ML study > Object Detection > One stage detection
OverFeat
- OverFeat 역시 DetectorNet과 비슷한 시기에 나온 network 중 하나로 region proposal network 없이 one stage로 동작하며 DetectorNet과 동일한 network 을 사용하였지만 하나의 네트워크로 다양한 class 에대한 object detection을 가능하게 하였으며 ILSVRC2013 localization and competeition 에서 우승을 차지하면서 유명해졌다.
1. OverFeat 동작

- OverFeat은 위 그림과 같이 feature extractor로는 AlexNet 과 비슷한 구조를 사용하였고 이후 FC layer 대신 1x1 Conv network을 사용하여 다양한 input이 통과가능하도록 하였으며 classifier와 bb regressor는 weight를 공유하여 Class과 BBox를 함께 training하고 예측가능하도록 구성하였다.
-
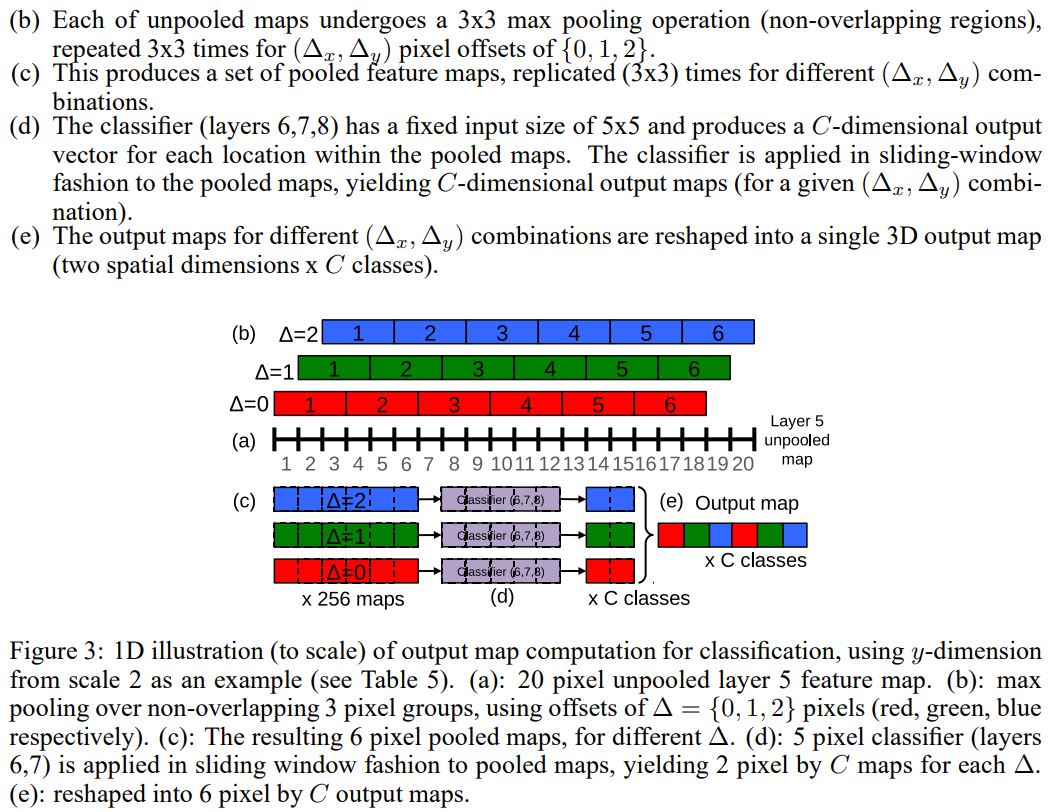
이 때 Image가 CNN을 계속 통과하면 feature map이 너무 작아지게 되어 input image map을 제대로 표현할 수 없어지는 문제가 발생한다. 이에 저자는 offset max pooling 방식을 제안한다.
