ML study > Reinforcement Learning > Dynamic Programming
1. Dynamic Programming 이란?
- Dynamic Programming (DP) 이란 복잡한 문제를 작은 문제로 나눈 후 작은 문제의 해법을 조합해 큰 문제의 해답을 구하는 기법을 말한다. 따라서 한 번에 계산하기 어려움 bellman expectation equation과 bellman optimality equation의 경우 일반적으로 이 DP를 통해 계산할 수 있다.
2. Value Iteration
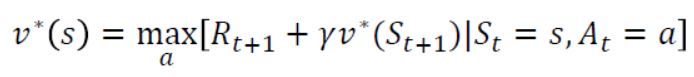
- 먼저 우리가 이전 post에서 유도한 bellman optimality equation을 통해 해를 구하는 방법을 알아보자.

- 처음 v(s)는 0에서 시작할 것이다. 이 때 vk+1을 bellman optimality equation을 통해 update해 나가면 조금 조금씩 v(s) 가 optimal 한 값에 가까워지며 결국은 수렴하여 v*(s) 값을 구할 수 있게 된다. 이러한 반복과정을 우리는 value iteration 이라 부른다.
3. Policy Iteration

- 이번에는 위 수식과 같이 bellman expectation equation을 통해 해를 구하는 방법을 알아보자. Policy Iteration의 경우 bellman optimality equation을 사용한 value iteration과는 다르게 최적일 때의 수식을 사용하지 않으므로 한 번에 얻은 수렴값으로 최적의 정책을 구할 수 없고 evaluation 과정과 improvement 과정을 반복하여야 한다.
3.1 Policy evaluation

- Policy evaluation은 어떤 정책이 주어져 있을 때 그 정책을 따라 bellman expectation equation을 거쳐 수렴할 때까지 update하는 과정이다. 수식으로 나타내면 위와 같으며 수렴이 되었을 때의 value function이 주어진 정책에 대해 평가된 값이라고 할 수 있다.
3.2 Policy improvement

-
정책에 대한 평가가 끝난 뒤에는 그 가치함수를 통해 가장 큰 q함수를 만들어내는 action값을 선택하도록 정책을 update 시킨다.
-
이 때 새롭게 update되는 정책은 이전의 정책보다 좋은 정책이 되는데 그 이유는 위와 같다. 처음 계산하는 value function은 하나의 행동을 정책 𝜋에 따라 100% 선택하기 때문에 Q 함수값과 동일하게 된다. 이 때 그 Q함수를 최대로 하는 action을 선택하는 정책을 𝜋’라고 한다면 당연히 더 큰 값을 나타내게 될 것이다.
-
결국 policy iteration (policy evaluation + policy improvement) 과정을 거치면 조금씩 optimal한 value function값으로 가까워지게 되며 수렴할 때의 value function값이 optimal한 값이라고 할 수 있다.
Reference
[1]: Reinforcement learning: an introduction
[2]: Fundamental of Reinforcement Learning
[3]: Fast Campus 강의자료
댓글남기기