ML study > Object Detection > One stage detection
YOLOv2
- YOLO가 굉장한 속도 향상을 이루었지만 Fast RCNN과 Faster RCNN보다 mAP 성능이 떨어진다는 한계가 있었다. YOLOv2에서는 YOLO의 속도를 유지하면서 mAP 성능까지 개선시켰다.
1. 동작
1.1 YOLOv2
- YOLOv2는 다음과 같은 측면에서 YOLO를 개선시켰다.
1.1.1 Batch Normalization
- Regularization을 위해 Batch normalization를 적용시켰고 2% 이상의 mAP 성능을 향상시켰다.
1.1.2 High Resolution Classifier
- 고해상도인 ImageNet 으로 model을 pretraining 시키기위해 기존 YOLO의 network input size (224 x 224)를 2배(448 x 448)로 늘려 사용했으며 4% 정도의 mAP 성능향상이 있었다고 한다.
1.1.3 Convolutional With Anchor Boxes
-
YOLO 에서는 하나의 grid cell에서 2개의 bounding box를 예측했지만 classification score는 동일하게 적용되었다. 즉, 하나의 grid cell에서 하나의 objcet 만이 있다고 가정하기 때문에 중심은 같지만 여러개의 object를 detect하기 어려웠다.
-
따라서 YOLOv2에서는 Faster RCNN에 적용되었던 anchor box 개념을 가져와 anchor box 마다 BBox, confidence, class probability가 출력되도록 만들었다.
-
더불어 FC layer를 Conv network로 바꾸고 input size 를 홀수로 바꾸었는데 이는 물체가 가운데 위치할 가능성이 크고 그럴 경우 최종 feature map 역시 홀수가 되어야 제대로된 위치를 예측할 수 있기 때문이라고 한다.
-
anchor box를 추가한 실험결과 약간의 mAP 하락이 있었으나 recall은 81%에서 88%로 증가했기에 향상 여지가 있다고 판단했다.
1.1.4 Dimension Clusters
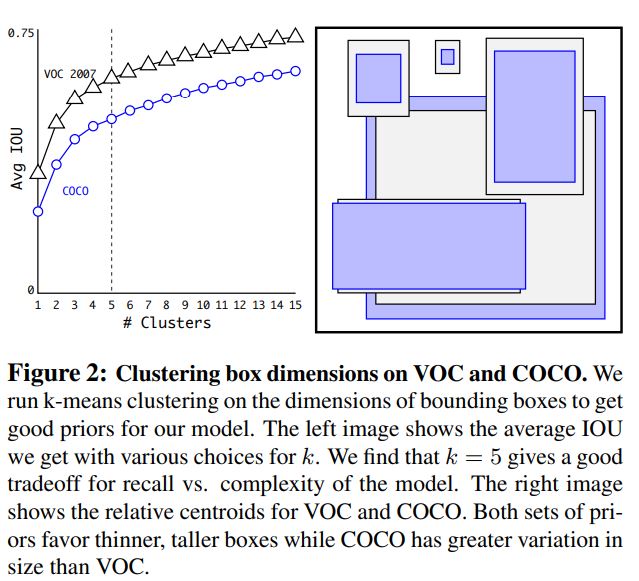
- 적절한 anchor box shape을 찾기 위해 training data로 부터 k-means clustering을 진행하였고 k를 크게 할수록 위 그래프와 같이 anchor box와 ground truth 사이의 평균 IoU가 증가하였지만 complexity를 고려하여 k를 5로 정했으며 anchor box 모양은 오른쪽과 같다.
1.1.5 Direct location prediction
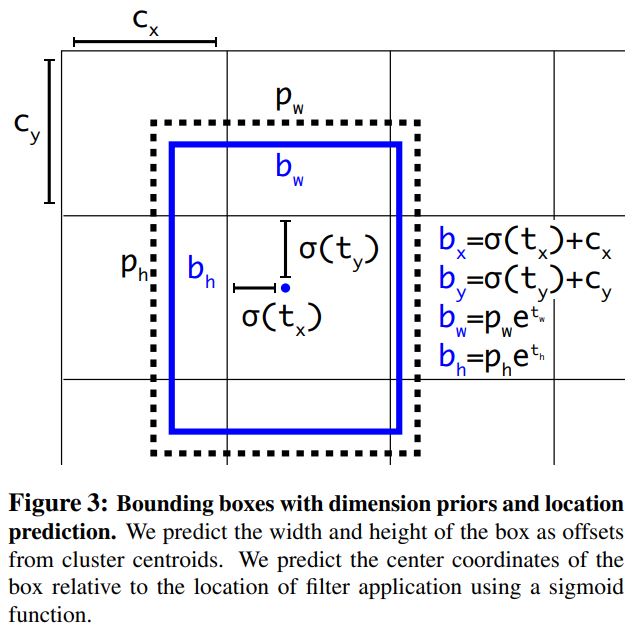
- anchor box 에 대해 bounding box를 예측할 때 제약을 두지 않으면 학습에 어려움이 있기 때문에 논문에서는 anchor box의 중앙이 grid cell 안에 오도록 위 그림과 같이 sigmoid function으로 제약을 주었고 약 5%의 mAP 상승이 있었다고 한다.