-
feature extractor의 마지막 pooling layer를 통과하기 전 feature map의 size가 그림 (a)와 같이 20 이라고 하자. 여기서 stride 3으로 3개씩 pooling을 진행하면 feature map size는 6이 된다. 하지만 그림 (b) 와 같이 pooling을 (1~18), (2~19), (3~20) 에 적용하게 되면 feature map이 6x3이 되어 나온다. 따라서 조금 더 많은 정보의 feature를 담을 수 있게 된다.
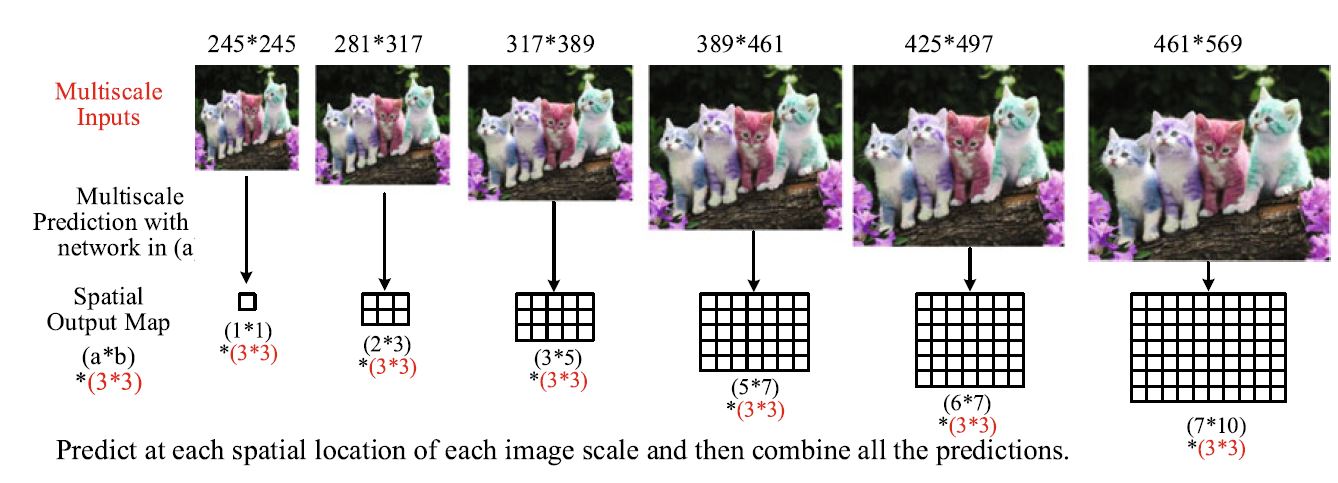
- 또한 다양한 크기의 object를 detect할 수 있도록 그림과 같이 다양한 scale을 input으로 주고 각각의 scale에서 나온 output을 최종적으로 종합하여 prediction하였다.

- 이렇게 각각의 scale과 spatial map 마다 BBox regression과 classification이 이루어지기 때문에 하나의 image에 대해 그림과 같이 다양한 BBox가 나오게 된다.


- 이것을 하나로 합치는 과정은 다음과 같다. 먼저 classifier에서 나온 output으로 부터 제일 높은 값의 category를 할당시키고 BBox 역시 할당시킨다. 이 후 BBox 2개를 뽑아서 center거리와 IoU로 부터 match score를 구하고 특정 값보다 높다면 그 박스를 유지하고 그렇지 않다면 2개의 box 좌표를 평균내서 합쳐준다. 이렇게 되면 match score 가 특정 값 이상인 box들만 남아있게 되고 이 때 가장 높은 class score를 지닌 box를 선택하게 된다.
