Development > Touch Application > Anomaly Detection based Touch
1. Anomaly Detection based Touch
-
SVM based Touch System 이 기존 터치 방식에 비해서는 굉장히 많은 이점들을 가지고 있지만 터치, 비터치, 그리고 스타일러스까지 총 3가지 data에 대해 training을 시켜주어야 했다. 터치와 비터치의 경우 하나의 터치 시스템에서는 거의 일정하게 동작을 하지만 스타일러스의 경우 output 파형의 voltage frequency에 따라서 새롭게 training 해주어야 정확한 동작이 가능하다.
-
이러한 문제는 Machine learning에서 Auto-encoder 모델을 사용하여 해결할 수 있다. Auto-encoder는 Input 과 Output 이 동일하며 중간의 hidden layer의 뉴런 수를 input layer보다 작게 해서 데이터의 차원을 줄인 다음 다시 원래의 Input을 복원해내는 network이다. 이렇게 하면 중간의 hidden layer는 input의 특징을 가장 잘 나타낼 수 있는 feature 로서 구성될 것이다.

- 이제 이러한 구조의 auto encoder를 가지고 어떻게 stylus를 training 시키지 않고 구분이 가능해지는지 살펴보자. 위 그림은 제안하는 방식의 auto-encoder 구조이다. 먼저 encoder (Finger-Touch Detection) 부분은 터치와 비터치 데이터 sequence와 그에 해당하는 label을 가지고 classification 문제로 training 시켜준다. 이어서 decoder (Sequence Generation) 부분에서는 encoder로 부터 나온 출력을 받아 Input data를 복원하도록 training을 시킨다. 결과적으로 auto-encoder의 model은 터치, 비터치와 그에 따른 reconstructed sequence 사이의 error가 최소화 되도록 훈련된다. 이 때 만약 Input에 stylus의 sequence가 들어간다면 error가 굉장히 크게 나올 것이며 그렇게 나온 Reconstruction Error를 가지고 stylus의 training 없이 구분이 가능해지는 것이다.
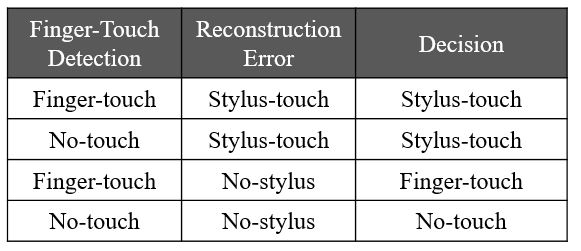
- 정리하자면 위 표와 같이 3가지 경우에 대한 최종 decision이 이루어 진다. Reconstruction Error로부터 Stylus-touch를 판단하고 그렇지 않은 경우에는 Encoder (Finger-Touch Detection) 에서 나온 classification 결과로 부터 최종 decision이 가능하게 된다.
2. Anomaly Detection based Touch 결과
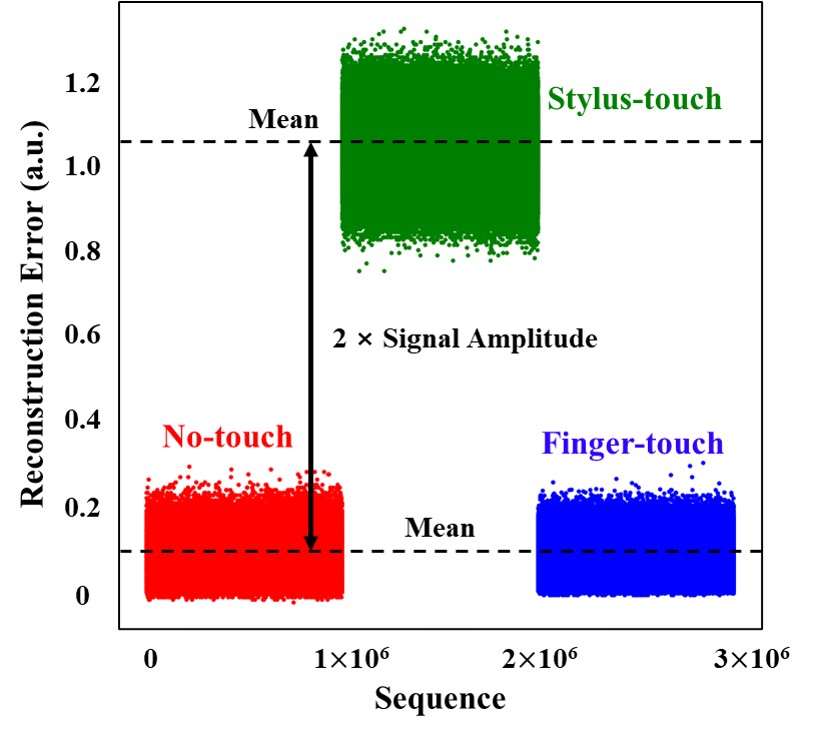
- 위 그래프는 3가지 경우의 Sequence 각각 100만개에 따른 Reconstruction Error를 plot 한 것이다. Training 시킨 No-touch 와 Finger-touch 는 error가 작게 나오는 것을 확인할 수 있고 Stylus-touch는 error 가 커지는 것을 확인할 수 있다.

-
앞선 그래프로 부터 SNR을 구하여 이전 SVM 방식과 비교해보면 0.27dB 정도 낮게 나오지만 큰 performance의 차이는 없는 것을 확인할 수 있다. 반면 parameter의 경우 SVM 방식에서 400개가 사용되었지만 Anomaly detection 방식에서는 단 16개로 computation cost를 굉장히 낮추었다.
-
Anomaly detection 방식을 통해 stylus training 과정을 없앴을 뿐아니라 SVM 방식과 비슷한 SNR을 유지하면서 hardware complexity를 대폭 낮출 수 있었다.
Reference
[1]: SVM based Touch Communication
[2]: Anomaly Detection based Touch
댓글남기기