ML study > Object Detection > One stage detection
DetectorNet
- DetectorNet은 object detection에 CNN을 처음으로 도입한 network 중 하나로 region proposal network 없이 one stage로 동작한다.
1. DetectorNet 동작
-
DetectorNet은 AlexNet을 사용하였고 마지막 layer의 softmax를 regression layer로 바꾸어 bounding box를 예측했다.
-
이과정에서 다음과 같은 문제점이 발생했다고 한다.
1.1 서로 붙어 있는 물체의 경우 하나의 마스크로 구분하기 어렵다.
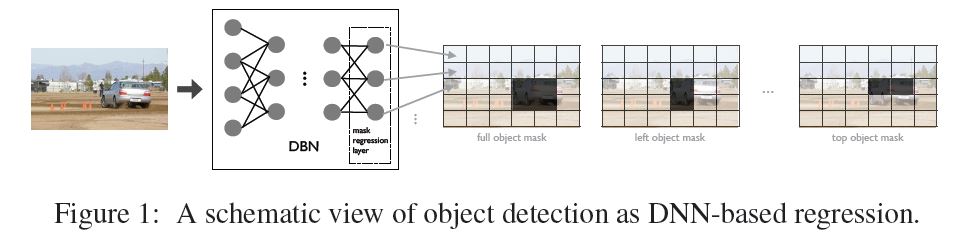
- 이 문제를 해결하기 위해서 저자는 하나의 object를 위 그림처럼 5개의 mask로 나누어 여러개의 network를 구성하여 training 시켰다. 이렇게 되면 서로 옆에 붙어 있는 물체라 하더라도 겹치지 않는 부분의 마스크에서 다른 결과가 나오기 때문에 구분이 가능하다.
1.2 크기가 작은 물체의 경우 detect하기 어렵다.
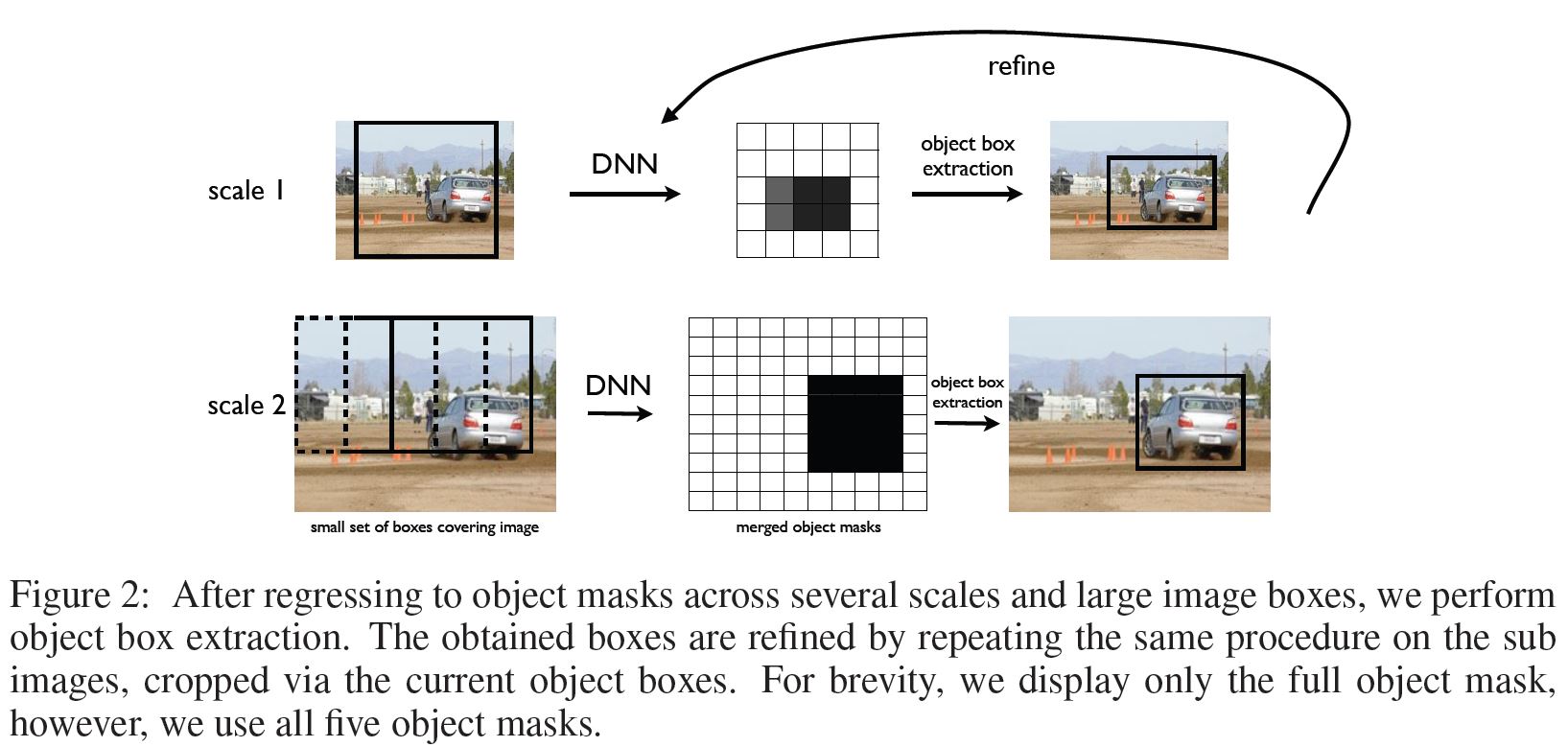
- 다양한 크기의 물체를 detect 하기 위해 이미지의 스케일을 다르게 한 뒤 40개 미만의 window로 잘라내고 DNN에 통과시켜 mask를 output으로 내도록 만들었다. 이렇게 스케일마다 나온 mask를 가지고 bounding box inference 과정을 거쳐 나온 후보군을 동일한 network에 넣어 한번 더 refine 하는 과정을 거쳐 최종 bounding box를 예측한다.
