ML study > Object Detection > One stage detection
SSD
- SSD는 YOLO가 비록 높은 speed를 구현했지만 mAP가 two stage에 비해 상대적으로 낮은 것을 지적하며 빠르면서도 정확한 모델을 제시하였다.
1. SSD 동작
1.1 구조
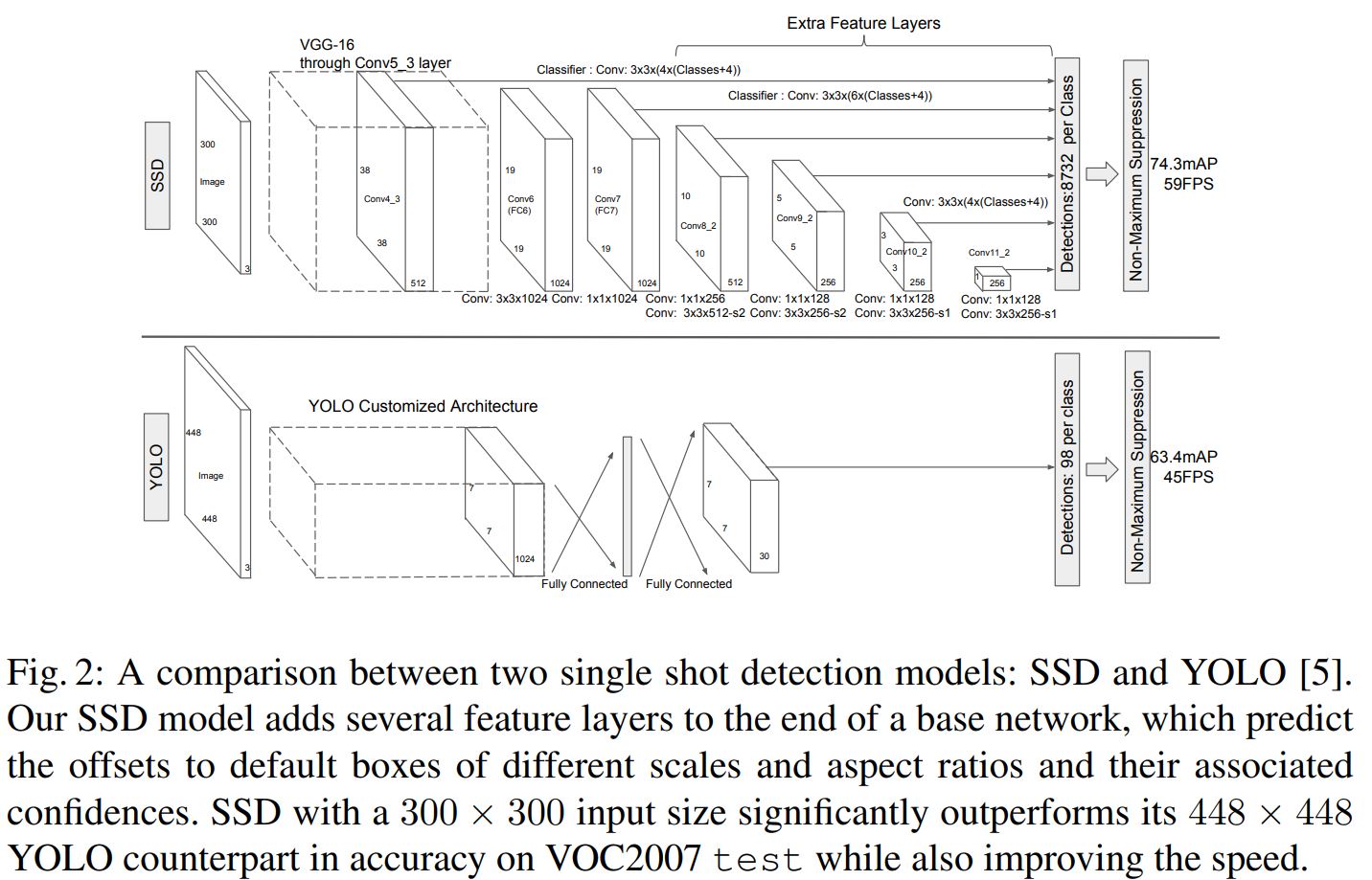
- 위 그림은 SSD 논문에서 YOLO와의 비교를 위해 나타낸 그림으로서 두 모델의 구조적차이가 확연히 보인다. 기존 YOLO에서는 input image를 받아 cumstomized 된 feature extractor를 통과하고 FC layer를 거쳐 클래스당 98개의 detection을 진행한다. 반면 SSD는 VGG-16의 일부를 backbone network로 사용했고 이후 나온 feature map을 한 번만 detection하는 것이 아니라 conv network를 통과할 때마다 detection이 일어나도록 하고 최종적으로 클래스당 8732개의 detection이 일어나게 된다. 이렇게 되면 다양한 size의 feature map으로 부터 detection을 진행하기 때문에 작은 크기의 물체도 detect 할 수 있게 되어 mAP 성능 향상을 이끌어 낼 수 있다.
