ML study > Object Detection > One stage detection
YOLOv3
- YOLOv3에서는 YOLOv2 보다 YOLOv2보다 network는 deep해졌지만 mAP 성능을 개선시켰다.
1. YOLOv3 동작
1.1 Bounding Box Prediction
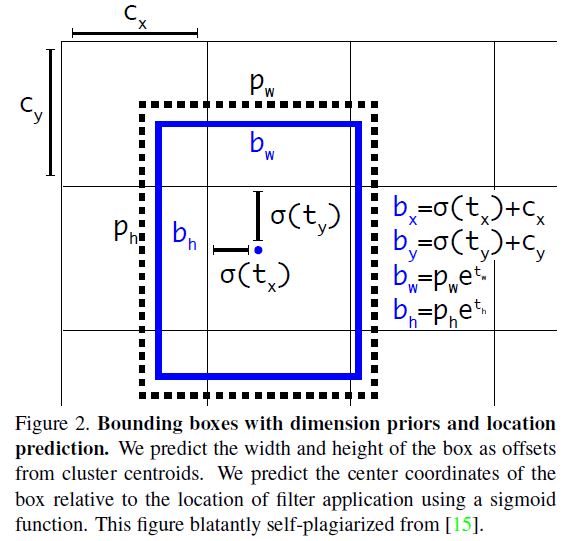
- BBox prediction 부분은 위 그림과 같이 YOLOv2와 거의 동일하다. center 범위에 제약을 준 상태에서 regression 하게 하였으며 ground truth 하나에 가장 높은 IoU를 가지는 box 하나만 mapping 시켜 training 하였다.
1.2 Class Prediction
- YOLOv3에서는 class prediction시 softmax함수를 사용하지 않고 각각의 class에 대해서 sigmoid를 적용시켜 training 하였으며 이렇게 하면 Open Images Dataset과 같이 하나의 object에 대해 여러개의 label 이 붙는 경우 (Woman and Person) 더 유용하게 사용될 수 있다.
1.3 Predictions Across Scales
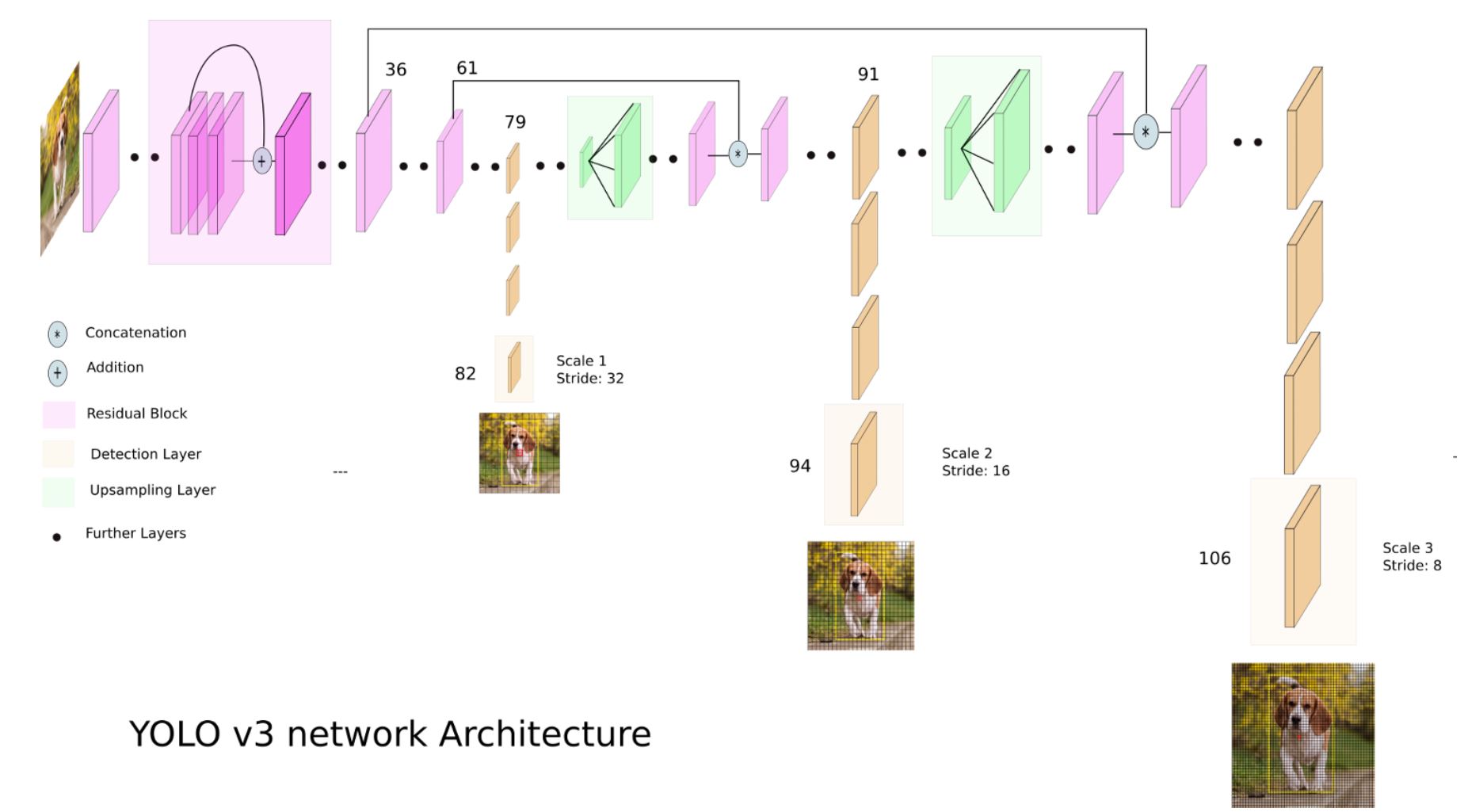