** bounding box inference 과정은 예측한 mask와 BB가 얼마나 일치하는지를 점수로 표현하는 방식으로 논문에 구체적인 방법이 나와있으니 참고 바란다.
- 다음은 위과정을 요약한 알고리즘이다.

- 논문에서는 scale 당 score가 높은 5개의 detection을 가져왔으며 3개의 scale을 사용하여 하나의 이미지당 15개의 BB를 얻었다고 하며 refinement를 거친 후 가장 높은 score의 BB를 선택했다고 한다.
2. DetectorNet 결과
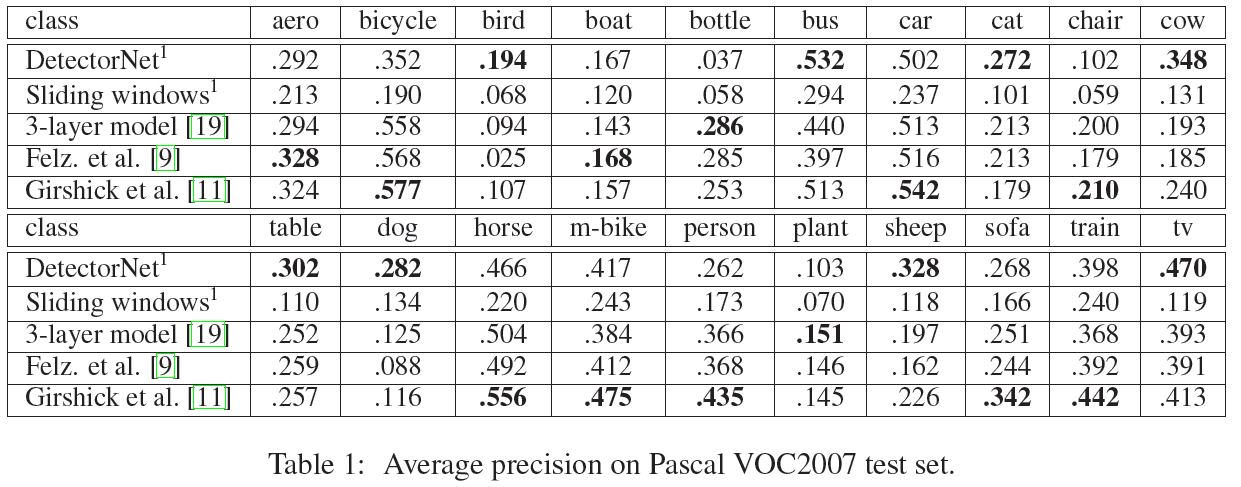
Object Detection에 처음으로 CNN을 적용시켰다는 점에 의의가 있지만 mAP 성능이 PASCAL VOC 데이터 기준으로 30.5 정도가 나왔으며 이후 나온 RCNN(54.2) 보다 매우 좋지 못하다. Predict 시 이미지당 5~6 초 소요되어 real time 구동으로 적합하지 않으며 object와 mask type 마다 network를 training 시켜주어야 해서 매우 비효율적이라고 할 수 있다.
Reference
[1]: Deep Learning for Generic Object Detection: A Survey
[2]: DetectorNet
댓글남기기