ML study > Object Detection > Two stage detection
R-CNN
-
R-CNN은 Image classification에서 성공을 거둔 CNN과 region proposal에서 널리 사용되는 selective search 방식을 generic object detection에 결합한 방식이다.
-
따라서 R-CNN은 다음과 같은 multi-stage로 구분되어 동작한다.
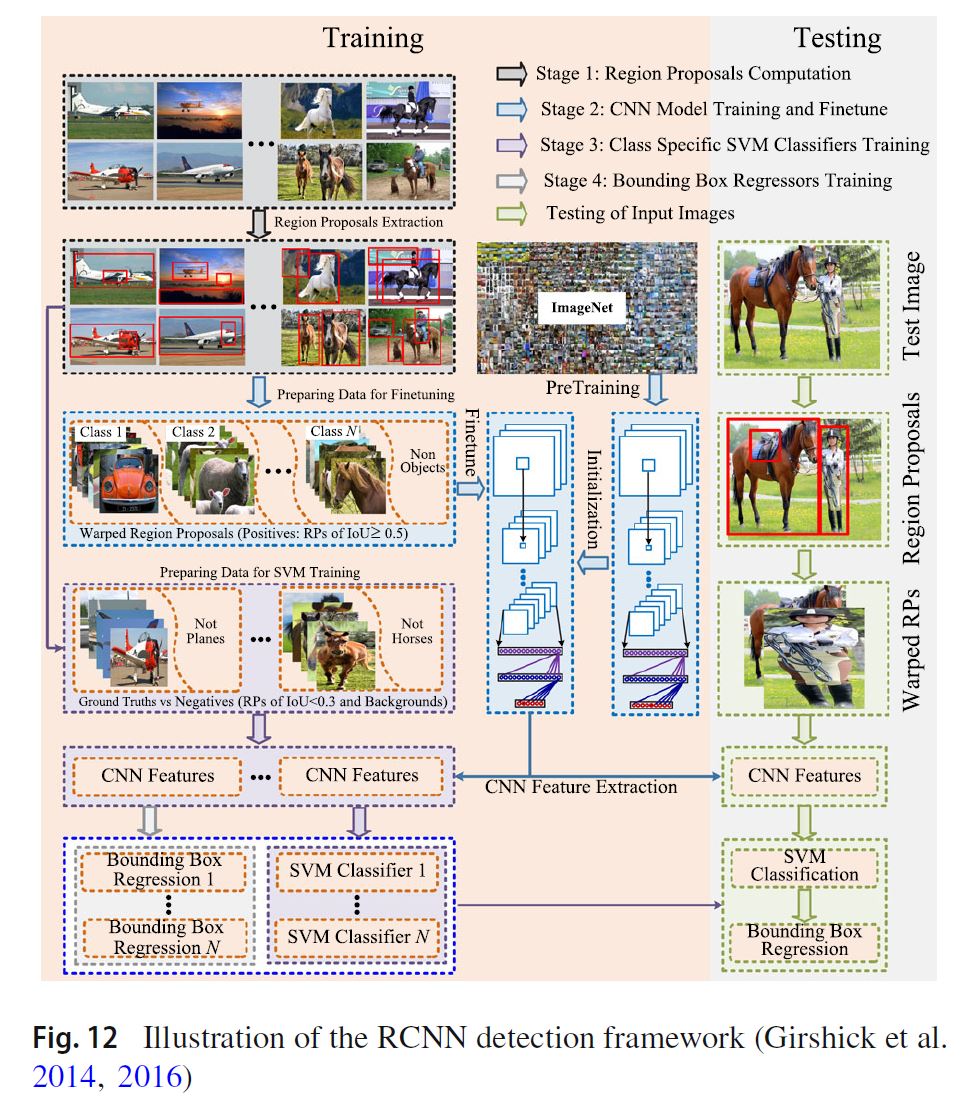
1. R-CNN 동작
1.1. Region proposal computation
우선 이미지에서 물체가 있을 법한 곳을 selective search 로 뽑아내고 CNN 의 입력사이즈에 맞추어 warping 시킨다.
1.2. CNN model finetuning
CNN model은 먼저 ImageNet에서 pretraining 시키고 object detection image data를 넣어 fine tuning 시킨다. 이때 CNN의 마지막 layer는 class 갯수에 해당하는 크기로 맞추고 IOU가 0.5 이상인 것을 positive 아닌 것은 negative로 두었다.
1.3. Class specific SVM classifier training
CNN에서 나온 feature가 SVM classifier의 input으로 들어가고 IOU가 0.3 보다 작은 것은 negative, 그렇지 않은 것은 positive로 처리하여 training 하였다.
** IoU 기준이 CNN model과 다른 것은 fine tuning 이후 실험결과 다른 값을 쓰는게 결과가 더 좋았기 때문이며 fine-tuning data가 부족한 것을 원인으로 들었다. 또한 softmax classifier를 그대로 쓰기 않고 SVM을 사용한 이유에 대해서도 SVM을 추가하였을 때 성능이 더 좋게 나와서 이지만 향후 조정을 통해 SVM 없이도 training 가능할 것이라 전망했다.
1.4. Class specific bounding box regressor training
Bounding box regression 은 CNN의 feature를 input으로 받아 각각의 class에 대해 학습된다.
2. R-CNN 결과
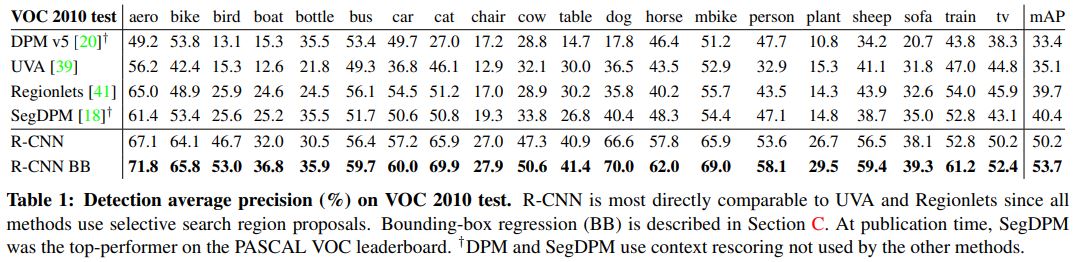
- 실험결과 VOC2010 test set 기준 이전의 방식들 보다 훨씬 향상된 성능을 보인다.
3. R-CNN 단점
-
Training 이 multi stage로 진행되어야 해서 최적화하기 어렵고 느리다.
-
SVM과 bounding box regressor training 과정에서 object proposal 마다 뽑아낸 feature들로 진행하기 때문에 느려진다.
-
이미지안에서 object proposal 마다 CNN을 수행하기 때문에 test 과정역시 느리다.
이러한 단점들을 극복하기 위해 SPPNet, Fast R-CNN, Faster R-CNN 등이 제시되었다.
Reference
[1]: Deep Learning for Generic Object Detection: A Survey
[2]: R-CNN 논문
댓글남기기