1.1.6 Fine-Grained Features
- 마지막 feature map (13x13) 만 사용하여 BB를 예측하면 작은 물체에 대해서는 성능이 좋지않을 수 있기 때문에 중간 layer (26 x26) 를 (13 x 13 x 4) 모양으로 바꾸어 마지막 feature map과 합쳐주었을 때 mAP 가 1% 상승했다.
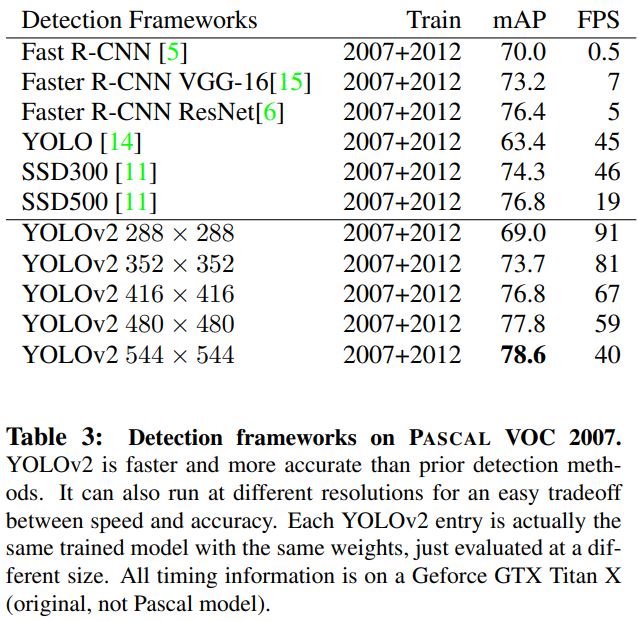
1.1.7 Multi-Scale Training
-
YOLOv2는 Fully conv network 이기 때문에 다양한 input을 받을 수 있으며 320에서 608까지 다양하게 training 하였고 input size에 따라 다음과 같은 결과를 얻었다.
-
228 입력일 때 91FPS를 얻었으며 mAP는 Fast RCNN과 비슷한 수치를 나타낸다.
YOLO9000
1.2 YOLO9000 동작
- YOLO9000은 대중화된 object detection dataset인 MS COCO가 90여개의 class 를 제공하지만 실생활에서는 이보다 훨씬 많은 물체가 존재하고 구분해야될 필요성이 있다. YOLO9000에서는 MS COCO와 ImageNet의 데이터를 결합하여 총 9000개의 class를 detect할 수 있는 방식을 제시하였다.

- 서로 다른 형태의 dataset을 합치기 위해서 위 그림과 같이 word tree 라는 계층구조를 적용하였다. ImageNet에서는 요크셔테리어, 비숑, 말라뮤트 등과 같이 개의 종까지 구분한다면 MS COCO에서는 이것들을 모두 개로 구분하기 때문에 이것을 하나의 개라는 계층으로 묶어주는 것이다.