- YOLOv3는 이전 방식과 다르게 3가지 scale에 대해서 prediction을 진행하며 FPN (feature pyramid networks) 과 비슷한 concept을 적용하였다.
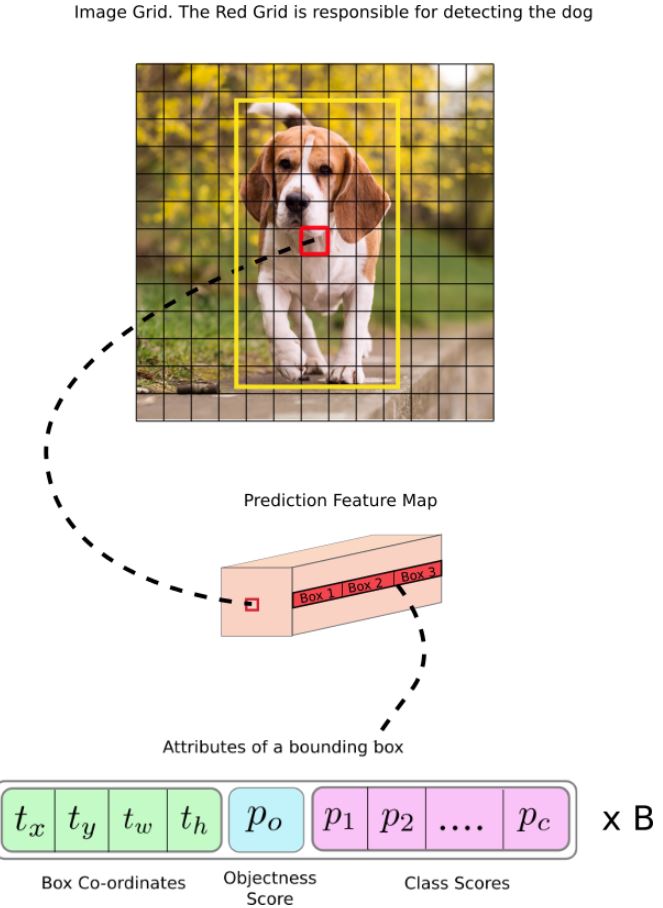
- COCO dataset에서 각 scale의 cell 마다 3개의 box를 예측하였으며 tensor 크기는 N x N [3 * (4+1+80)] 이 된다.
-
이렇게 나온 scale feature map을 2배로 upsampling 하고 이전 layer와 concat한 뒤 동일한 예측을 수행하게 하였다.
-
똑같은 과정을 한 번 더 걸쳐 3개의 scale에 대해 prediction이 일어나게 하였으며 하나의 layer에서 prediction한 SSD 보다 조금 더 높은 성능을 얻을 수 있을 것으로 보인다.
-
YOLOv2에서와 마찬가지로 anchor box size를 구할 때 k-means clustering을 통해 결정하였다.
1.4 Feature Extractor

- Feature extractor로는 YOLOv2 에서 사용한 Darknet-19 를 조금 더 deep하게 만든 Darknet-53 을 사용하였다. 기존 model들과 비교해서 가장 높은 floating point opreations per second (BFLOP/s) 를 기록하였으며 accuracy는 ResNet과 비슷한 수준을 유지하면서 FPS 는 2배 높은 속도를 얻었다.
