 신경망 모델 구성
##########
# 9.2.1
X = tf.placeholder(tf.float32, [None, n_input])
Y = tf.placeholder(tf.float32, [None, n_class])
Z = tf.placeholder(tf.float32, [None, n_noise])
# 9.2.2
def generator(noise, labels):
with tf.variable_scope('generator'):
inputs = tf.concat([noise, labels], 1)
hidden = tf.layers.dense(inputs, n_hidden, activation=tf.nn.relu)
output = tf.layers.dense(hidden, n_input, activation=tf.nn.sigmoid)
return output
# 9.2.3
def discriminator(inputs, labels, reuse=None):
with tf.variable_scope('discriminator') as scope:
if reuse:
scope.reuse_variables()
inputs = tf.concat([inputs, labels], 1)
hidden = tf.layers.dense(inputs, n_hidden, activation=tf.nn.relu)
output = tf.layers.dense(hidden, 1, activation=None)
return output
# 9.2.4
def get_noise(batch_size, n_noise):
return np.random.uniform(-1., 1., size=[batch_size, n_noise])
# 9.2.5
G = generator(Z, Y)
D_real = discriminator(X, Y)
D_gene = discriminator(G, Y, True)
# 9.2.6
loss_D_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_real, labels=tf.ones_like(D_real)))
loss_D_gene = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_gene, labels=tf.zeros_like(D_gene)))
loss_D = loss_D_real + loss_D_gene
# 9.2.7
loss_G = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_gene, labels=tf.ones_like(D_gene)))
# 9.2.8
vars_D = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='discriminator')
vars_G = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='generator')
train_D = tf.train.AdamOptimizer().minimize(loss_D, var_list=vars_D)
train_G = tf.train.AdamOptimizer().minimize(loss_G, var_list=vars_G)
##########
# 신경망 모델 학습
##########
# 9.2.9
sess = tf.Session()
sess.run(tf.global_variables_initializer())
total_batch = int(mnist.train.num_examples / batch_size)
loss_val_D, loss_val_G = 0, 0
for epoch in range(total_epoch):
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
noise = get_noise(batch_size, n_noise)
_, loss_val_D = sess.run([train_D, loss_D], feed_dict={X: batch_xs, Y: batch_ys, Z: noise})
_, loss_val_G = sess.run([train_G, loss_G], feed_dict={Y: batch_ys, Z: noise})
print('Epoch: ', '%04d' % epoch,
'D loss: {:.4}'.format(loss_val_D),
'G loss: {:.4}'.format(loss_val_G))
##########
# 확인용 이미지 생성
##########
# 9.2.10
if epoch == 0 or (epoch+1) % 10 == 0:
sample_size = 10
noise = get_noise(sample_size, n_noise)
samples = sess.run(G, feed_dict={Y: mnist.test.labels[:sample_size], Z: noise})
fig, ax = plt.subplots(2, sample_size, figsize=(sample_size, 2))
for i in range(sample_size):
ax[0][i].set_axis_off()
ax[1][i].set_axis_off()
ax[0][i].imshow(np.reshape(mnist.test.images[i], (28, 28)))
ax[1][i].imshow(np.reshape(samples[i], (28, 28)))
plt.savefig('ch09/samples4/{}.png'.format(str(epoch).zfill(3)), bbox_inches='tight')
plt.close(fig)
print('최적화 완료!')
더 해보기
- 학습 결과를
Saver를 통해 저장한 뒤 숫자를 임의로 넣어 생성성하는 프로그램 만들기 - 생성자와 구분자를 CNN으로 구성한 모델 만들기
9.3 더 보기
- GAN 이론에 관해서는 다음 블로그에서 쉽고 자세하게 설명해주고 있음
- GAN에 관심이 간다면 참고
댓글남기기