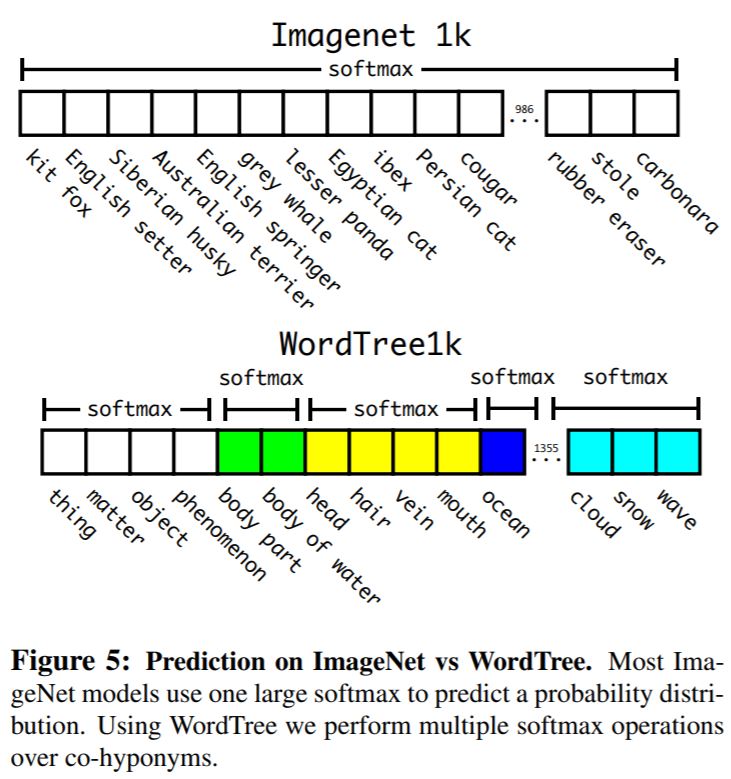
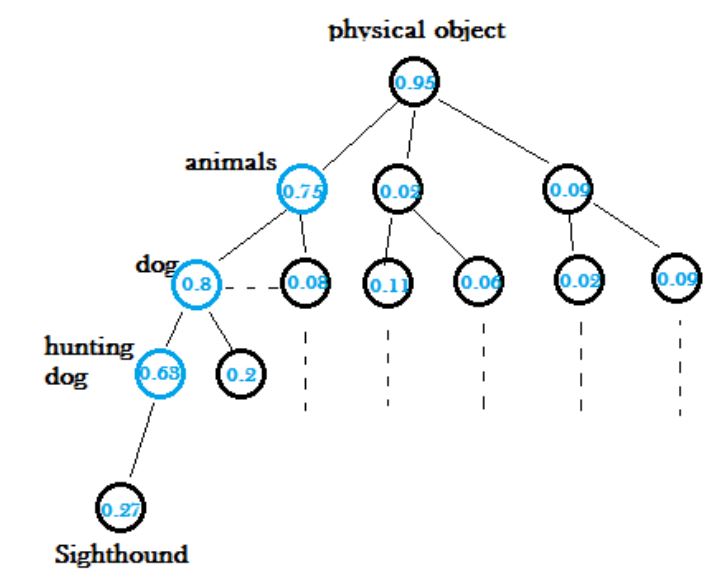
- 이 때 softmax 는 전체 class에 대해서 나오는 것이 아니라 각각의 계층에 대해서 적용된다. 예를 들어 hunting dog 이 있을 때 먼저 물체가 존재할 때 나오는 높은 확률을 따라 hunting dog 까지 내려가며 예측을 하게 되는 것이다. 이 때, hunting dog 밑에도 sighthound라는 결과가 나왔지만 confidence level이 너무 낮기 때문에 hunting dog에서 끝이난다.
2. 결과
2.1 YOLOv2 결과
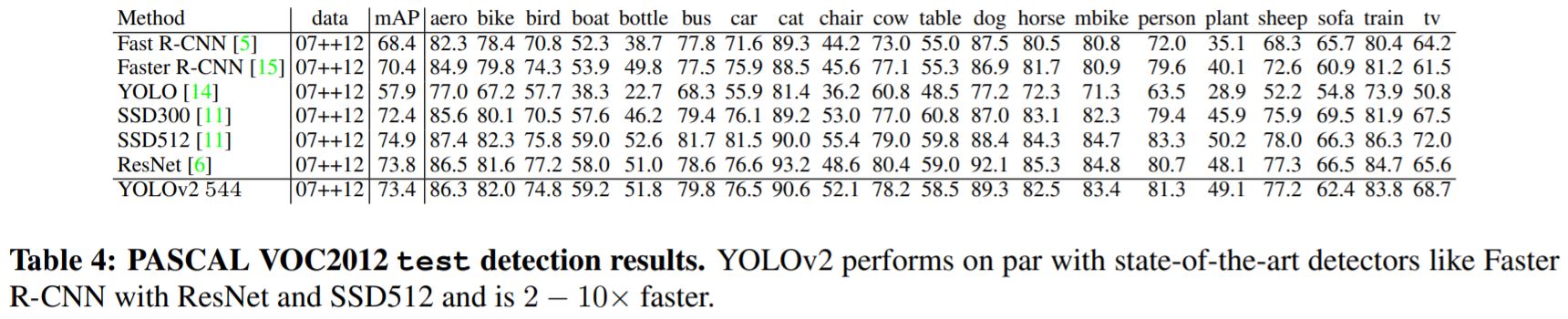
YOLOv2는 Fast RCNN과 Faster RCNN보다 좋은 mAP를 성취했으며 SSD 방식과 비슷한 mAP 를 얻었지만 속도 측면에서는 2-10 배 더 빠른 결과를 나타냈다.
2.2 YOLO9000 결과
YOLO9000 은 test set으로 대부분 classification data를 사용하였고 BB에 대한 정보는 training 되지 않았기 때문에 19.7 mAP로 YOLOv2보다는 낮은 성능을 보였지만 기존 기술인 DPM방식 보다는 좋은 수치라고 한다. 별도의 BB data 없이 9000개의 class에 대해 real time으로 detect 가능하게끔 만들었다는 그 자체에 의의가 있는 것 같다.
Reference
[1]: Deep Learning for Generic Object Detection: A Survey
[2]: YOLOv2
[3]: YOLOv2 설명 블로그
댓글남기기