2. YOLOv3 결과
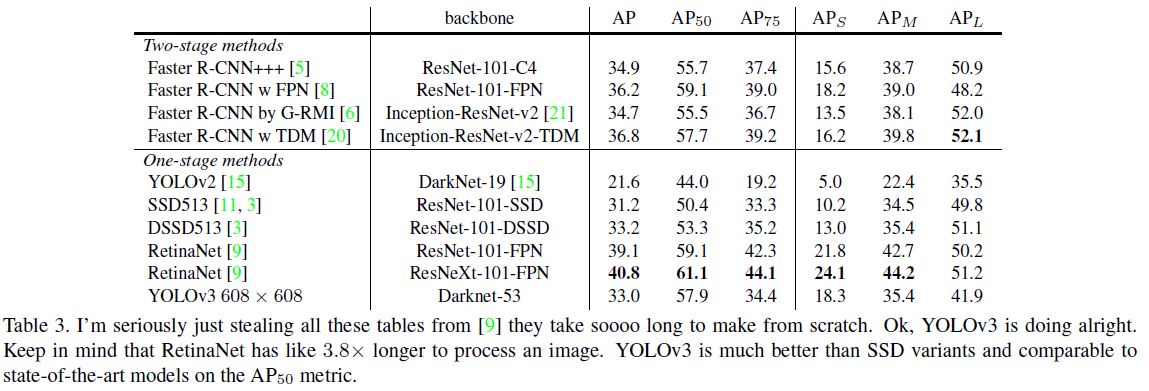
MS COCO dataset에서 실험결과 YOLOv3는 SSD, DSSD와 비슷한 mAP를 얻었고 RetinaNet 보다는 다소 낮지만 inference time 측면에서는 RetinaNet, SSD 방식 보다 훨씬 빠른 결과를 얻었다.
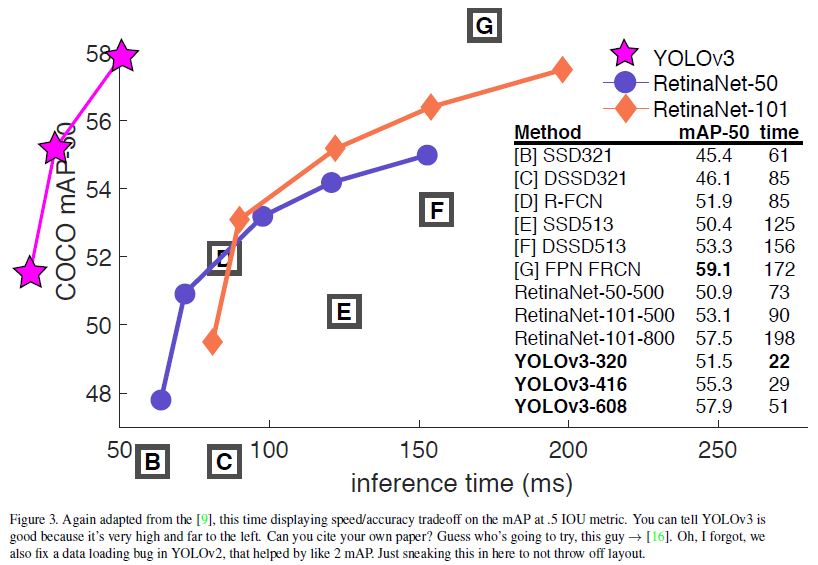
-
추가로 저자는 MS COCO에서 AP 측정이 IoU threshold level을 0.5 ~ 0.95 까지 다양하게 측정한 것을 평균내어 사용하는데 실제 사람이 IoU threshold 에 따른 차이를 별로 인지하지 못하기 때문에 0.5에 대해서만 결과값을 보는 것이 더 의미있을 수 있다고 말한다.
-
또한 기존 mAP 측정 방식 자체에 대해서도 극단적인 경우, 아래 그림과 같이 detector1 과 detector2 를 보았을 때 detector 1이 훨씬 잘예측한 결과라고 할 수 있지만 현재 계산에 따르면 recall이 100일 때 precision이 100이면 mAP역시 100이 되므로 아래 두 결과모두 mAP 100이라는 결과를 얻게 된다. 따라서 성능을 판가름하는 mAP 역시 개선의 여지가 있다고 주장하고 있다.

Reference
[1]: YOLOv3
[2]: YOLOv3 설명 블로그
[3]: YOLOv3 설명 블로그2
댓글남기기