2. OverFeat 결과
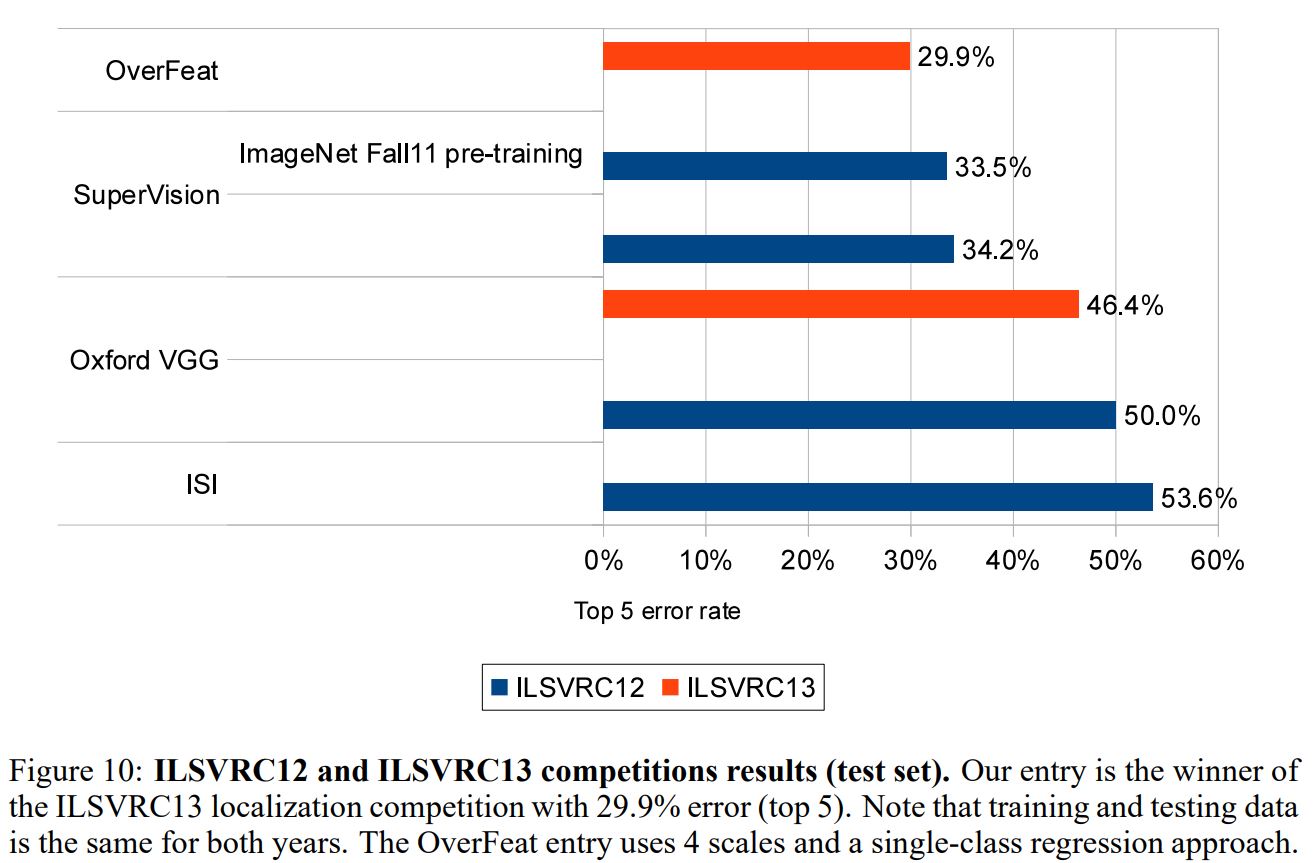
OverFeat은 ILSVRC13 dataset 기준으로 Top 5 error rate이 29.9%로 ILSVRC localization 분야에서 우승하였다. mAP 성능으로는 24.3 정도가 나왔으며 이후 나온 RCNN(31.4) 보다는 떨어지는 성능이다. 속도는 논문에 언급은 없지만 찾아보니 10 FPS 정도가 나온다고 한다.
아무래도 BB를 예측하는데 있어 이후 모델들에서 나오는 anchor box와 같은 제약이 없기 때문에 완벽한 training이 어려워 mAP 성능이 낮게 나오지 않았을까 싶다.

Reference
[1]: Deep Learning for Generic Object Detection: A Survey
[2]: OverFeat
댓글남기기