-
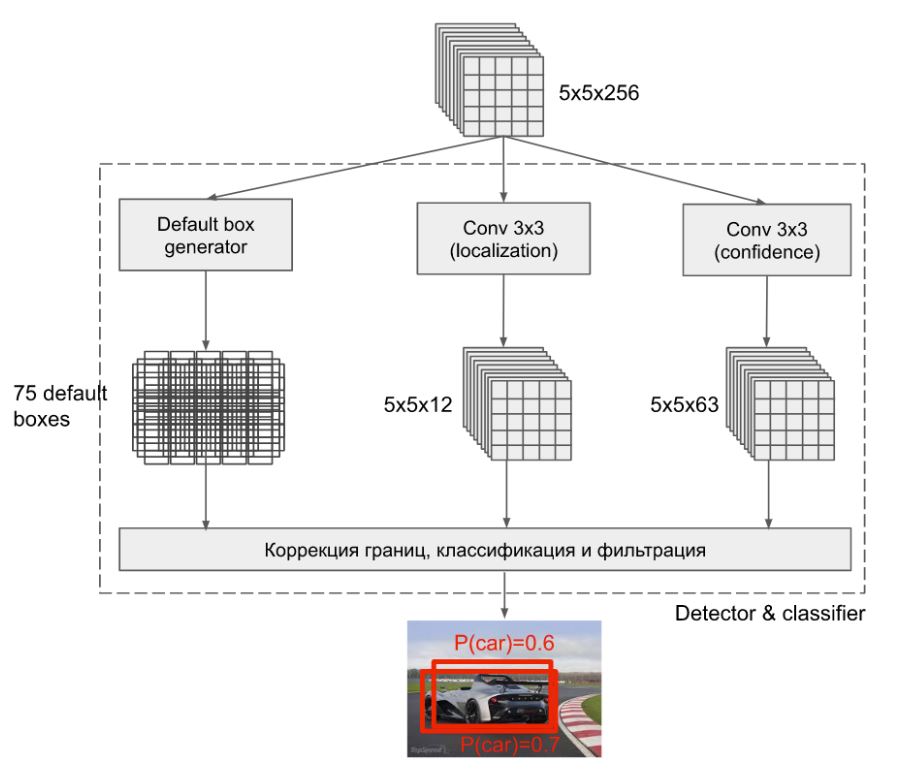
구체적인 detection 과정은 위 그림과 같이 YOLO와 거의 동일하다. backbone을 통과한 feature map이 5x5x256인 경우를 살펴보자. 5x5는 YOLO에서의 grid size를 의미하며 grid 마다 3개의 anchor box를 만들어 낸다. 따라서 Default box generator에서 75개의 box가 만들어지는 것이다.
-
두 번째로 localization을 위해 conv net을 한번 통과시켜 5x5x12로 만드는데 이 때 anchor box (3개) 마다 box의 좌표(4개)를 나타내기 위해서 channel 수가 12 (3x4) 가 되는 것이다.
-
마지막으로 confidence는 anchor box마다 class probability를 mapping 시켜주는 것으로 PASCAL VOC data 기준으로 배경을 포함하여 21개의 class가 존재하므로 channel 수는 63 (3x21) 이 된다. 이로 부터 bounding box와 class를 mapping 할 수 있게 되며 마지막으로 non maximum suppression 과정을 거쳐 최종 BB를 추론하게 된다.
1.2 Training
- Training 을 위해 각각의 ground truth에 IoU 0.5 이상인 default box를 matching 시켜 training 하였으며 Hard negative mining 기법을 사용하여 negative : positive 의 비율이 3:1이 되도록 training 하였다.
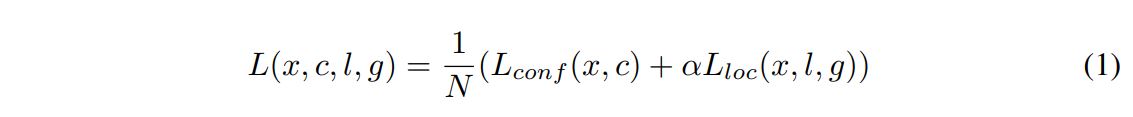
- Loss function은 Faster R-CNN과 동일하게 confidence loss (multiple class에 대한 softmax loss)와 localization loss (L1 loss between predicted box and ground truth box) 의 합으로 설정하였다.

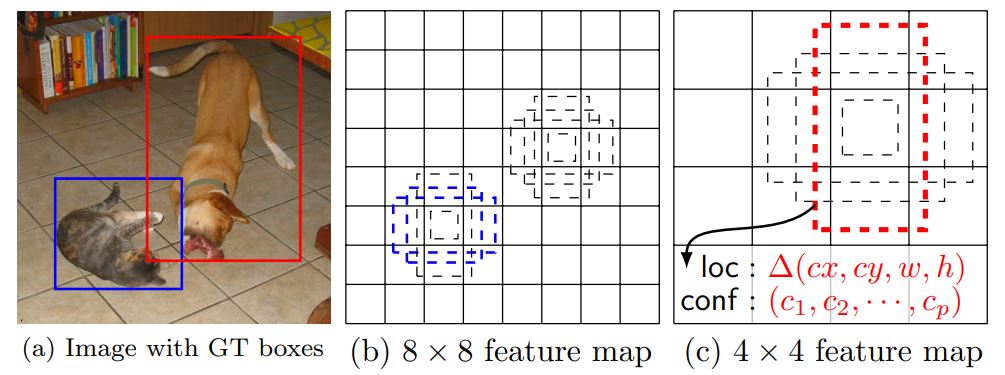
- Default box 는 위 수식과 같이 scale과 aspect ratio이 다르게하여 feature map마다 k개의 box가 나오도록 결정하였다. 이렇게 되면 아래 그림과 같이 각각의 feature map에서 동일한 box가 적용되었을 때 다양한 size의 object에 대해 detect할 수 있게 된다.
2. SSD 결과
PASCAL VOC 2007에 대해서 실험한 결과 input size와 batch size에 따라서 74~76 mAP 성능을 얻었으며 SSD 300에서는 Faster RCNN과 YOLO 보다 더 빠르고 높은 정확도를 보였다.

Reference
[1]: Deep Learning for Generic Object Detection: A Survey
[2]: SSD
[3]: SSD 설명블로그
댓글남기기